Muy bien como lo explicamos en el post anterior Novedades Clave de vSphere 8.0 GA: Mejoras y Funcionalidades En esta oportunidad hablaremos solo de las características que fueron incluidas en vSphere 8.0 U1 y. Recordemos que el objetivo final de esta serie de post de novedades de vSphere es tener una visión general de la evolución del producto hasta la fecha. Y estar preparados para la actualización de vSphere 9.0 que ya fue liberada.
Continuando con nuestro camino de adopción de la solución vSphere, componente principal de VMware Cloud Foundation, en este artículo recordaremos las nuevas funciones y mejoras que vSphere 8 Update 1 trajo consigo el 18 de Abril de 2023, mejorando la eficiencia operativa, elevando la seguridad y potenciando las cargas de trabajo.
Podemos categorizar las mejoras de vSphere en tres temas principales:
Administración Eficientemente: Hacer que sea más fácil para los clientes operar sus infraestructuras de TI de la manera más eficiente posible.
Seguridad: Cada función se convierte en una característica de seguridad, lo que permite a los equipos de TI centrarse en ser seguros en lugar de solo asegurar.
Potenciar Cargas de Trabajo: Introducir soporte para nuevas tecnologías de hardware, como GPUs y DPUs.
Administración Eficientemente
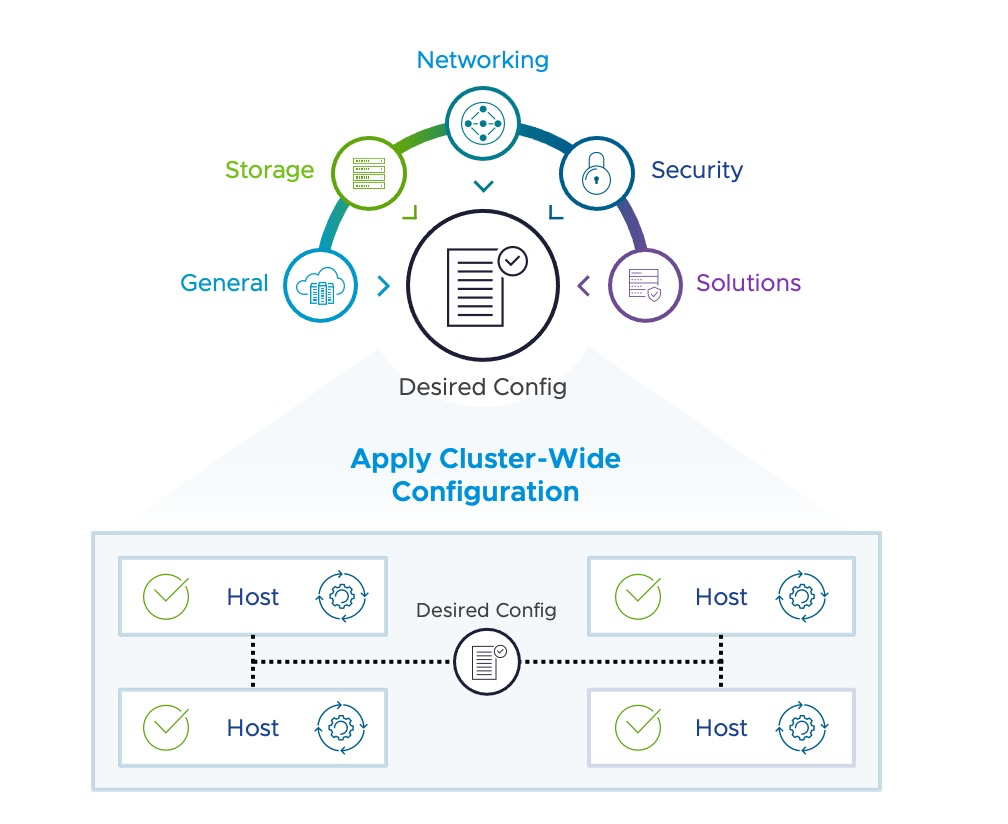
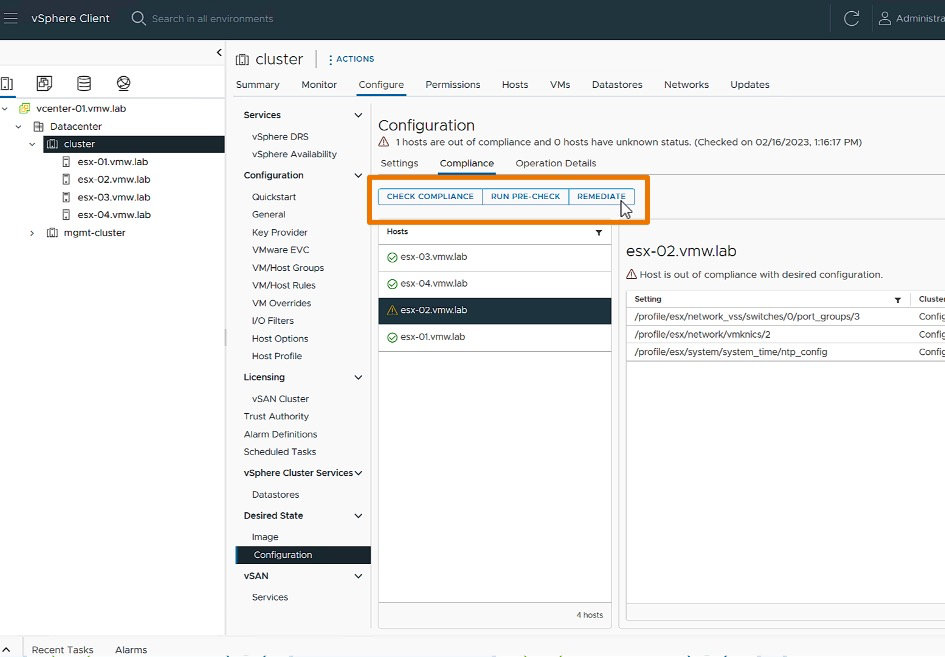
vSphere Configuration Profile
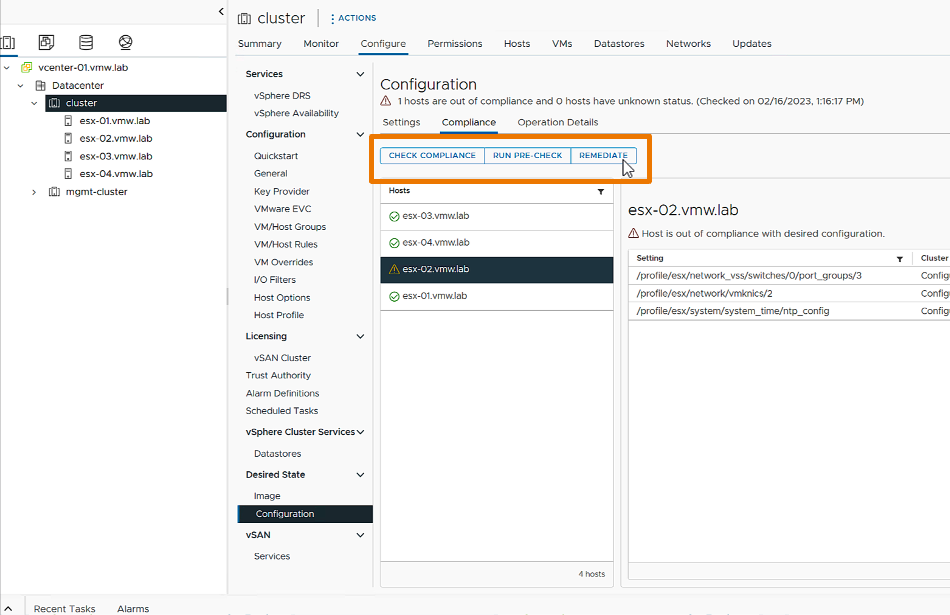
Comenzamos con los vSphere Configuration Profile, que facilitan la gestión de la configuración del clúster. Esta nueva función permite a los administradores establecer configuraciones deseadas a nivel de clúster en formato JSON, verificar la conformidad de los hosts y remediar cualquier incumplimiento.
Si bien esta funcionalidad fue introducida en vSphere 8.0 GA como Tech Preview, en vSphere 8 Update 1 comenzó a ser completamente soportada. Permitiendo la configuración de vSphere Distributed Switch que no estaba disponible en la version anterior.
vSphere Lifecycle Manager (vLCM)
Además, se mejoró el vSphere Lifecycle Manager (vLCM) para admitir hosts standalone. Esto incluyó la capacidad de definir imágenes personalizadas y gestionar hosts en ubicaciones remotas con conectividad limitada. Desde esta versión todo lo que se espera de vLCM esta disponible para hosts Standalone.
Flexibilidad en Cargas de Trabajo de GPU
Con vSphere 8 Update 1, ahora se pueden asignar diferentes perfiles de GPU a diferentes cargas de trabajo en la misma máquina. Esto permite a los administradores maximizar la utilización de recursos de GPU.
Mejoras en vSphere con Tanzu
Se han realizado mejoras significativas en la integración de Tanzu Supervisor Services, permitiendo su uso con vSphere Distributed Switch, lo que facilita su implementación y gestión.
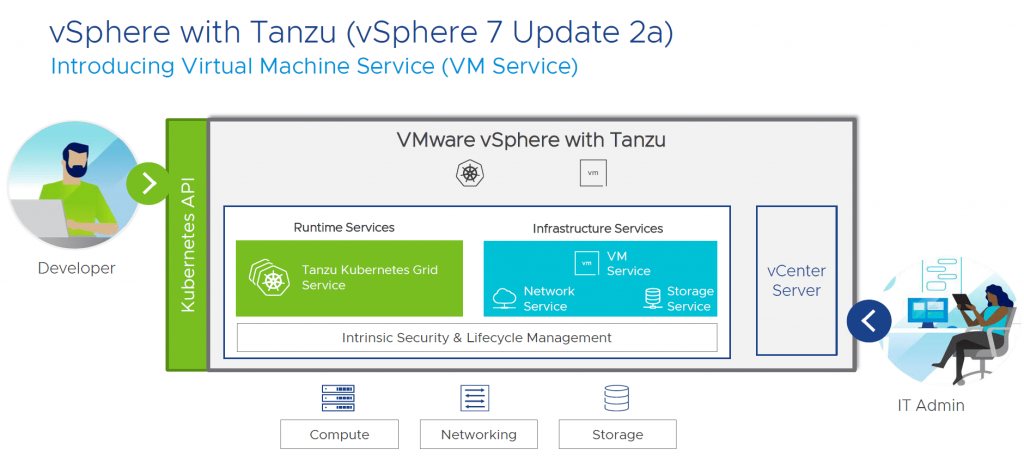
Como parte de las mejoras incorporadas al entonces vSphere with Tanzu, se añadieron nuevas funcionalidad al vSphere Virtual Machine Service (VM Service), incluido en la versión vSphere 7 Update 2a , y que básicamente permite implementar y gestionar Virtual Machines mediante las API estándar de Kubernetes, al mismo tiempo que permite al administrador de TI controlar el consumo de recursos y la disponibilidad del servicio. Si quiere saber un poco más de VM Service lo invito a leer este corto articulo Introducing the vSphere Virtual Machine Service escrito por Glen Simon.
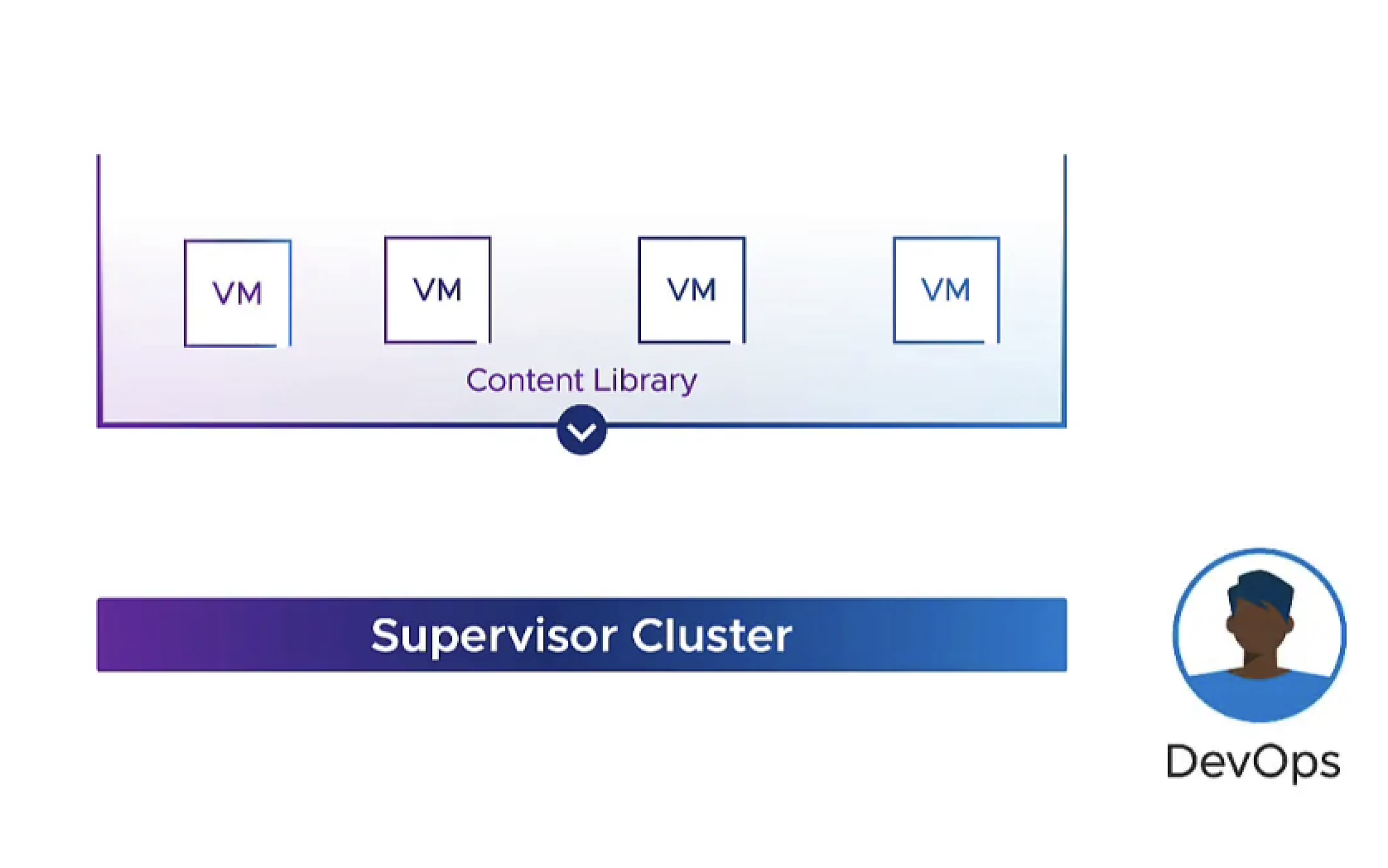
Como parte de esas mejoras al VM service el equipo de DevOps ahora puede traer tu propia imagen, lo que permite a los usuarios crear imágenes que se pueden almacenar en una biblioteca de contenido.
Adicionalmente, los desarrolladores pueden ahora lanzar la consola de las VMs utilizando el comando kubectl sin necesidad de tener acceso al vCenter Server.
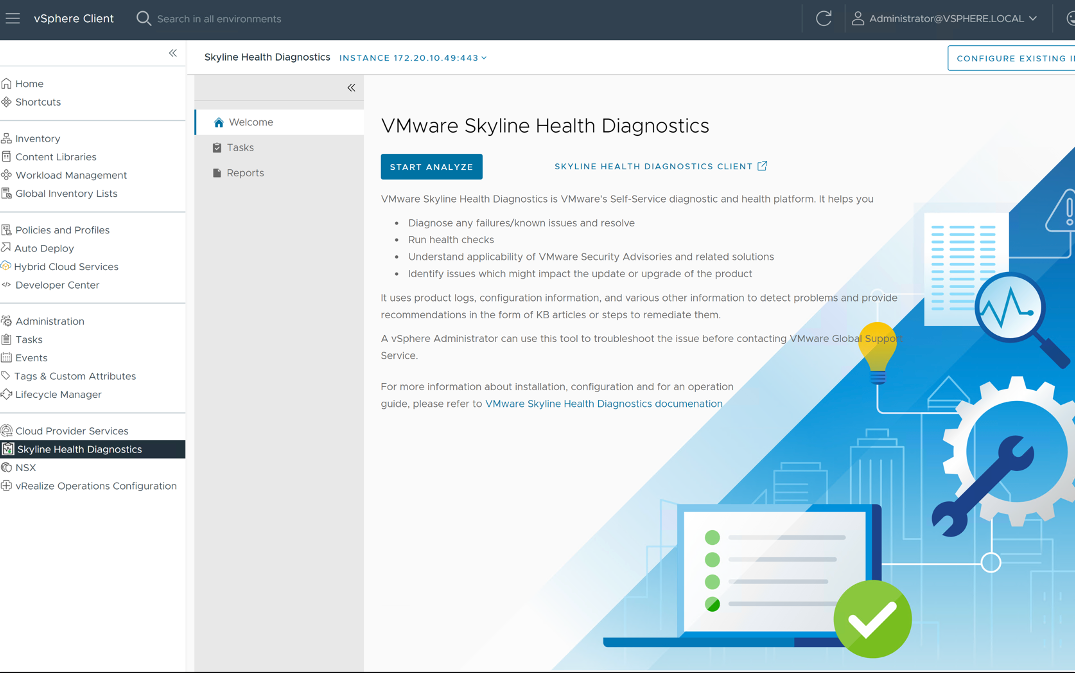
Por si esto fuera poco, vSphere 8 Update 1 introdujo un workflow en el vSphere Client para desplegar y registrar el Skyline Health Diagnostics y de esta manera registrarlo facilmente con vCenter.
Mejoras en Seguridad
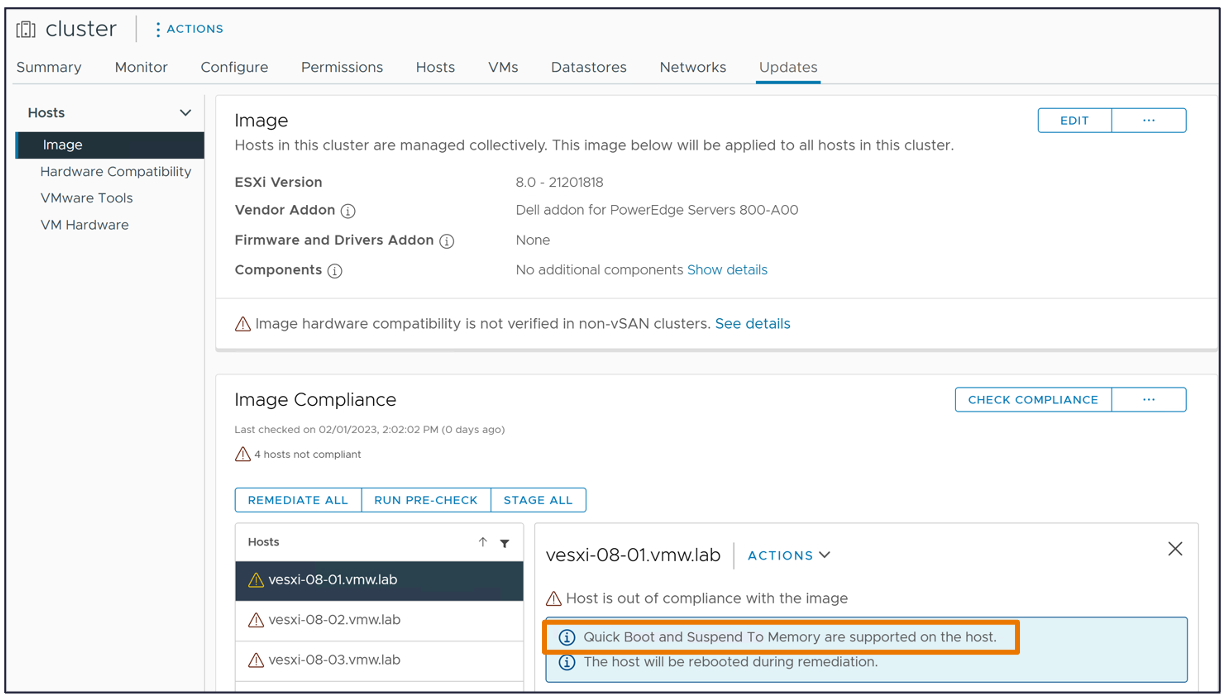
La seguridad es una prioridad constante. En vSphere 8 Update 1, se ha abordado la compatibilidad entre ESXi Quick Boot (introducido en vSphere 6.7) y TPM 2.0, permitiendo un reinicio rápido sin comprometer la seguridad.
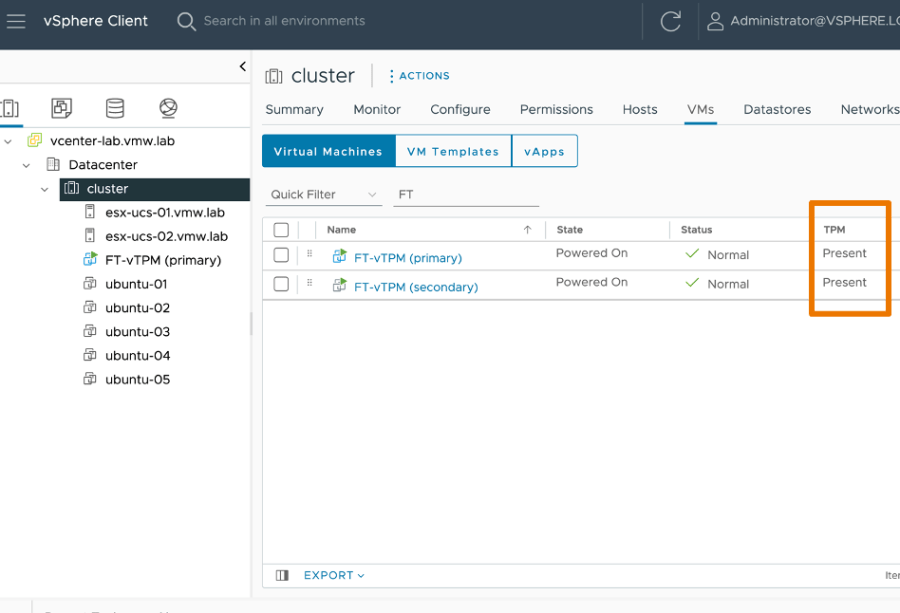
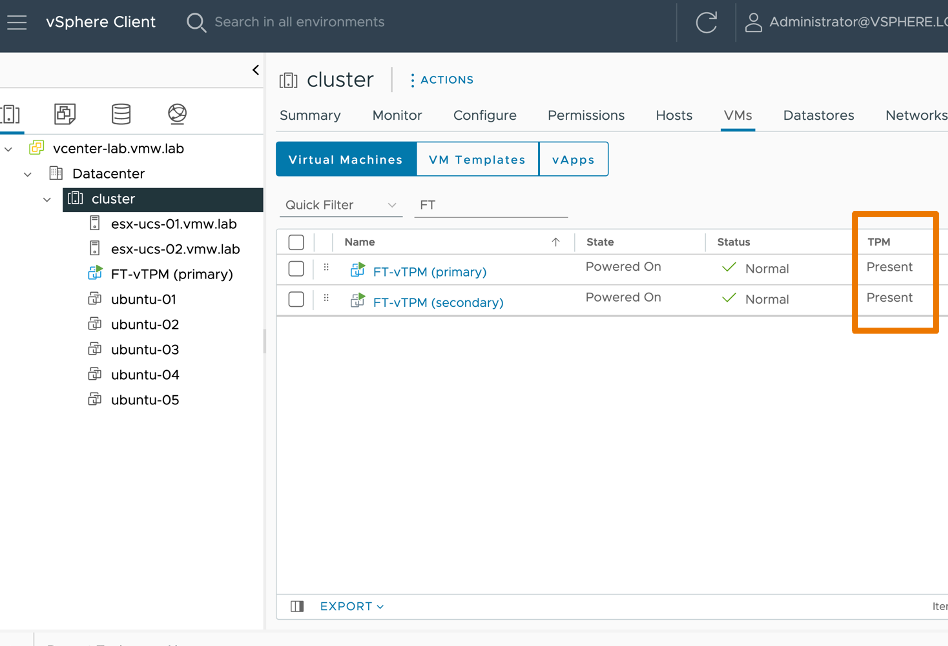
También se ha mejorado el soporte para vTPM, permitiendo que las máquinas virtuales protegidas con vTPM sean totalmente tolerantes a fallos, es decir que podamos protegerlas con Fault Tolerance.
Identidad y Autenticación
Se introdujo soporte para el proveedor de identidad Okta, lo que permite una gestión más moderna de identidades y autenticación multifactor. Esto se alinea con las mejores prácticas de seguridad actuales. Lo mejor es que no se require el uso de ADFS, nos permite introducir 2FA/MFA y además nos permite tener un Single Sing-On consistente dentro de la organización.
Potenciar Cargas de Trabajo
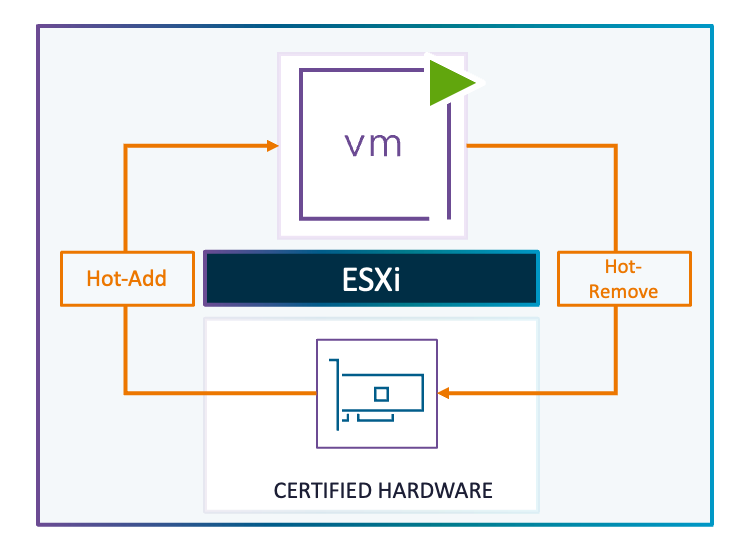
Hemos realizado importantes mejoras en VM DirectPath I/O, permitiendo la adición y eliminación en caliente de dispositivos NVMe, usando APIs, lo que reduce el tiempo de inactividad de la carga de trabajo.
Además, se extendió el soporte para la tecnología NVIDIA NVSwitch, que permite una comunicación de alta velocidad entre múltiples GPUs, llegando hasta 900 GB/s, lo que es crucial para aplicaciones de inteligencia artificial y computación de alto rendimiento. En esta versión (vSphere 8.0 U1) podíamos conectar hasta 8 GPUs en un Switch NVIDIA usando el protocolo NVLink
Conclusión
Estas mejoras en vSphere 8 Update 1 no solo mejoraron la eficiencia operativa y la seguridad, sino que también permitieron a los clientes aprovechar al máximo sus cargas de trabajo. Para más información y recursos adicionales, visita el Centro de Recursos de VMware.
¡Gracias por tu atención y espero que encuentres útiles estas nuevas características que fueron lanzadas hace un tiempo pero que probablemente no sabías, no recordabas o nunca habías escuchado hablar de ellas! No vemos en el vSphere 8 Update 2 y Update 3 para completar este path de adopción de la tecnología vSphere.
Recursos
¡IMPORTANTE! He migrado blog del dominio nachoaprendevirtualizacion.com a nachoaprendeit.com. Si te ha servido este artículo deja tu buen Like y compártelo con tus colegas, estas aciones me ayudarán a optimizar los motores de búsqueda para llegar a más personas, y a motivarme a seguir compartiendo este tipo de artículos.
TODOS LOS NOMBRES DE VMS USADOS EN ESTE BLOG SON INVENTADOS Y OBEDECEN A UN AMBIENTE DE LABORATORIO PROPIO, UTILIZADO PARA FINES DE ESTUDIO.
¡Bienvenidos a esta serie post con visión técnica de lo nuevo que ha venido incorporando vSphere en los últimos años!
¿POR QUÉ AHORA?
Si bien esta información salió hace algunos años, en el campo me he dado cuenta que muchos de nuestros cliente siguen usando vSphere en sus versiones 8.x sin saber que funcionalidades se han incluido.
Ya esta disponible VCF 9.0 y con el nuevas funcionalidades para vSphere 9.0, pero antes de llegar allá enfoquémonos en lo que la mayoria de nuestros clientes tienen actualmente y en cómo podemos ayudarlos a sacarle el mayor provecho a su infraestructura. Así que con el fin de mejorar la adopción de VMware Cloud Foundation en nuestros clientes, partners y comunidad en general, he decidido crear una serie de blogs, donde resumiremos las mejoras incorporadas en cada uno los lanzamientos de las productos que componen la solución de VCF.
Ahora, teniendo en cuenta que vSphere es el Core, comenzaremos por aquí. En este blog, exploraremos de forma muy resumida las características más destacadas y las mejoras que vSphere 8.0 GA trajo a la mesa hace un par de años (2022/10/11).
Para no hacer este blog tan largo, explicaremos solo lo correspondiente a vSphere 8.0 GA y en las siguiente entradas, hablaremos de las características que se han venido incorporando con el lanzamiento de cada uno de los updates. Esto con el objetivo de tener al final una visión general de la evolución del producto hasta la fecha. ¡Así que vamos a sumergirnos en el contenido!
vSphere Distributed Service Engine
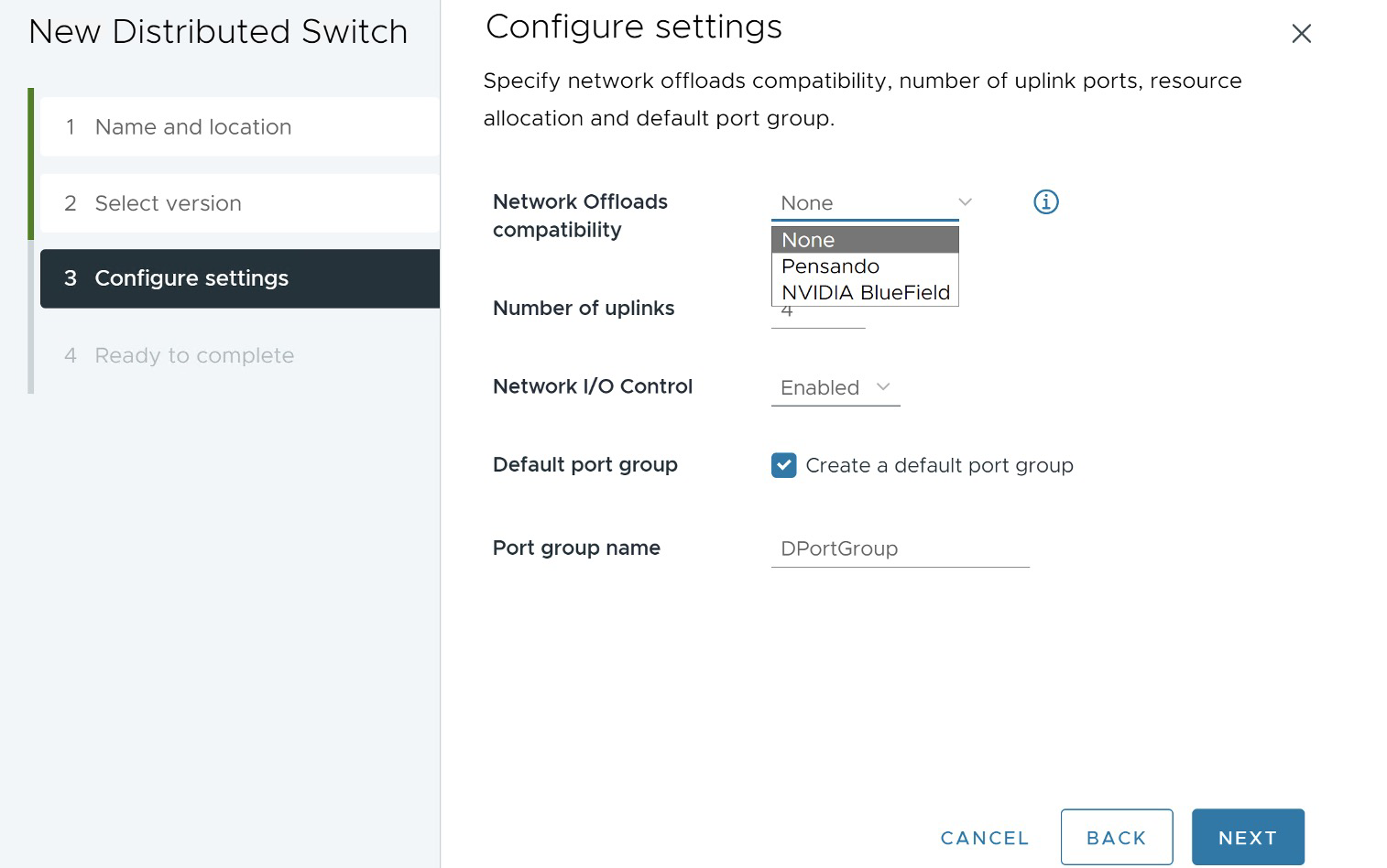
Comencemos hablando sobre el vSphere Distributed Services Engine, que nació como Proyecto Monterey. Este motor ha evolucionado y se lanzó con vSphere 8.0 GA, permitiendo mover funcionalidades desde el host hacia una Data Processing Unit (DPU) o unidad de procesamiento de Datos. Su principal objetivo es desbloquear el poder de las Data Processing Unit (DPU) para el procesamiento de datos acelerado por hardware, lo que ofrece una mejora en el rendimiento de la infraestructura. Ahora, usar estas DPU en tus cargas de trabajo es más sencillo que nunca.
Pero, ¿qué es una DPU? Es un dispositivo similar a un dispositivo PCIe como una NIC o una GPU, que reside en la capa de hardware. Contiene cierta capacidad de cómputo, almacenamiento, memoria y tiene interfaces de red, por lo que se le conoce también como SmartNIC porque Incluye un procesador ARM, 16-32GB RAM, high speed ethernet de 10GB a 100 GB, interfaz de Management de 1GB, y Sensores. Lo interesante aquí es que hasta el lanzamiento de vSphere 8.0 GA, nuestros servicios de red, almacenamiento y gestión de hosts funcionaban únicamente en una instancia de ESXi x86, virtualizando la capa de cómputo. Con vSphere 8.0 GA, se agregó una instancia adicional de ESXi directamente en la DPU, lo que permite descargar servicios de ESXi hacia este dispositivo, comenzando con algunos servicios de red y seguridad de NSX, aumentando así el rendimiento de la plataforma. Se espera que en futuros releases, se amplíe el soporte para la descarga de más funcionalidad hacia el dispositivo DPU. Clic en el siguiente enlace obtener más información acerca de ESXi Installation on DPU
Nota: Hasta esta versión vSphere 8.0 GA, solo estaban soportados de tipos de DPU, NVIDIA y Pensando. Pero como veremos en los siguientes post asociados a los Updates de vSphere 8.0, nuevos modelos y partners se han unido a la fiesta!
Esto libera parte del poder de cómputo x86 y lo devuelve a nuestras aplicaciones y cargas de trabajo. Para aprovechar el vSphere Distributed Services Engine, necesitas utilizar un Switch Distribuido de vSphere versión 8 y NSX. Esto te permitirá seleccionar la compatibilidad de descarga de red y elegir la DPU adecuada en tu entorno.
Mejoras en vSphere con Tanzu
Pasemos ahora a las mejoras en vSphere con Tanzu. Introducido en vSphere 7, vSphere con Tanzu trajo consigo Tanzu Kubernetes Grid (TKG) y varias versiones. Con vSphere 8, se consolidaron estas diferentes versiones en un único runtime de Kubernetes unificado, que se utiliza para desplegar Kubernetes en clústeres de vSphere, nubes públicas y privadas.
Una nueva característica en vSphere 8.0 GA es el concepto de vSphere Zones. Esto se utiliza para aislar cargas de trabajo a través de clústeres de vSphere y permite que se extiendan o abarquen múltiples clústeres para maximizar la disponibilidad y el consumo de recursos, evitando a su vez que tengamos un único punto de falla a nivel del vSphere Cluster que soporta la solución de vSphere with Tazu.
Por otro lado, incorporamos el concepto de ClusterClass en VMware vSphere with Tanzu, que no es más que una forma declarativa de, especificar la configuración y gestionar el ciclo de vida de clústeres de Kubernetes a través de un cluster de gestión de Kubernetes que, para vSphere with Tanzu, es conocido como Supervisor Cluster. Utilizando esta nueva funcionalidad podemos incluso decidir los paquetes de infraestructura que se deben instalar al crear el clúster. El ClusterClass puede incluir especificaciones asociadas a proveedores de red, almacenamiento y nube, así como el mecanismo de autenticación y la recopilación de métricas. De esta manera podemos definirlo una vez y aplicarlo múltiples veces.
Nota: Las imágenes de Photon OS y Ubuntu ahora se pueden personalizar y guardar de nuevo en la Content Library para su uso en clústeres de Kubernetes de Tanzu. También se integró la autenticación de Pinniped tanto en el Supervisor Cluster como en los clústeres TKG para la gestión de identidades federadas.
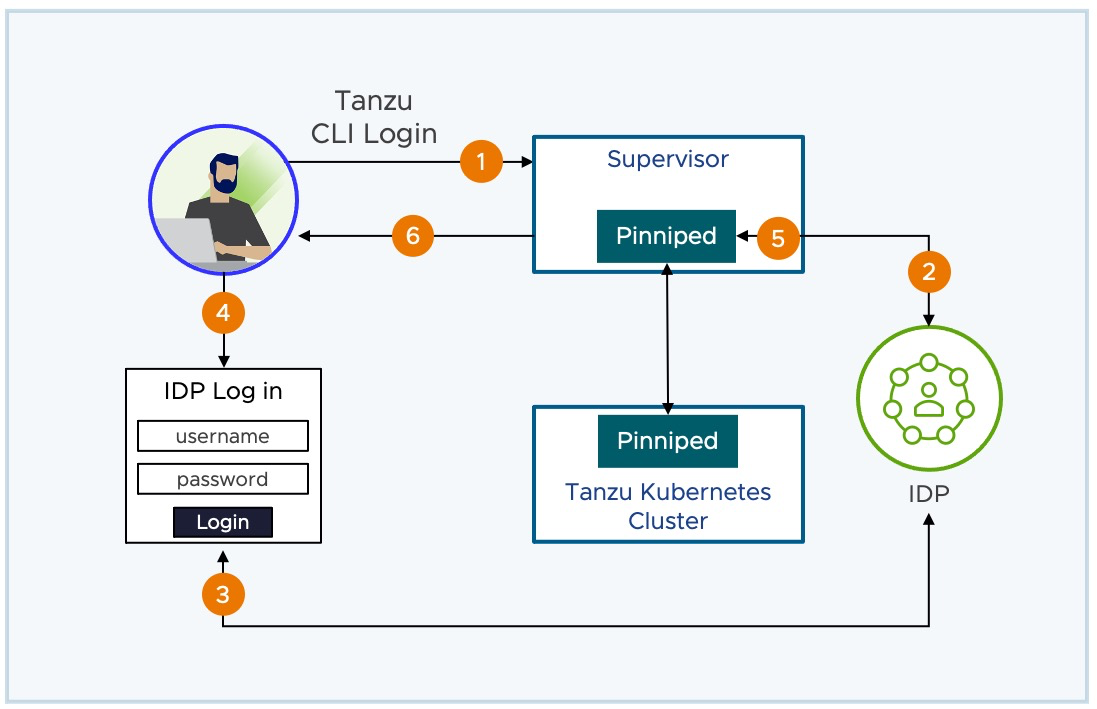
Autenticación Federada con Pinniped
En vSphere 7, toda la autenticación se realizaba a través de la integración con vCenter SSO. En vSphere 8.0 GA, tienes una alternativa: la integración con Pinniped. Esta integración permite que el Supervisor Cluster y los clústeres de Kubernetes de Tanzu accedan directamente a un proveedor de identidad OIDC(OpenID Connect), sin depender de vCenter SSO. Los pods de Pinniped se despliegan automáticamente en el Supervisor Cluster y en los clústeres de Tanzu para admitir esta funcionalidad.
Gestión del Ciclo de Vida
Ahora veamos la gestión del ciclo de vida. vSphere Lifecycle Manager (vLCM) ha mejorado, permitiendo la remediación paralela de hosts, lo que reduce el tiempo total de operación. Recordemos que al remediar un host ESXi que contiene una DPU, también hay un evento de remediación la instancia de ESXi que existe en el dispositivo DPU. La buena noticia es que vSphere Lifecycle Manager Images es consciente de eso, por lo que no tienes nada de que preocuparte a nivel de la gestion del ciclo de vida de dicha instancia de ESXi.
Tambien se introdujo el soporte de staging en vSphere Lifecycle manager Images y la remediación paralela, lo que mejora el tiempo total de remediación al realizar operaciones de ciclo de vida en tus clústeres de vSphere.
Nota: Es importante mencionar que la gestión de actualizaciones de baselines está obsoleta en vSphere 8.0, lo que significa que debes comenzar a migrar a un enfoque declarativo basado en Images (vSphere Lifecycle Manager Images).
Por otro lado, a nivel del vCenter Server, redujimos los problemas que habían durante el proceso de recuperación. En esta versión el vCenter concilia el estado del clúster, después de una restauración a partir de una copia de seguridad, contra un nuevo componente llamado Distributed Key-Value Store que se aloja en los hosts ESXi de un clúster, y almacena el estado y la configuración del clúster, y ahora es considerado por el vCenter como la fuente de información veraz para el estado y la configuración de los clústers de vSphere. De esta manera los cambios realizados después de la ejecución del backup del vCenter, no seperderán ni generarán errores en caso de una restauraciónn sino queserán conciliados con el Distributed Key-Value Store para que el vCenter pueda actualizar su base de datos utilizando dicha información.
Ademas, en esta version se introdujo una nueva vista previa técnica de los vSphere Configuration Profiles, que será nuestra próxima generación de gestión de configuración de clústeres, podriamos decir que es la evolución de los Host Profiles.
Nota: En la version vSphere 8.0 GA, la gestión de Images desde vSphere Lifecycle Manager para un host standalone se podia realizar a través de las API unicamente. Sin embargo, es importante mencionar vSphere Lifecycle Manager Baselines, también conocida como Update Manager, está en proceso de obsolecencia en vSphere 8.x.
Inteligencia Artificial y Aprendizaje Automático
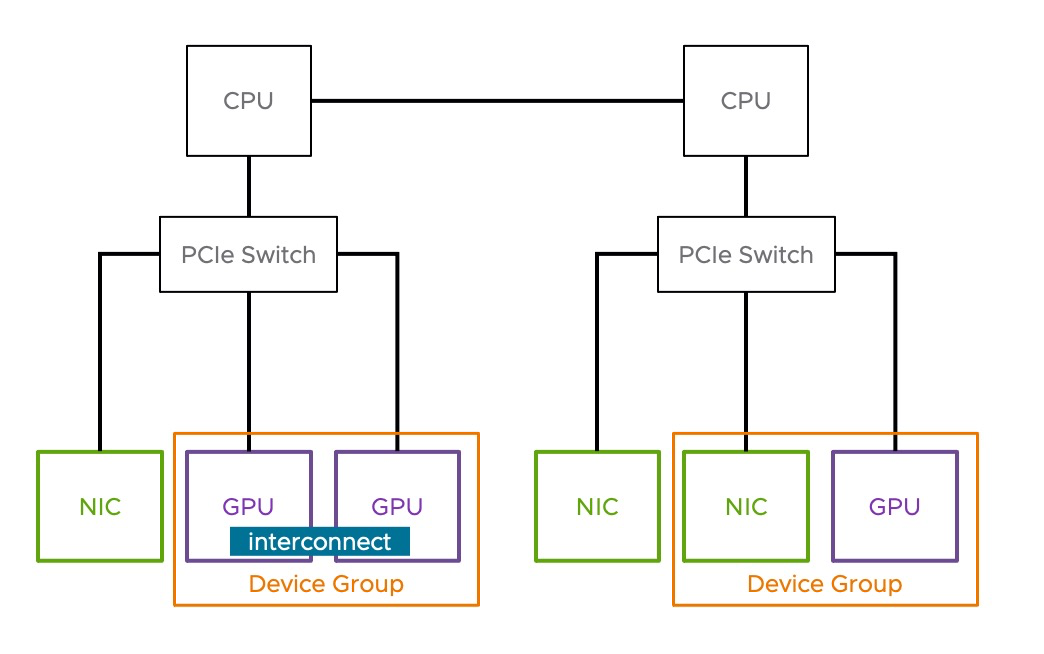
En cuanto a la inteligencia artificial y el aprendizaje automático, estas áreas están creciendo rápidamente y requieren hardware acelerado, típicamente en forma de GPUs. vSphere ofrece ahora la posibilidad de soportar Device Groups, que es una configuración realizada en la capa del hardware, que permite definir dispositivos PCI comunes GPUs y NICs que hacen parte de un mismo PCIe Switch. Esto simplifica la asignación de dispositivos a máquinas virtuales, ya que los dispositivos se presentan como una unidad única a nivel de la capa de virtualización.
Nota: Uno de nuestros primeros partners en apoyar los Device Groups es NVIDIA, que lanzó un controlador compatible para esta funcionalidad. Esto permite a DRS y vSphere HA trabajar con Device Groups para la colocación de máquinas virtuales y la recuperación ante fallos.
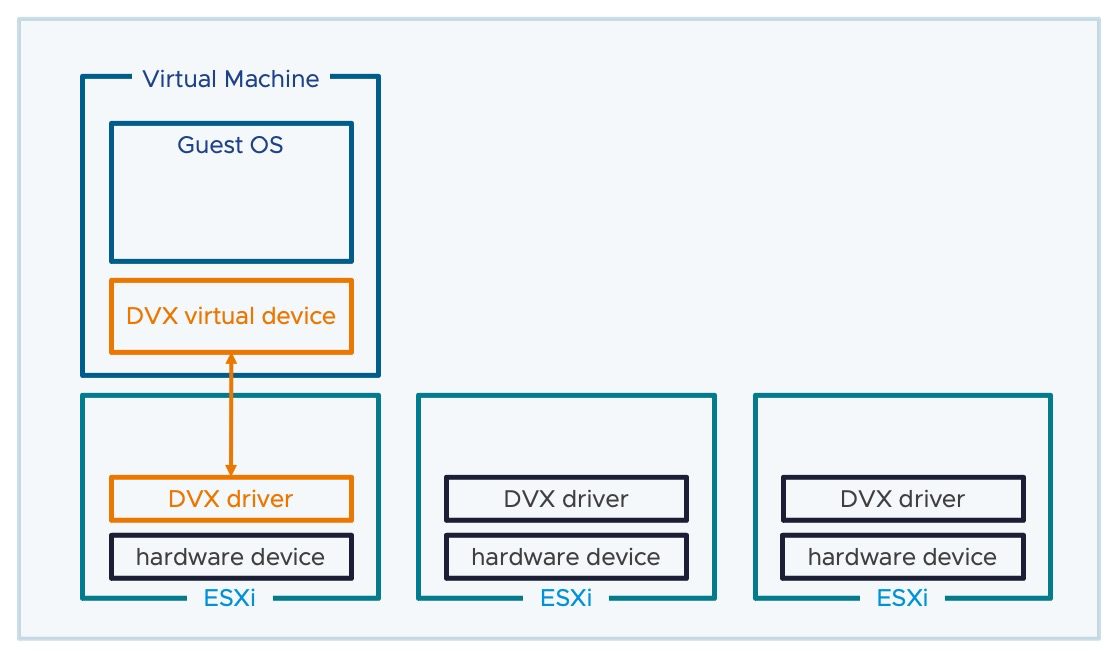
En versiones anteriores, las máquinas virtuales que consumían dispositivos de hardware físico mediante DirectPath IO o Dynamic DirectPath IO tenían una movilidad limitada. En vSphere 8.0 GA, se ha resuelto este problema con Enhanced DirectPath I/O (Device Virtualization Extension) el cual se basa en Dynamic DirectPath IO e introduce un nuevo marco y API para que los proveedores creen dispositivos virtuales respaldados por hardware para permitir una mayor compatibilidad con funciones de virtualización, como la migración mediante vSphere vMotion, la suspensión y reanudación de una máquina virtual y la compatibilidad con instantáneas de disco y memoria. Ahora la mobilidad esta parmitida gracias a un drive instalado tanto en el Guest OS como en el hipervisor.
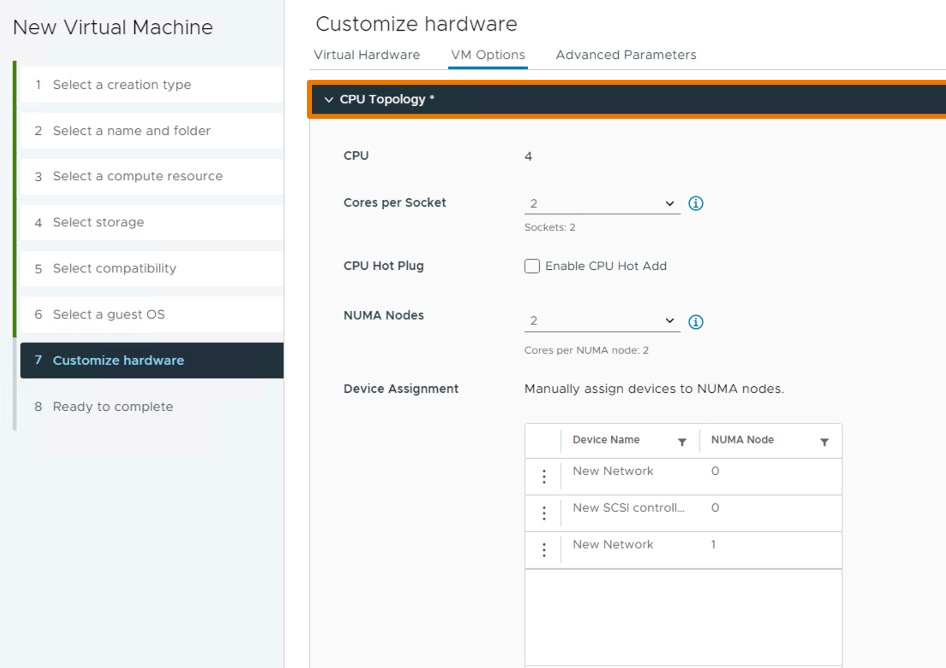
Mejoras en el Sistema Operativo Invitado y Cargas de Trabajo
En esta sección, exploraremos algunas mejoras en el sistema operativo invitado y las cargas de trabajo. Cada nueva versión de vSphere introduce una nueva versión de hardware virtual, y en esta ocasión, hemos llegado a la versión 20. Esto permite aumentos en los máximos de cómputo y desbloquea muchas características nuevas.
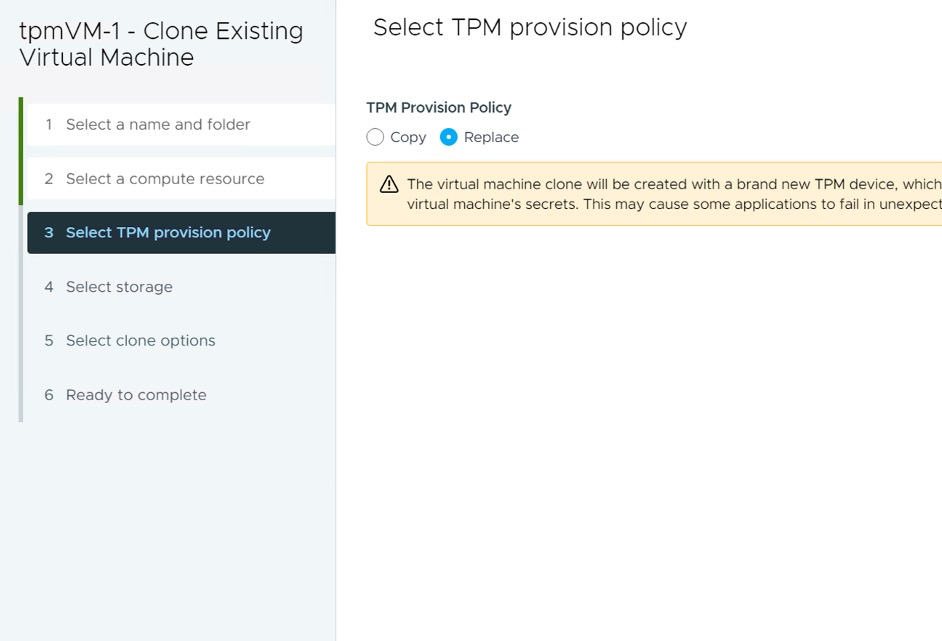
Una de las nuevas políticas es la provisión de TPM virtual, diseñada para ayudar a implementar cargas de trabajo de Windows 11 a gran escala. En vSphere 8.0 GA, los dispositivos vTPM se pueden reemplazar automáticamente durante las operaciones de clonación o implementación. Esto permite seguir las prácticas recomendadas de que cada máquina virtual contenga un dispositivo TPM único.
Además, estamos simplificando la configuración de vNUMA y aumentando los máximos de cómputo, permitiendo hasta ocho dispositivos vGPU por máquina virtual.
Notificaciones de vMotion
También estamos introduciendo las notificaciones de vMotion, que permiten que las máquinas virtuales sean conscientes de los eventos de vMotion, lo que es crucial para aplicaciones sensibles a la latencia. Esto permite que las aplicaciones realicen trabajos previos de preparación a la migración, como detener servicios o hacer failover de manera controlada.
Nota: Las aplicaciones se debe ser reescritas para que admitan las notificaciones de vMotion. O se puede escribir una aplicación asociada como intermediaria entre las notificaciones de vMotion y la aplicación principal.
Gestión de Recursos y Sostenibilidad
En el ámbito de la gestión de recursos, se mejora el rendimiento de DRS mediante un mejor aprovechamiento de las estadísticas de memoria que fueron introducidas en vSphere 7U3. vSphere Memory Monitoring and Remediation (vMMR) ayuda a cubrir la necesidad de monitoreo al proporcionar estadísticas de ejecución tanto a nivel de VM (ancho de banda) como de Host (ancho de banda, tasas de errores). vMMR también proporciona alertas predeterminadas y la capacidad de configurar alertas personalizadas basadas en las cargas de trabajo que se ejecutan en las VM.
En vSphere 8, el rendimiento de DRS se mejora significativamente aprovechando las estadísticas de memoria, lo que da como resultado decisiones de ubicación óptimas para las máquinas virtuales sin afectar el rendimiento ni el consumo de recursos.
También se introdujo métricas verdes para monitorear las emisiones de energía y carbono de la infraestructura de vSphere y las cargas de trabajo, ayudando a las organizaciones a visualizar su huella de carbono.
Nota: Usage es una metrica de potencia real medida en función del uso activo de la CPU y la memoria de las máquinas virtuales. Se deriva de los medidores de potencia conectados a los hosts (IPMI, interfaz de administración de plataforma inteligente).
Nota: Static Power es una metrica potencia inactiva modelada de la máquina virtual, como si la máquina virtual fuera un host físico hipotético configurado con la misma cantidad de CPU y memoria que la máquina virtual.
Seguridad y Cumplimiento
Finalmente, en términos de seguridad, vSphere 8.0 GA es más seguro por defecto. Se eliminó la opción de usar TLS 1.0 y 1.1, dejando solo TLS 1.2 como opción. También se implementó restricciones para evitar que binarios no confiables se ejecuten en ESXi, lo que significa que solo se pueden ejecutar paquetes firmados.
Además, se introduce un tiempo de espera automático para SSH, que se deshabilitará automáticamente si no se utiliza, ayudando a mitigar posibles vectores de ataque.
Conclusión
Esto ha sido un resumen técnico de las novedades en vSphere 8.0 GA. Hay mucho más que explorar y descubrir así que te invito a seguir nuestro blog, y participar en este bonito camino de adopción de nuestras tecnologías VMware By Broadcom.
Recuerda que estamos haciendo un repaso de las funcionalidades que han sido liberadas en cada uno de los updates de vSphere. Posteriormente haremos lo mismo con vSAN, NSX, VCF, y los productos que componen la Aria Suite.
¡Gracias por tu atención y espero que encuentres útiles estas nuevas características que fueron lanzadas hace un tiempo pero que probablemente no sabías, no recordabas o nunca habías escuchado hablar de ellas!
Recursos
¡IMPORTANTE! He migrado blog del dominio nachoaprendevirtualizacion.com a nachoaprendeit.com. Si te ha servido este artículo deja tu buen Like y compártelo con tus colegas, estas aciones me ayudarán a optimizar los motores de búsqueda para llegar a más personas, y a motivarme a seguir compartiendo este tipo de artículos.
TODOS LOS NOMBRES DE VMS USADOS EN ESTE BLOG SON INVENTADOS Y OBEDECEN A UN AMBIENTE DE LABORATORIO PROPIO, UTILIZADO PARA FINES DE ESTUDIO.
Con la introducción del modelo de Policy como API de NSX principal a partir de NSX 2.4 (publicado en febrero de 2019), NSX ofrece un modelo de API jerárquica declarativa que simplifica el consumo llamada Policy Mode. Sin embargo, aún me sigo encontrando clientes que tienen su NSX Manager configurado con el viejo Manager Mode.
En este artículo vamos a ver la opción que nos ofrece el mismo NSX Manager para mover la configuración heredada existente de la API de NSX Manager Mode (llamada API de MP) a NSX Policy Mode sin interrumpir la ruta de datos, ni eliminar o volver a crear los objetos existentes.
Con esta función, podemos promover los objetos creados en NSX Manager Mode a NSX Policy Mode y, a continuación, interactuar con los mismos objetos a través de la interfaz de usuario de NSX Policy o las API de NSX Policy. La lista de objetos soportados para ser promovidos se encuentra en Promote Manager Objects to Policy Objects.
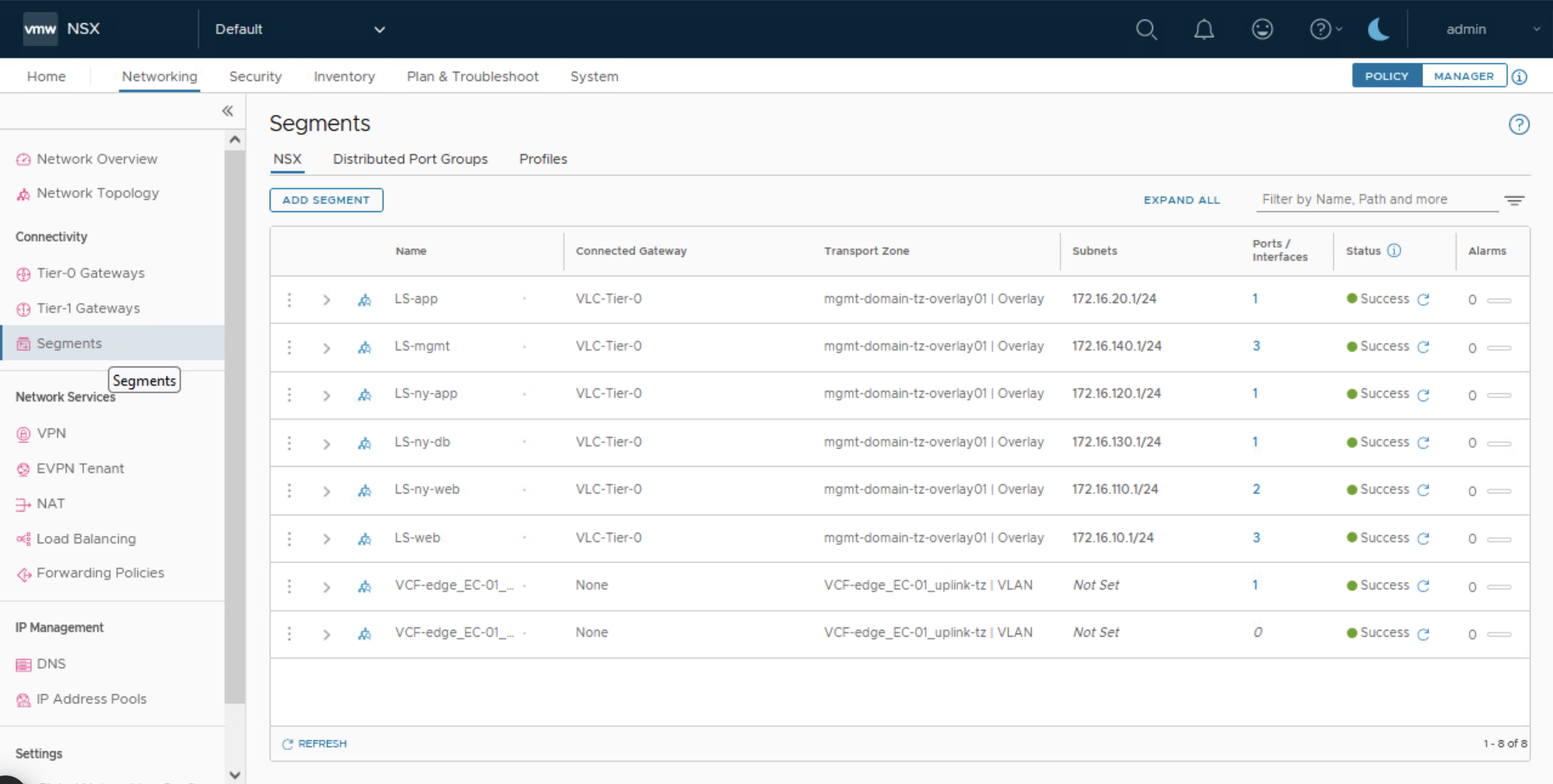
Tenemos tres Logical Switches creados en la interface de Manager Mode que necesitamos promover al Policy Mode. Una característica de estos objetos es que no tienen el icono circular con dos linean en medio que caracteriza los objetos creados en Policy Mode.
Adicionalmente, estos objetos creados en Manager Mode no se pueden visualizar desde el Policy Mode, lo que puede traernos dificultades en algunas operaciones de día-2.
En vCenter tanto los objetos creados a tráves de Manager Mode o Policy Mode, se visualizan de forma similar, de manera que acá no vamos a ver ninguna diferencia.
Procedimiento para promover del Manager al Policy
Muy bien ahora vamos seguir la documentación oficial Promote Manager Objects to Policy Objects en donde se nos indica el procedimiento para esta promoción. Pero no te preocupes acá lo vamos a revisar paso a paso!
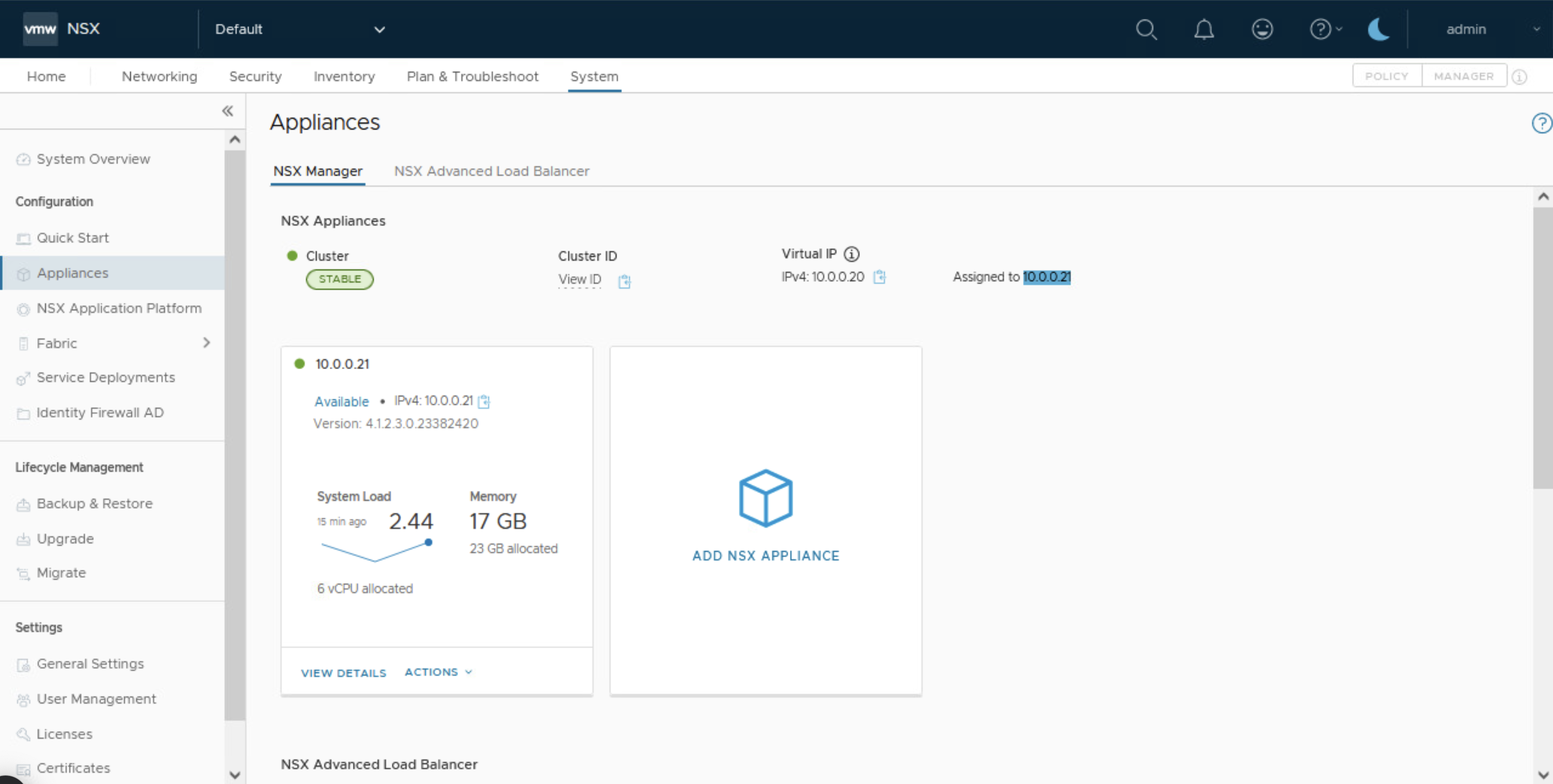
Validamos cual NSX Manager es el lider desde la interface de NSX. Teniendo en cuenta que un ambiente productivo van a existir tres NSX manager y el leader será el que tiene asignado la VIP del cluster de NSX Managers.
Nota: En mi laboratorio solo tengo un NSX Manager de manera que será ese mismo.
Importante asegurarnos de tomar un backup por archivos del NSX justo antes de ejecutar el procedimiento. Sino tiene backup configurado, deberá configurar un SFTP y apuntar el backup de NSX hacia ese servidor como se indica en la documentación oficial Configure Backups. De esta manera, en caso de que la promoción falle, podemos revertir el sistema a su estado original usando la copia de seguridad.
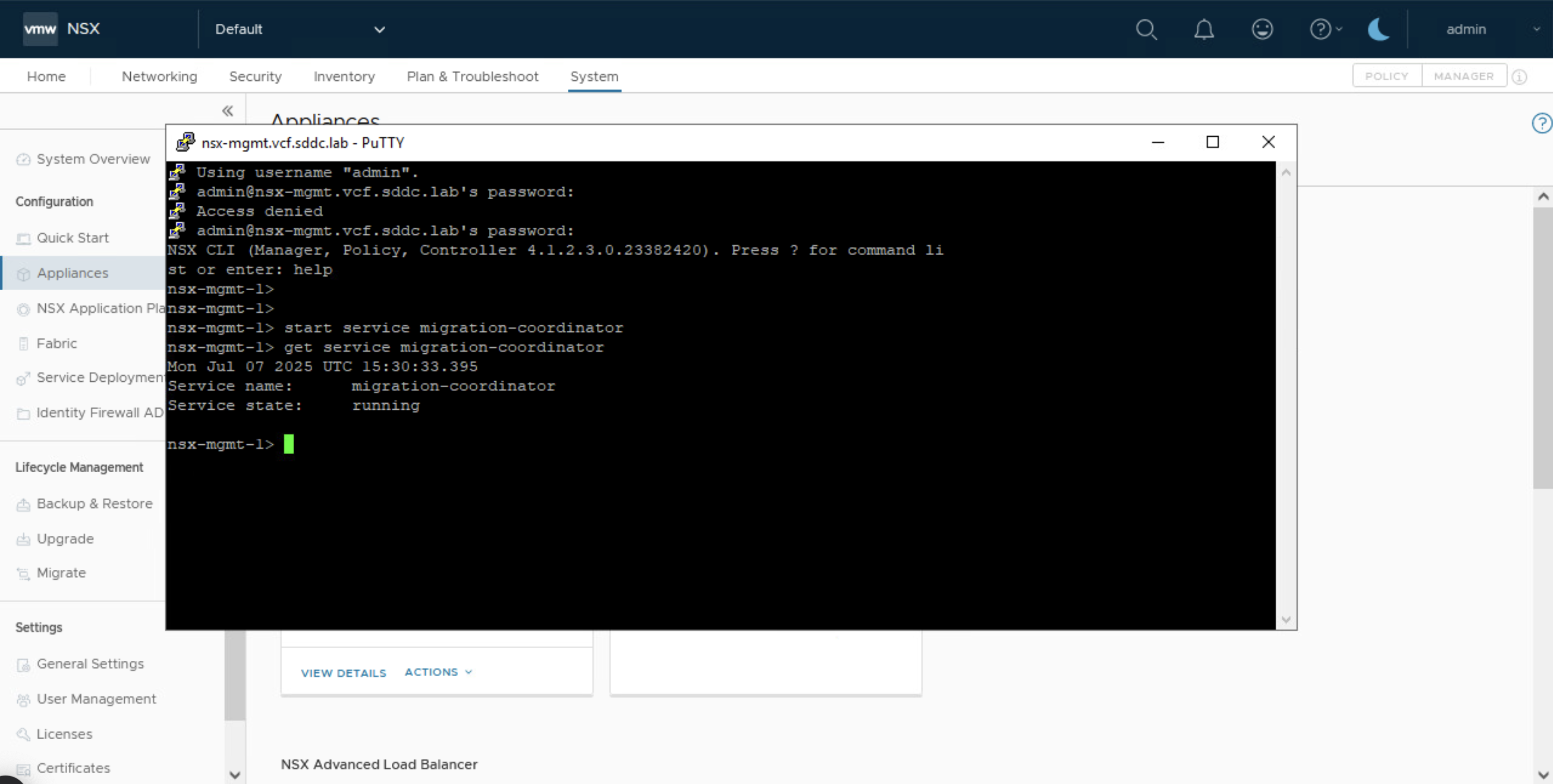
Iniciamos sesión SSH con el usuario admin en el nodo de NSX Manager que hemos identificado como lider en el paso anterior, para luego iniciar el servicio de migration-coordinator y verificar que se haya iniciado correctamente con los siguientes comandos
start service migration-coordinator get service migration-coordinator
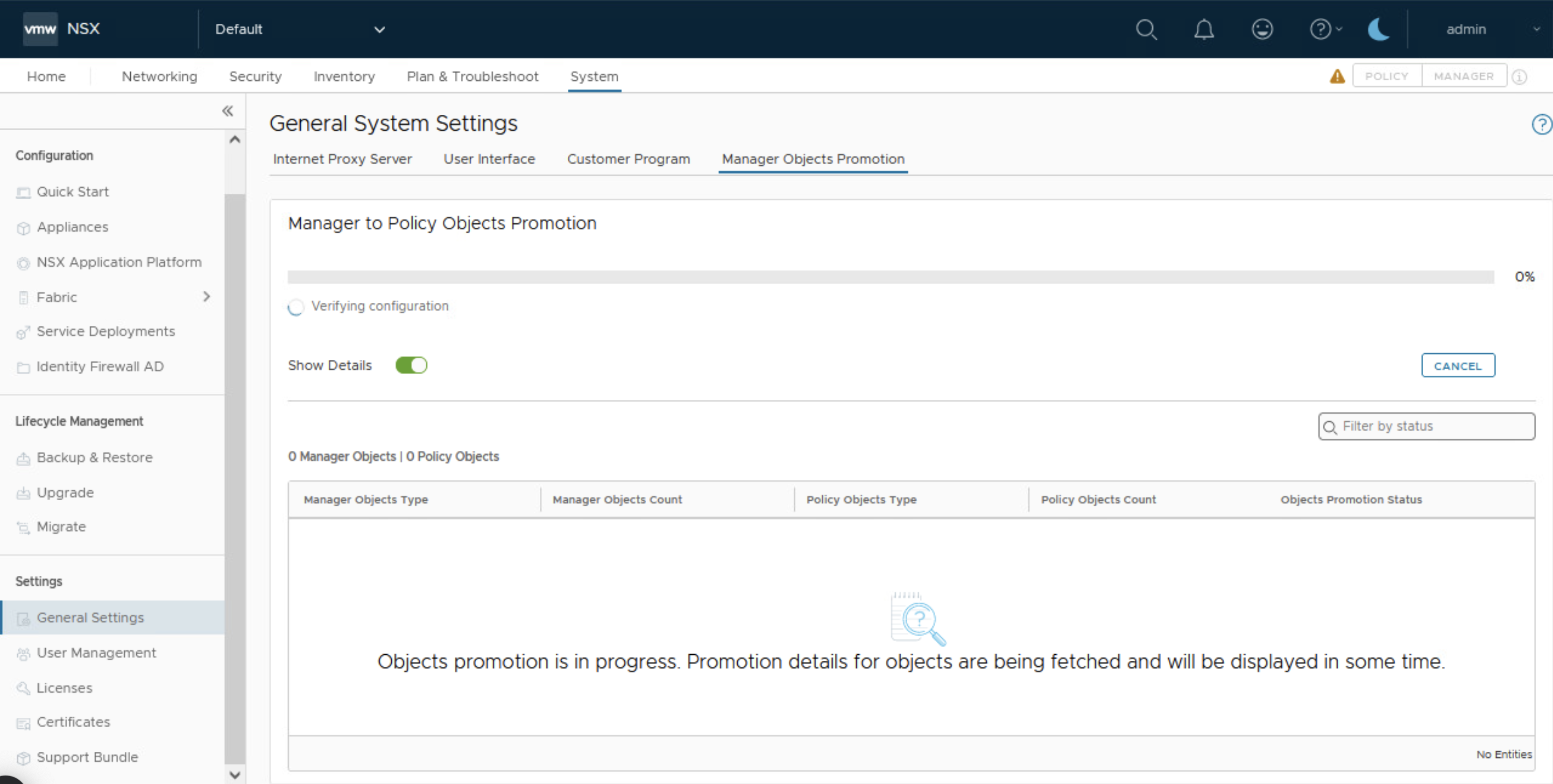
Una vez iniciado el servicio vamos System > General Settings >Manager Objects Promotion y deberíamos ver el botón de START OBJECT PROMOTION.
Nota: Sino aparece esta opción es porque aún no se ha iniciado el servicio de Migration-Coordinator como se especificó en pasos anteriores.
Click en START OBJECT PROMOTION para comenzar con el proceso promoción y visualizar cuales objetos vas a ser movidos.
Clic en CONTINUE para iniciar la migración
Esto tomará solo unos pocos segundos y podremos ver que la migración ha terminado satisfactoriamente.
Para ver el detalle o resumen de lo que se hizo, podemos hacer clic en el link que aparece frente a Recent Activity
Resultado
Este procedimiento no es disruptivo y de hecho podemos ver que durante el cambio, las VMs conectadas a los Logical Switches del Manager Mode, ahora Segmentos del Policy Mode, No fueron afectadas.
Después de la migración, los objetos creados en el Manager Mode van a tener icono del Policy
Y en el Policy Mode ya debemos ver los Segmentos disponibles que antes solo se veían en el Manager Mode
Recomendación
Para evitar que se sigan creando objetos en el Manager Mode, se recomienda que desactivemos la vista de Manager Mode en la UI de NSX y para eso debemos seguir la documentación Configure the User Interface Settings, que de nuevo, explicarémos para que no tenga que ir a leerla.
Nota: Para los despliegues greenfield de NSX 4.x, los usuarios no verán esta opción debido a que el Default es Policy.
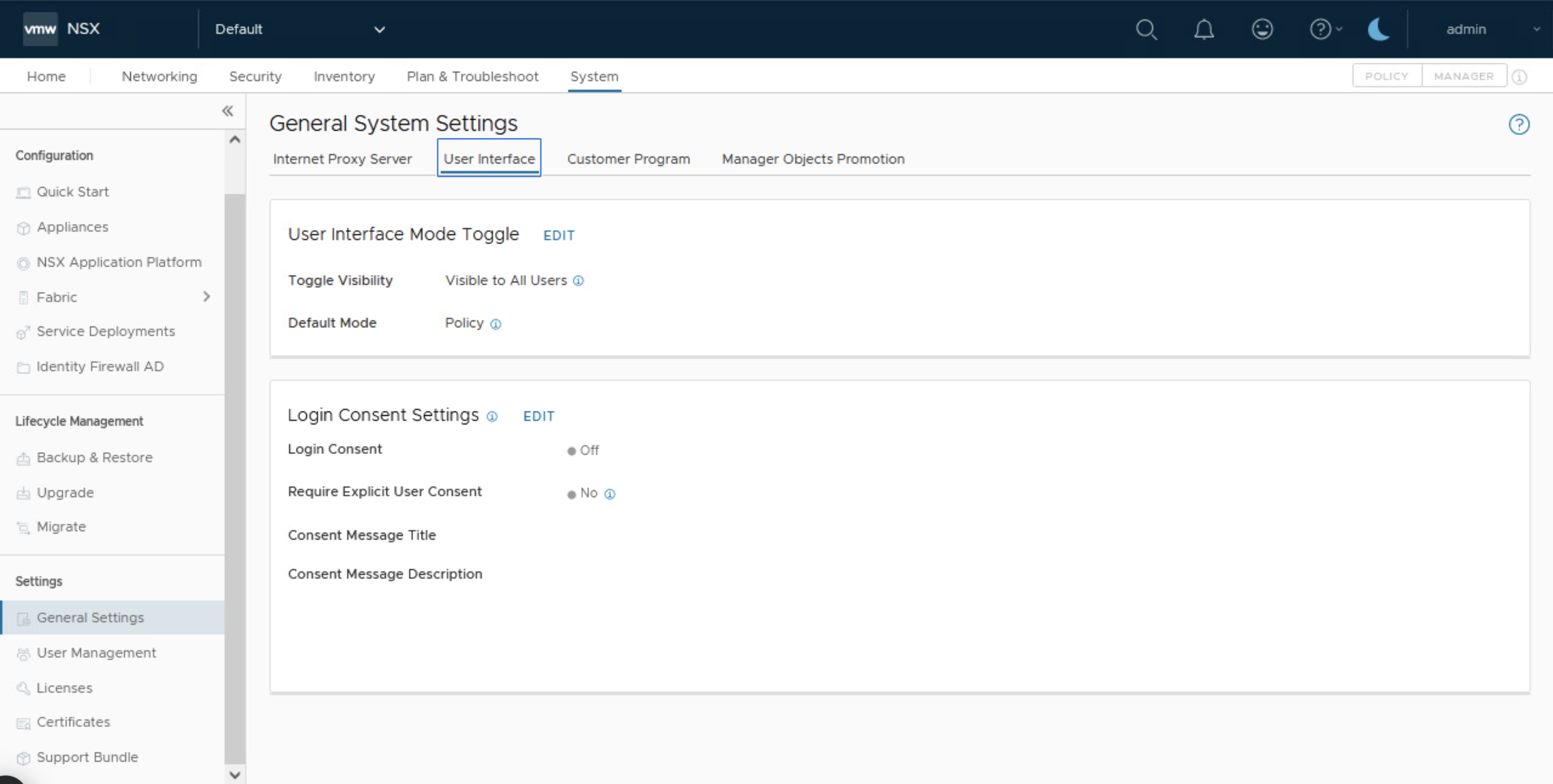
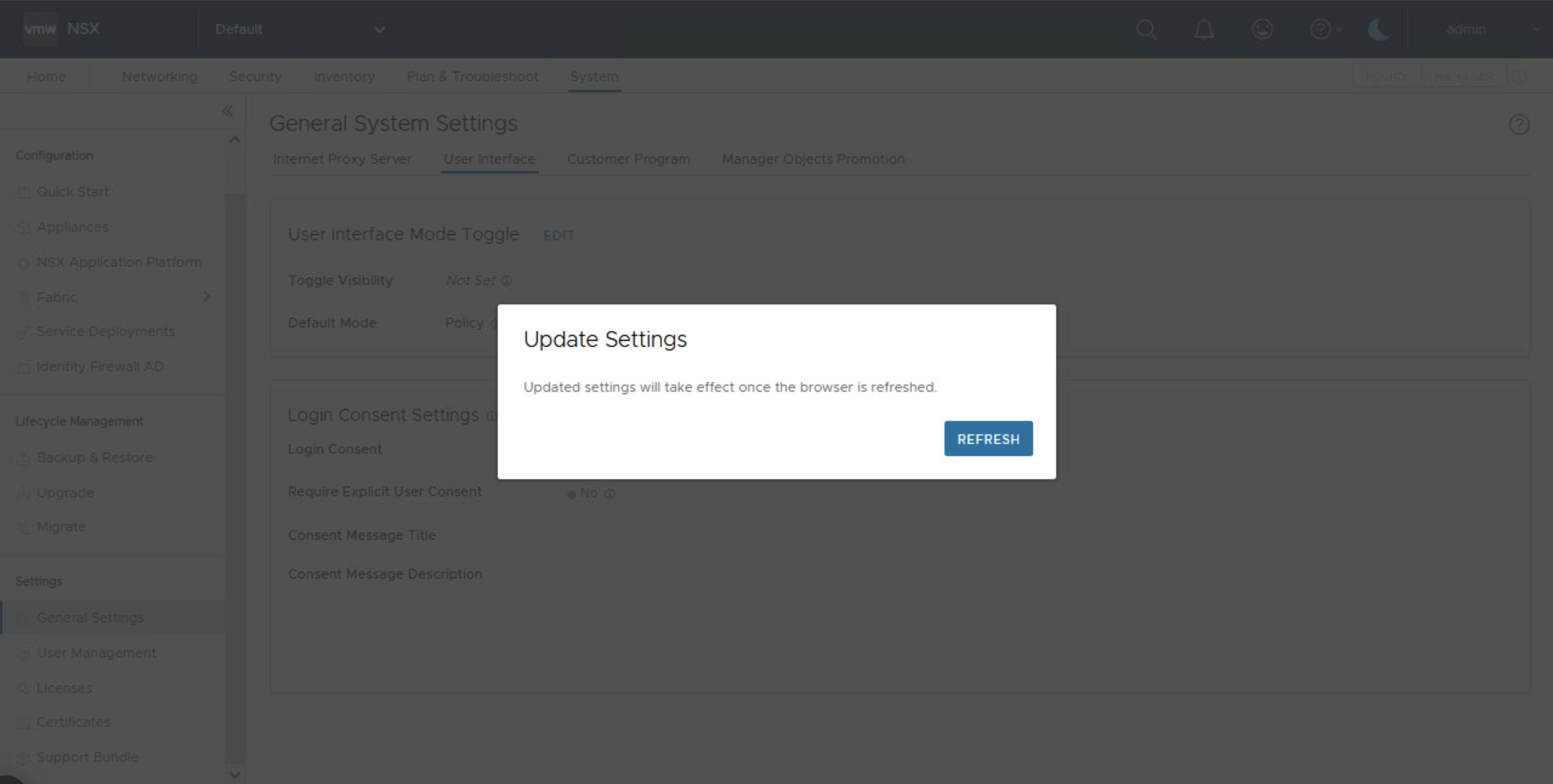
Para esto entonces solo debemos ir a System > General System Setting > User Interface y clic en edit frente a User Interface Mode Toggle
Las opciones disponibles son las siguientes:
Activar o desactivar visibilidad
Descripción
Visible para todos los usuarios
Si hay objetos del modo Manager presentes, los botones de modo son visibles para todos los usuarios.
Visible para usuarios con el rol de administrador empresarial
Si hay objetos del modo Manager presentes, los botones de modo son visibles para los usuarios con el role Enterprise Admin.
Oculto para todos los usuarios
Incluso si objetos del modo Manager estan presentes, los botones de modo permanecen ocultos para todos los usuarios. Esto solo muestra la interfaz de usuario del modo Policy, incluso si objetos del modo Manager estan presentes.
Modo predeterminado
Se puede configurar como Policy o Manager, si está disponible.
Mi recomendación es dejar la opcion Toggle Visible en Oculto para todos los usuarios o Hidden from All Users y en el Default Mode asegurarnos que este marcada la opción Policy
De esta manera ya no aparecerá la opción de seleccionar entre Policy o Manager cuando entramos al la UI del NSX
Y esto es todo amigos!, de esta manera vamos a poder migrar Objetos Manager a Objetos Policy de manera automática, facil y sin afectar el servicio.
¡IMPORTANTE! He migrado blog del dominio nachoaprendevirtualizacion.com a nachoaprendeit.com. Si te ha servido este artículo deja tu buen Like y compártelo con tus colegas, estas aciones me ayudarán a optimizar los motores de búsqueda para llegar a más personas, y a motivarme a seguir compartiendo este tipo de artículos.
TODOS LOS NOMBRES DE VMS USADOS EN ESTE BLOG SON INVENTADOS Y OBEDECEN A UN AMBIENTE DE LABORATORIO PROPIO, UTILIZADO PARA FINES DE ESTUDIO.
This post is aimed at those who need to update the version of the Kubernetes cluster that supports the NSX Application Platform (NAPP) solution. It must always be aligned with VMware’s interoperability matrix. The process we will describe below should also be followed when performing an upgrade of NSX (which uses NAPP), vCenter (with vSphere with Tanzu), or VCF (with Workload Management enabled) to avoid breaking the integration with the Kubernetes (K8s) clusters.
What is the NAPP
NSX Application Platform (NAPP) is a microservices-based platform that houses various NSX functions that collect, ingest, and correlate network traffic information. As data is generated, captured, and analyzed in your NSX environment, NSX Application Platform provides a platform that can dynamically scale based on the needs of your environment.
The platform can host the following NSX functions that collect and analyze data in your NSX-T environment.
For those who are unclear about what constitutes a NAPP (NSX Application Platform) deployment, we can provide an image that summarizes the deployment components. The main component supporting the NAPP solution is the vSphere with Tanzu solution.
I know that the previous image may cause fear. However, the engineering team at VMware By Broadcom has developed a tool called NAPPA (NSX Application Platform Automation Appliance) in order to facilitate the deployment of each of the components that make up the entire Kubernetes infrastructure required to support the NAPP (NSX Application Platform) solution.
This way, NAPPA executes flows automatically to configure vSphere with Tanzu, which is a solution that allows us to run K8s clusters directly on the hypervisor through the creation of vSphere Namespaces. Similarly, NAPPA, using the Supervisor Cluster deployed with vSphere with Tanzu, automatically creates a vSphere namespace, where a Tanzu Kubernetes Cluster is established, which we will refer to as the Guest Cluster from now on, and this is where the NSX Application Platform solution comes to life, along with all the pods associated with the services of Metric, VMware NSX® Intelligence™, VMware NSX® Network Detection and Response™, VMware NSX® Malware Prevention, and VMware NSX® Metrics.
To make the story shorter, we’ll leave it at that.
The issue: TKR version out of support
Now, the problem we are going to solve here is how to maintain this Guest Cluster after implementing it with the NAPPA. Because in many instances, depending on the version of NSX we had at the time of deploying the NAPP (NSX Application Platform), the version of that cluster may remain on an unsupported version which can cause issues as we update our vSphere and NSX environment.
For laboratory purposes, we have deployed the latest version of NAPP 4.2.0, and interestingly, the guest cluster has been implemented using the TKR version 1.23.8+vmware.3-tkg.1, which as of now is out of support. This behavior is a known issue for the NAPPA tool, and to avoid this behavior, I invite you to read the following post Deploying NAPP with supported TKR version.
Compatibility Analysis
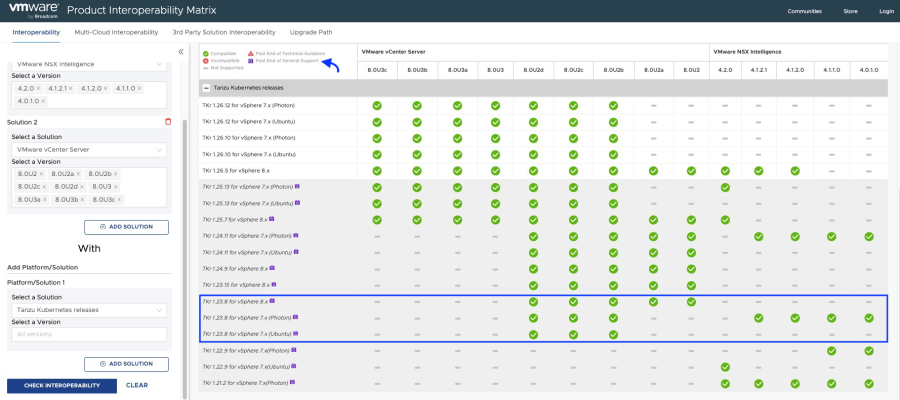
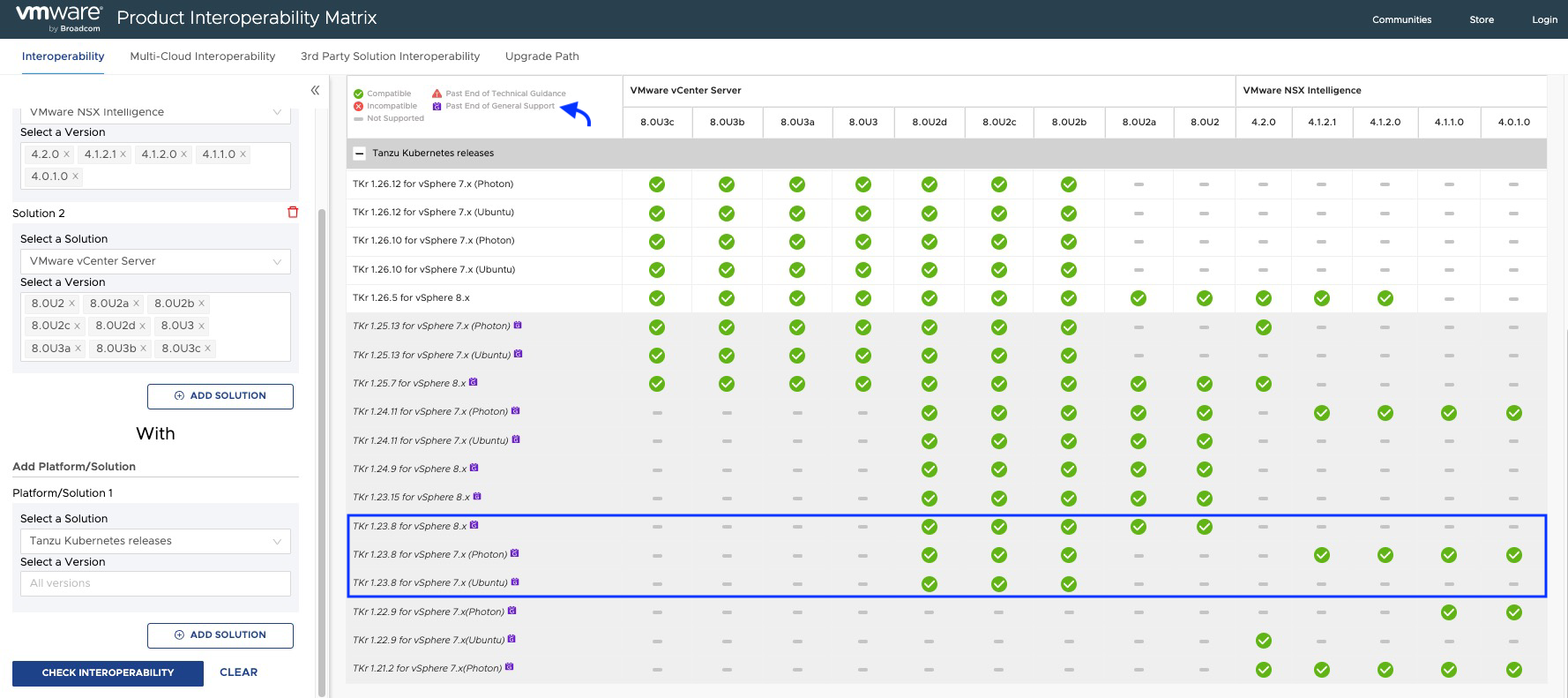
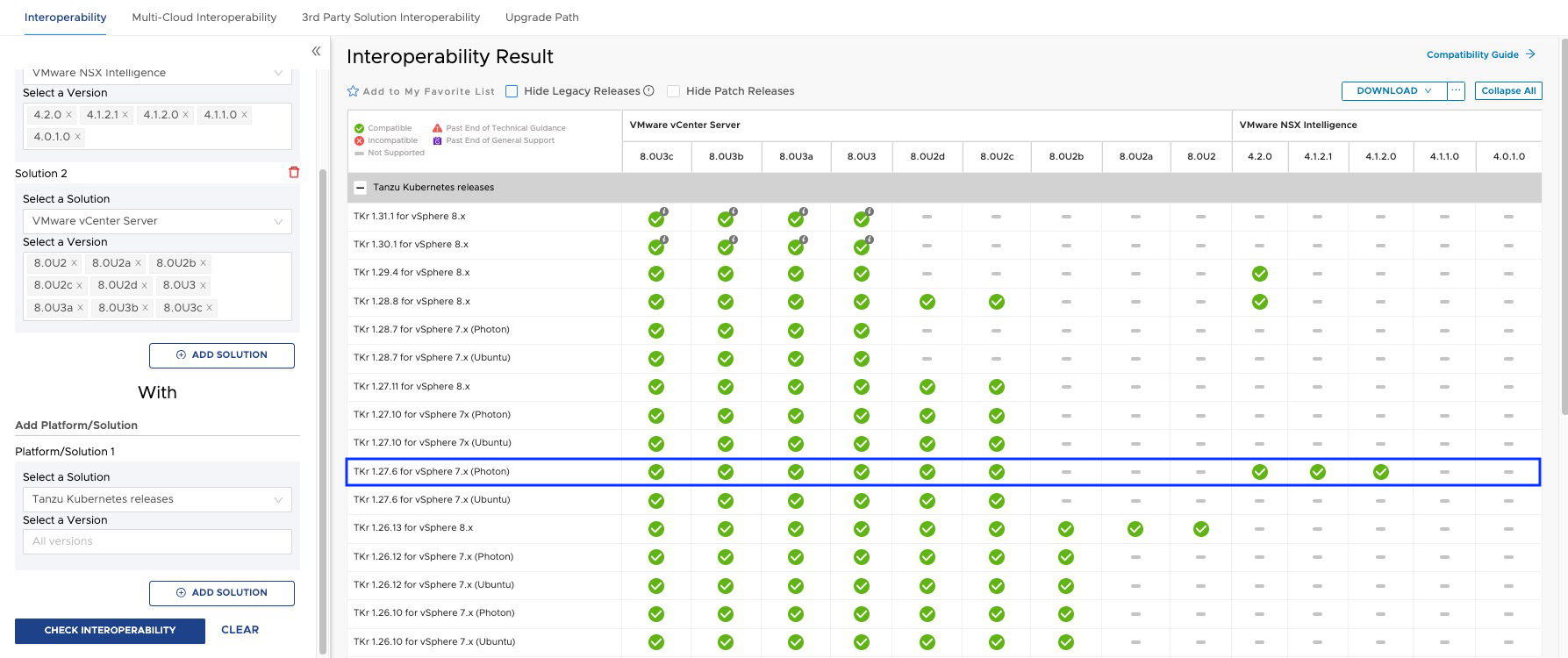
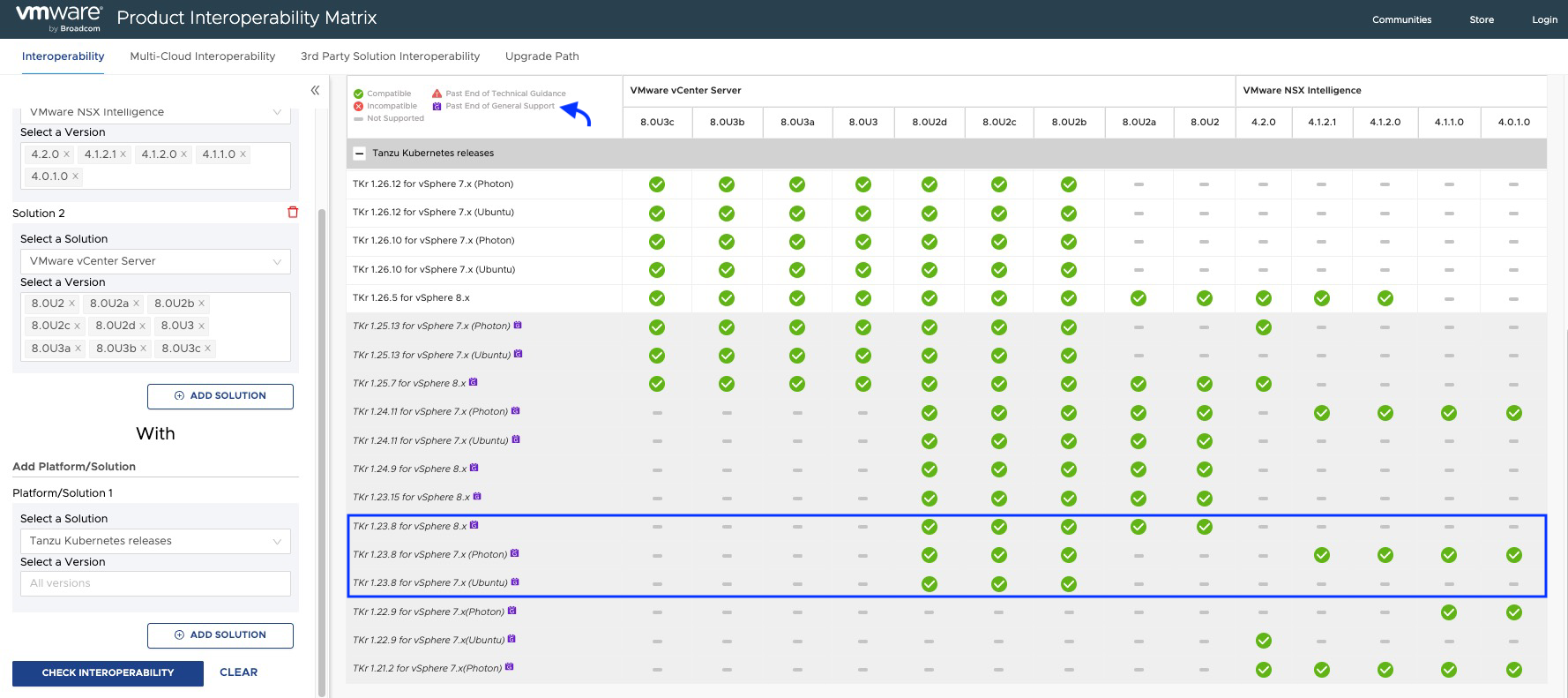
According to the interoperability matrix, we should meet the following minimum versions of TKR.
As we can see in the interoperability matrix, TKR versions below 1.26.5 used by the NAPP guest cluster are currently out of support, and some of them may not be compatible with your NSX Intelligence or your vCenter Server.
Note: The procedure explained below should be performed when we upgrade NSX or vCenter Server, whether as a result of an update of VMware Cloud Foundation (VCF) or when we update these solutions independently, in order to keep the NAPP cluster compatible and within VMware by Broadcom support.
Note: We must keep in mind that the TKR version can only be upgraded incrementally, n + 1, meaning that if we have version 1.23, the first jump must be to 1.24 and so on, until reaching the required version.
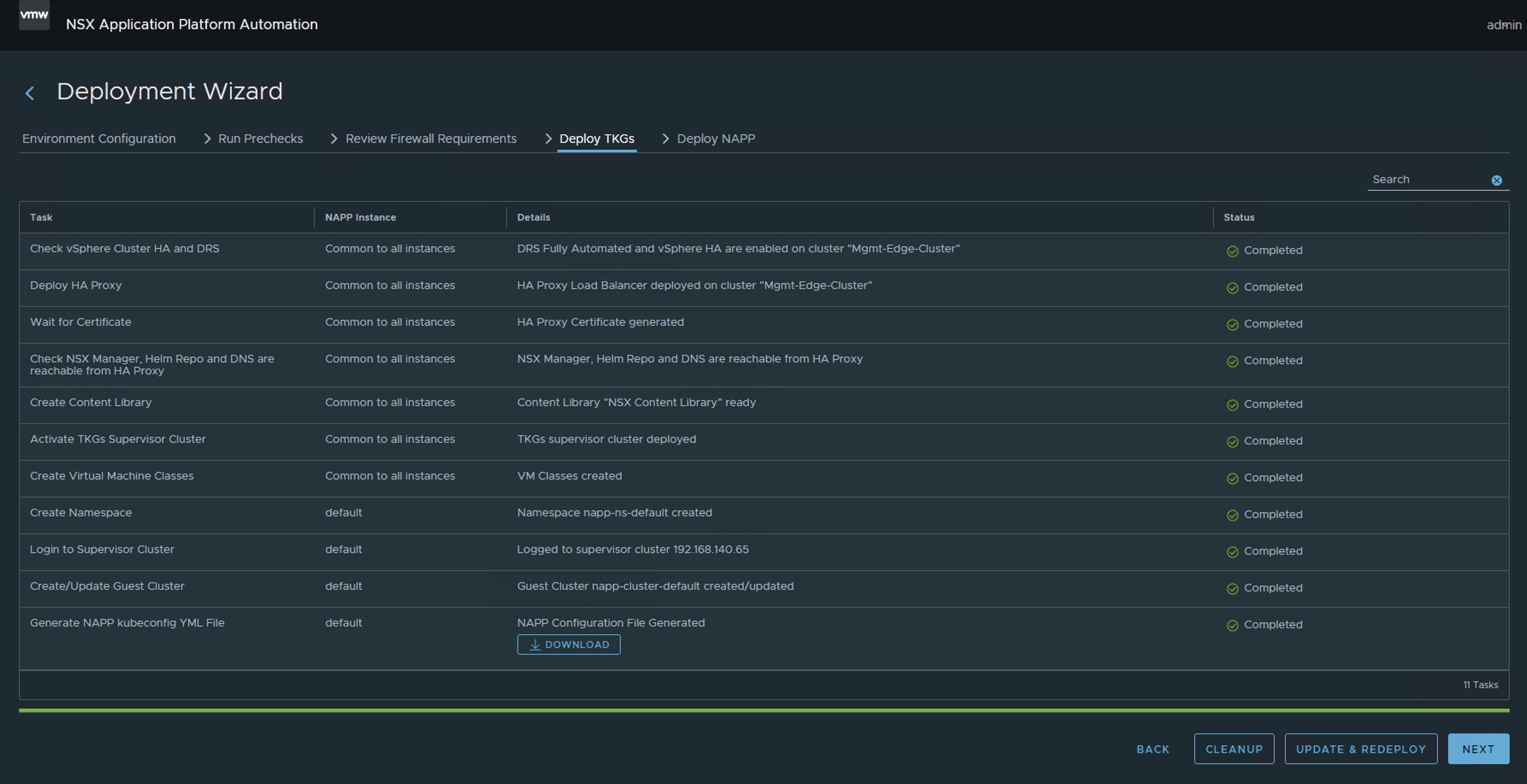
Log in to the NAPPA via SSH, using the root user, so that we can connect to the cluster supervisor without needing to install any plugins on our VM, and we will execute the following command.
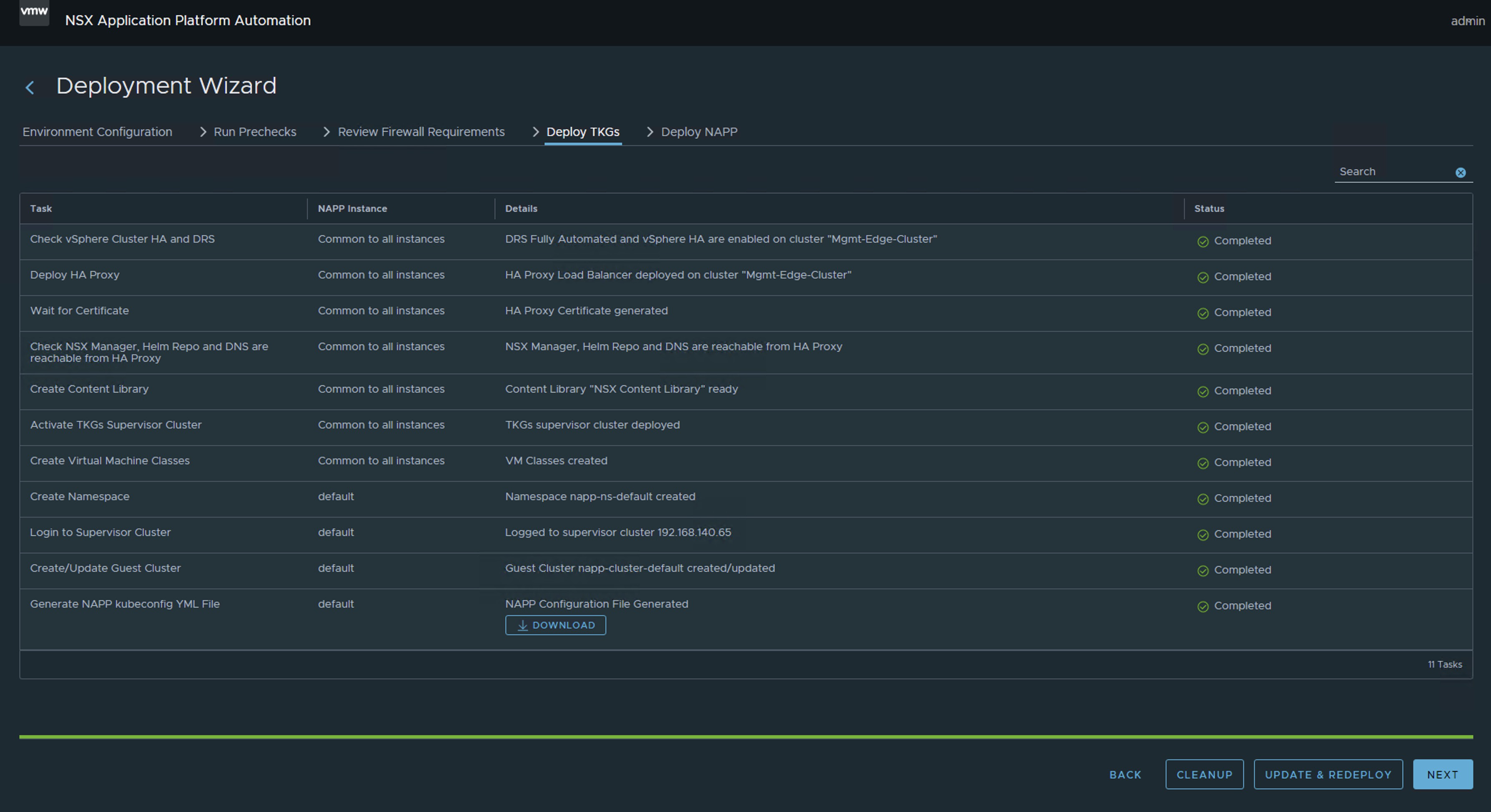
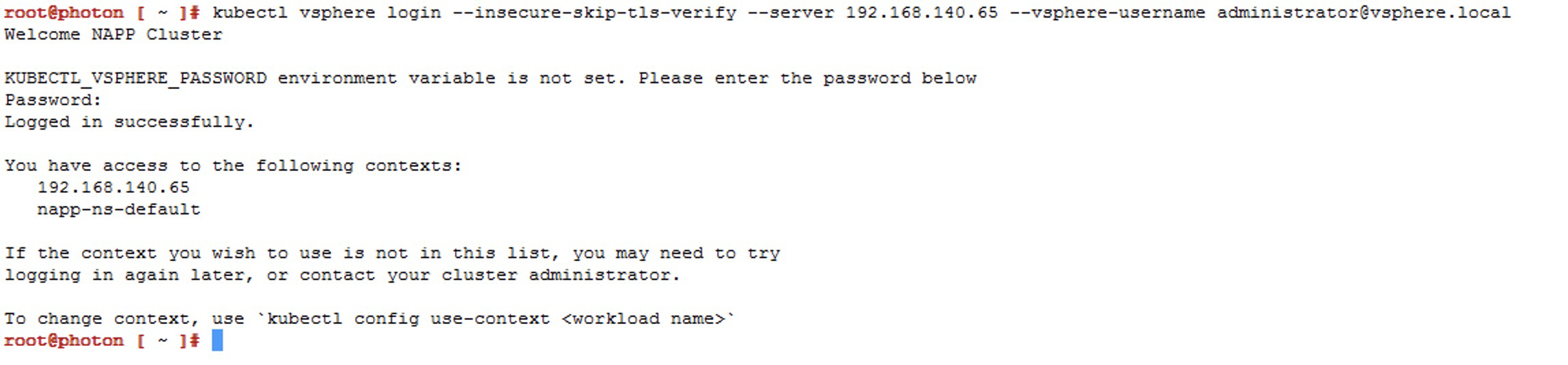
Run the following command to connect to the Supervisor cluster. If you don’t know the IP of the Supervisor Cluster, just go to vCenter Server > Menu > Workload Management > Namespaces > Supervisor Cluster kubectl vsphere login --insecure-skip-tls-verify --server [IP_SupervisorCluster] --vsphere-username administrator@vsphere.local Now we will choose the context that has our napp deployment, which should be napp-ns-default, and for this we use the following command kubectl config use-context [context_name]
We will validate the compatible versions of TKR available in the content library linked to that namespace, using the following command kubectl get tkr
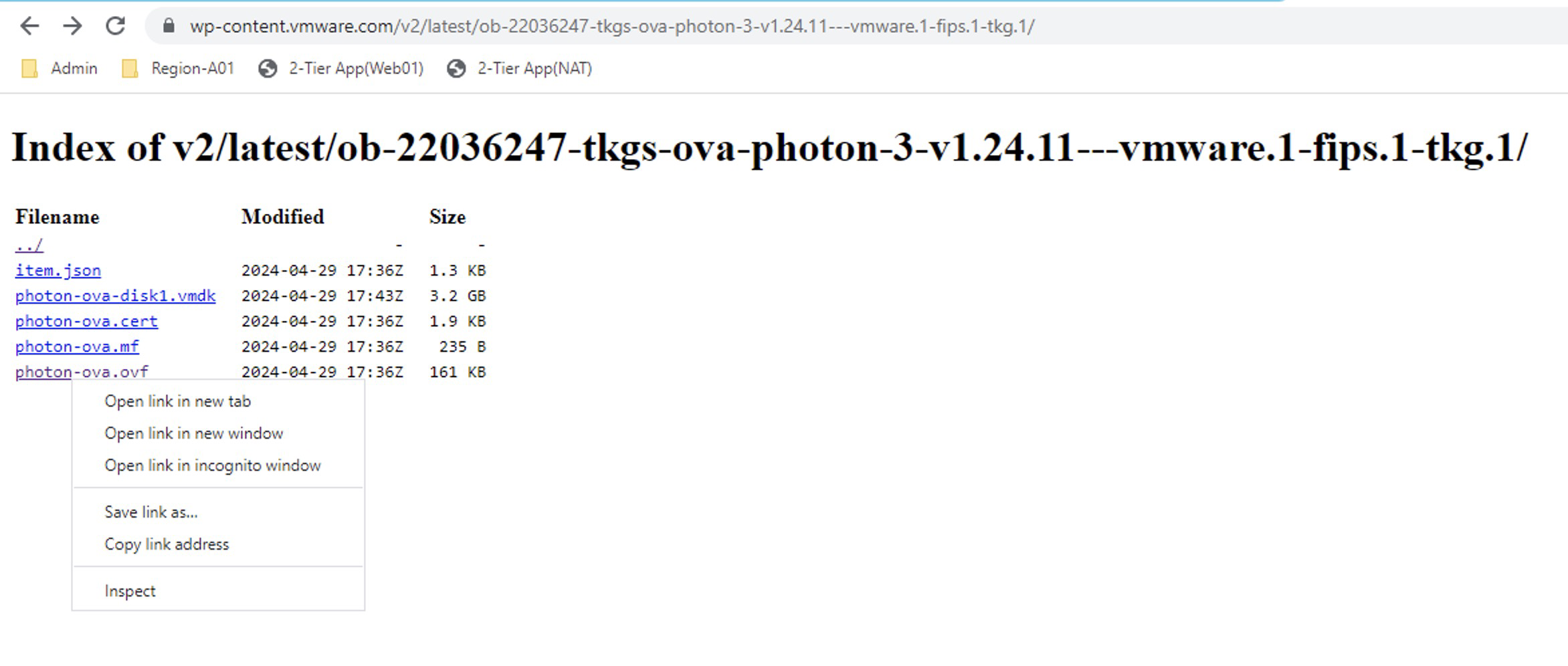
Here we can see that NAPPA has published three images in the content library, including the image 1.27.6+vmware.1-fips.1-tkg.1, which is newer and compatible. However, at the time of deployment, the 1.23.8+vmware.3-tkg.1 was used, which is unfortunate because now we have to upgrade the Guest Cluster to reach that version or a higher compatible one according to the interoperability matrix.
Note: During deployment, NAPPA configures a content library called NSX Content Library in the vCenter, with those three images. However, we cannot jump from v1.23.x to v1.27.x as previously mentioned, so we will have to upload the images to that library.
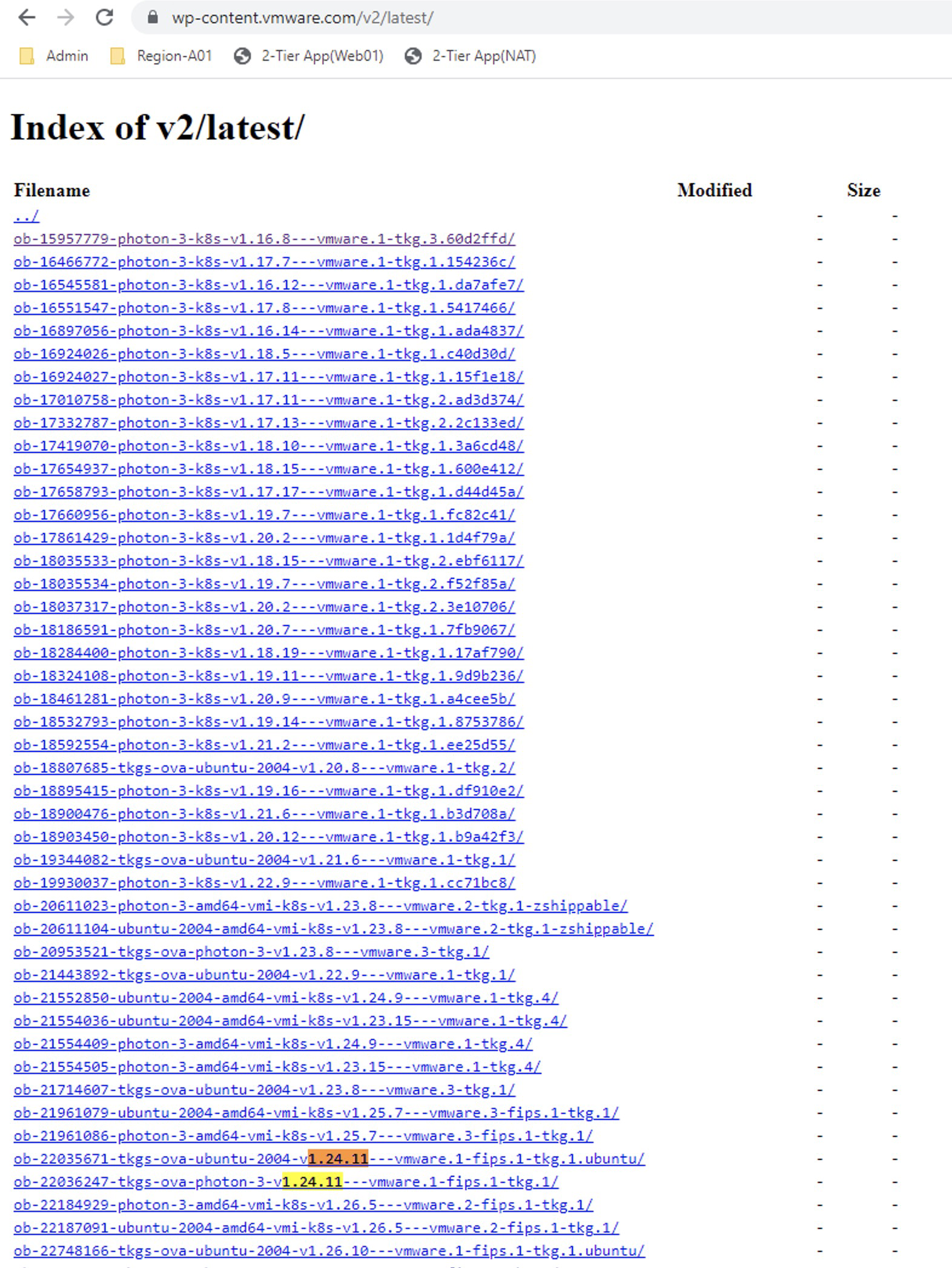
To download and upload the missing images to the content library, we need to go to the following URL https://wp-content.vmware.com/v2/latest/lib.json or we could also create a new Content Library Subscribed with the following URL https://wp-content.vmware.com/v2/latest/lib.json and connect the namespace to that library.
In this case, we will use the first option, and our first jump will be to version v1.24.x
In the repository, we see two images, but we will select the one called ob-22036247-tkgs-ova-photon-3-v1.24.11---vmware.1-fips.1-tkg.1 that is of course compatible according to the interoperability matrix. So we click on it and then right-click on photon-ova.ovf to copy the link.
Now let’s go to the content library NSX Content Library > Actions > Import Library Item and select the URL option, where we will paste the copied link earlier.
Note: In the item name, I recommend using the same name as in the download portal for easy identification.
Click on IMPORT and wait for it to download.
Repeat the steps for the following images that will be the gradual jumps: ob-22757567-tkgs-ova-photon-3-v1.25.13---vmware.1-fips.1-tkg.1 ob-23319040-tkgs-ova-photon-3-v1.26.12---vmware.2-fips.1-tkg.2 ob-23049612-tkgs-ova-photon-3-v1.27.6---vmware.1-fips.1-tkg.1 ob-24026550-tkgs-ova-photon-5-v1.28.7---vmware.1-fips.1-tkg.1
The Content Library should look like the following. Remember that the images we have selected have been chosen considering the interoperability matrix between NSX intelligence and Tanzu Kubernetes Releases.
Now if we run the command kubectl get tkr again, the images we have uploaded should show true in the READY and COMPATIBLE columns.
Note: We should not apply any image that does not meet these conditions.
Now we run the following command to see the next available version of the Kubernetes cluster and the name of the Guest Cluster that we are going to intervene. kubectl get tanzukubernetescluster
We list the Tanzu Kubernetes releases kubectl get tanzukubernetesreleases
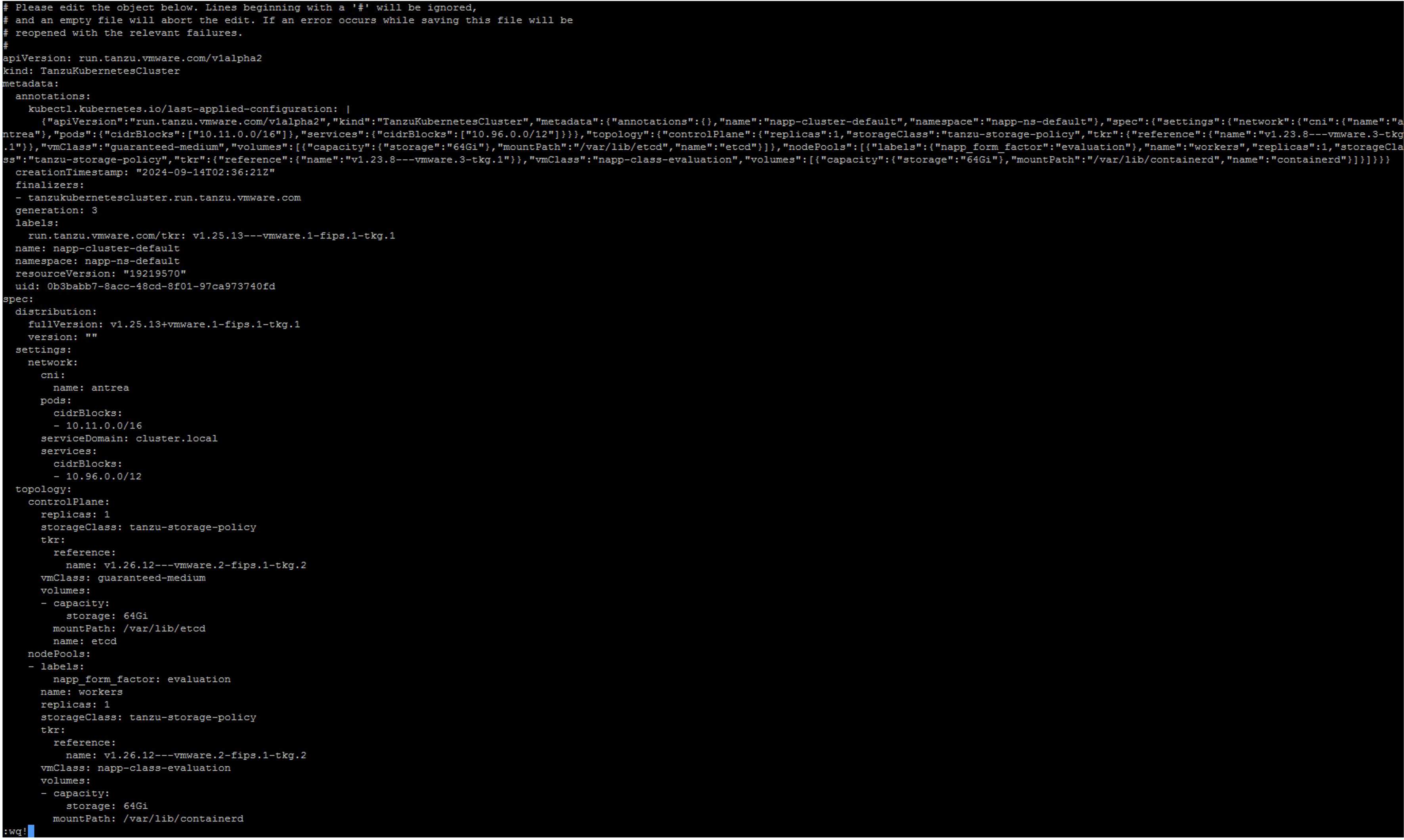
We execute the following command to edit the manifest of the Guest Cluster kubectl edit tanzukubernetescluster/CLUSTER-NAME
Here we will edit only the lines of references for the controlplane and nodePools that appear within the topology object
Verify that the output of the kubectl command indicates that the manifest edit was successful
Verify with the following command that the Guest Cluster is updating kubectl get tanzukubernetescluster Note: In the command output, we see that the READY column says False; we must wait for it to appear as True. Patience is key, this may take up to 30 minutes.
Once updated, it should look as follows
We repeat steps 8 to 11 until we reach the target version. For example, our next jump will be to version v1.25.13---vmware.1-fips.1-tkg.1 and so on. However, before doing so, read the following important notes.
At the end, we should see the distribution version as follows
Important Notes
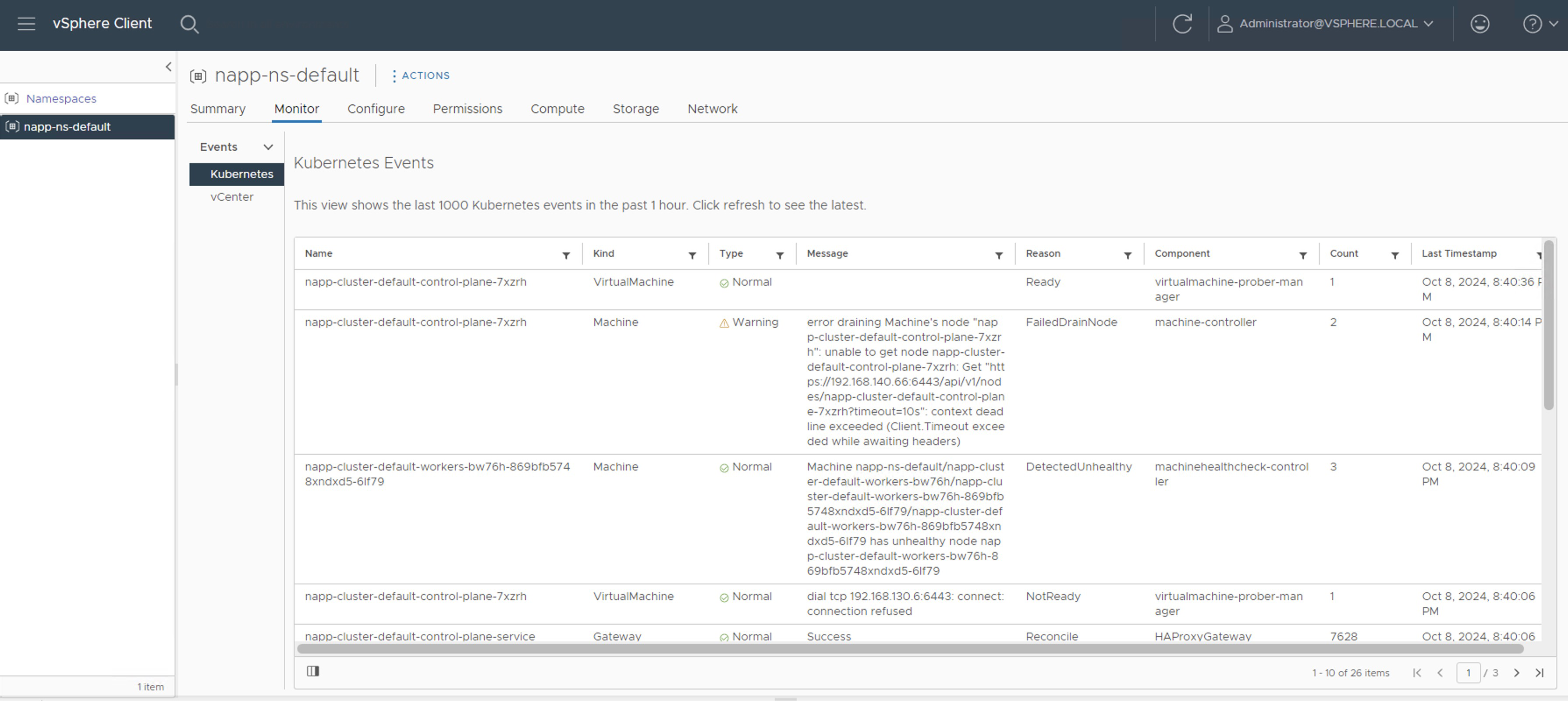
Note 1: We can monitor the process from napp-ns-default > Monitor
In napp-ns-default > Compute, we must wait until the Phase column changes from Updating to Running. However, when Running appears, it does not indicate that it has finished. We can still see events and tasks running in the inventory.
Note 2: During each upgrade jump, we will see how additional nodes are created while the process occurs. The upgrade begins with the Control Plane nodes and then with the Worker nodes. It is important that before starting the next jump, we verify that there are no running tasks, and that the number of nodes in the inventory is correct; in my case, the LAB should only have one Control Plane node and one Worker Node. In the following screenshot, we see one additional node, indicating that it has not yet finished.
Once all activities are completed, we will check that the number of nodes for the Guest Cluster in the inventory is correct. However, we still need to wait for the NAPP solution to stabilize.
Note 3: We should expect the NSX Application Platform solution to appear stable from the NSX console. This may take a few minutes.
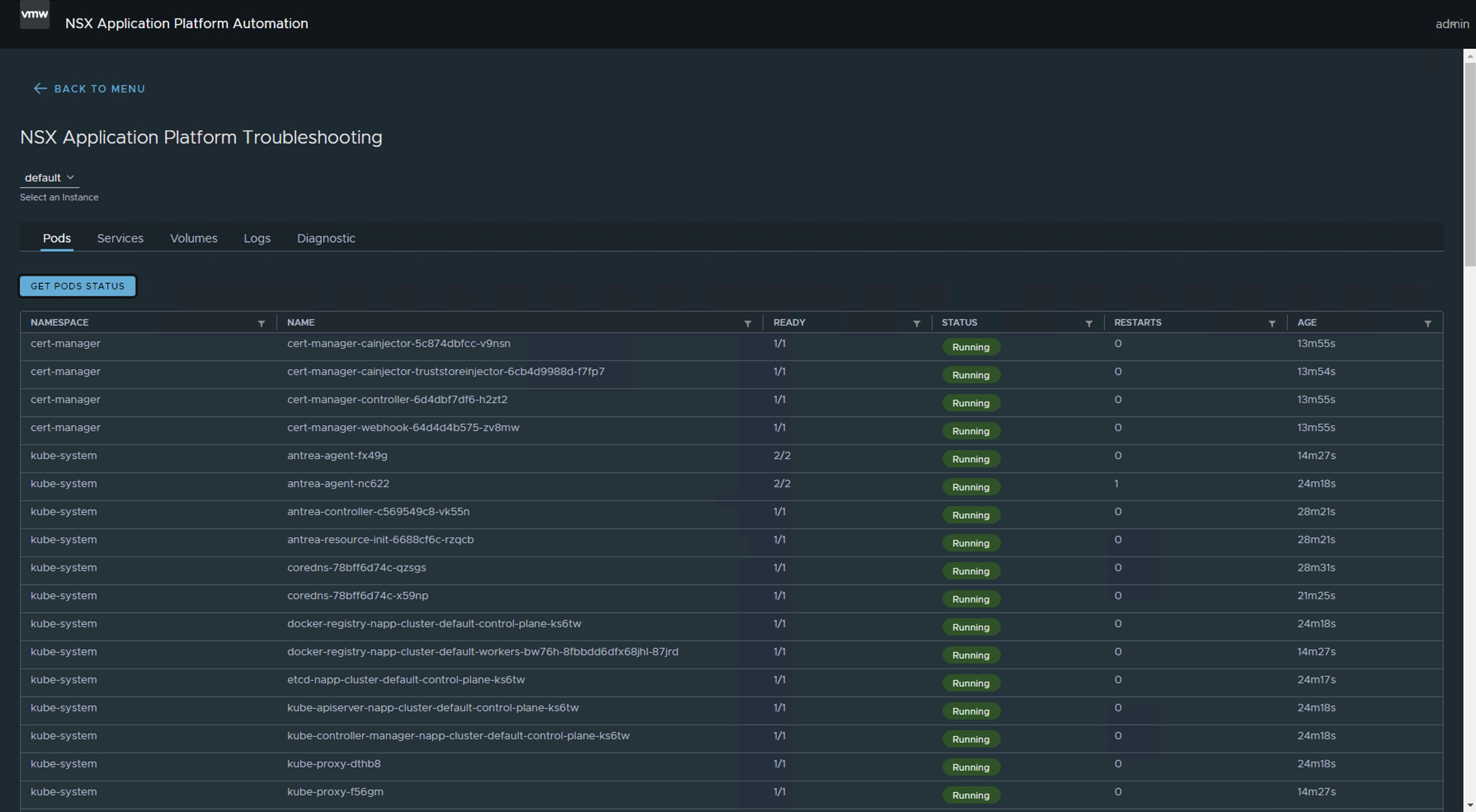
Note 4: If we use the Troubleshooting option of the NAPPA (NSX Application Platform Automation Appliance), we can see the moment when all the Pods are up.
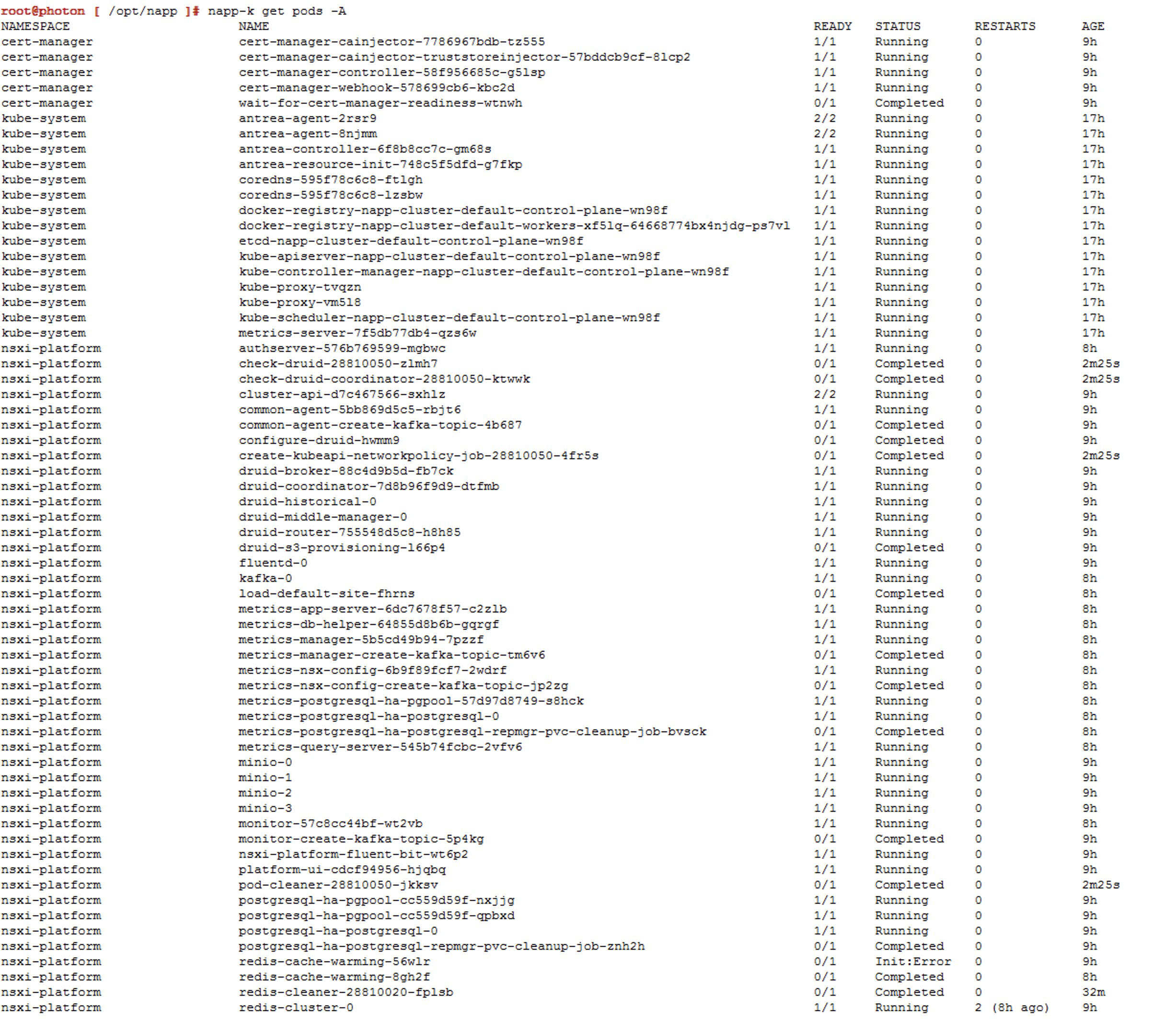
We can use the command napp-k get pods -A.
Reference screenshots for additional updates (jumps).
Jump to v1.25.13---vmware.1-fips.1-tkg.1
Jump to `v1.26.12—vmware.2-fips.1-tkg.2
Jump to `v1.27.10—vmware.1-fips.1-tkg.1
Update Kubernetes Tools
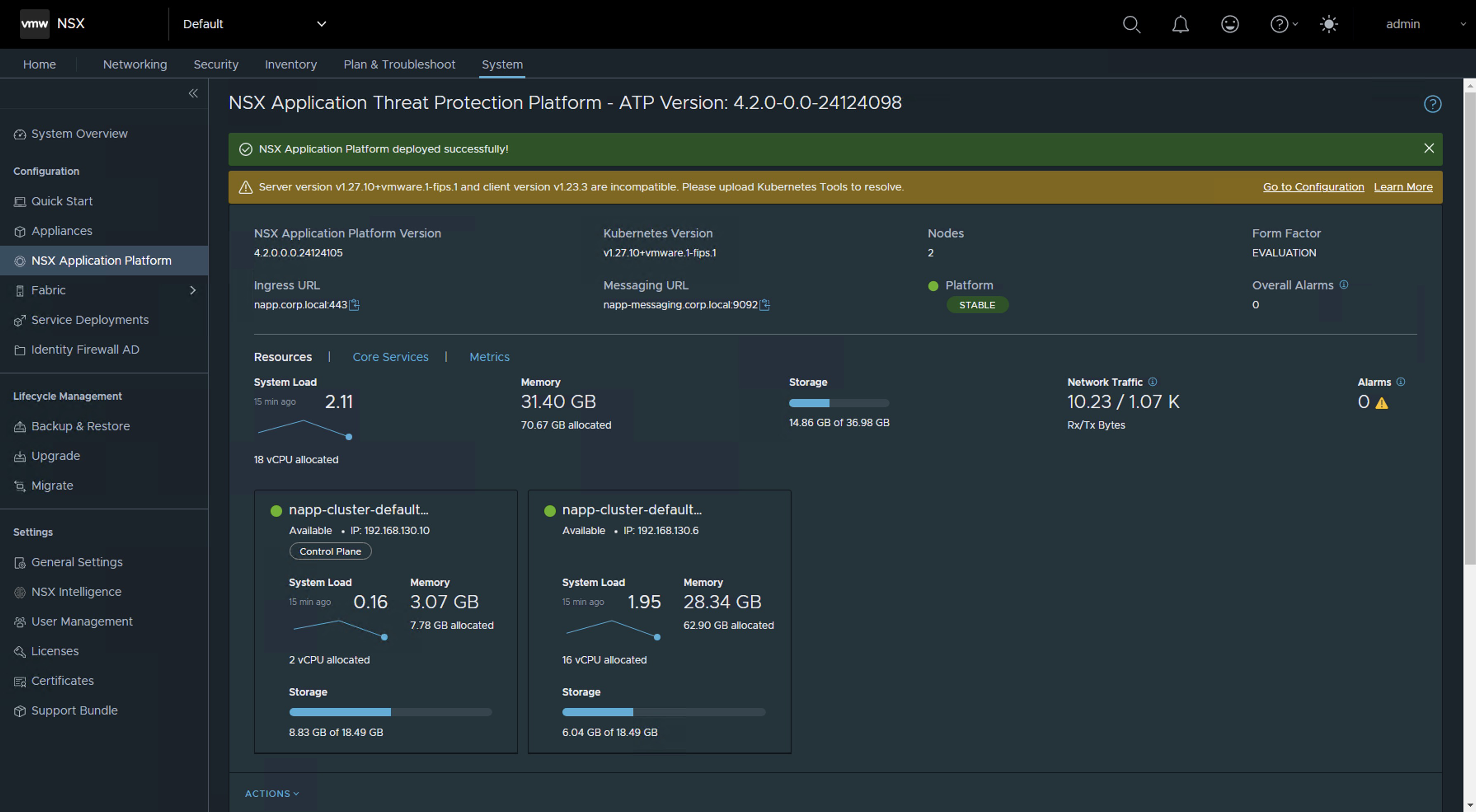
Once we have completed the updates and are now on a compatible version according to the NSX Intelligence interoperability matrix, you are likely to see the following alert on the interface. If you are on a version higher than NSX 4.1.2.2, this alert will probably not appear.
Server version v1.27.10+vmware.1-fips.1 and client version v1.23.3 are incompatible. Please upload Kubernetes Tools to resolve.
And that’s all, folks! With this procedure, you will be able to maintain the Kubernetes (K8s) cluster deployed as part of the NSX Application Platform (NAPP) solution.
IMPORTANT! I have migrated the blog from the domain nachoaprendevirtualizacion.com to nachoaprendeit.com. If you found this article useful, please give it a like and share it with your colleagues. These actions will help me optimize search engines to reach more people.
ALL NAMES OF VMS USED IN THIS BLOG ARE INVENTED AND PERTAIN TO A PERSONAL LABORATORY ENVIRONMENT, USED FOR STUDY PURPOSES.
Este post está dirigido para quienes tienen la necesidad de actualizar la versión del clúster de Kubernetes que soporta la solución NSX Application Platform (NAPP). La cual debe estar siempre alineada con la matriz de interoperabilidad de VMware. El proceso que vamos a describir a continuación también debe ser realizado cuando vayamos a realizar una actualización de NSX (que utilice NAPP), vCenter (con vSphere with Tanzu) o VCF (con Workload Management habilitado) para evitar romper la integración con los clústeres de Kubernetes (K8s).
Que es el NAPP
NSX Application Platform (NAPP) es una plataforma basa en microservicios que aloja varias funciones de NSX que recopilan, incorporan y correlacionan información de tráfico de red. A medida que se generan, capturan y analizan los datos en su entorno NSX, NSX Application Platform proporciona una plataforma que puede escalar dinámicamente en función de las necesidades de su entorno.
La plataforma puede alojar las siguientes funciones de NSX que recopilan y analizan los datos en su entorno NSX-T.
Para quienes no tienen claro qué conforma un despliegue de NAPP (NSX Application Platform), podemos dejar una imagen que resume los componentes del despliegue. Donde el componente principal para soportar la solución de NAPP, es la solución de vSphere with Tanzu.
Sé que la imagen anterior puede causar terror. Sin embargo, el equipo de ingeniería de VMware By Broadcom ha desarrollado una herramienta llamada NAPPA (NSX Application Platform Automation Appliance) con el fin de facilitar la implementación de cada uno de los componentes que conforman toda la infraestructura de Kubernetes requerida para soportar la solución de NAPP (NSX Application Platform).
De esta manera NAPPA ejecuta flujos de manera automática para, configurar vSphere with Tanzu, que es una solución que nos permite la ejecución de clústeres de K8s directamente sobre el Hipervisor a través de la creación de vSphere Namespaces. De igual manera NAPPA, usando el Supervisor Clúster desplegado con vSphere with Tanzu, crea automáticamente un vSphere namespace, donde se crea un Tanzu Kubernetes Clúster, al cual llamaremos Guest Cluster de ahora en adelante, y es donde la solución de NSX Application Platform toma vida, así como también todos los pods asociados a los servicios de Metric, VMware NSX® Intelligence™, VMware NSX® Network Detection and Response™, VMware NSX® Malware Prevention y VMware NSX® Metrics.
Para no hacer más largo el cuento lo vamos a dejar hasta ahí.
El problema: Versión TKR fuera de soporte
Ahora bien, el problema que vamos a solucionar acá es cómo mantener este Guest Cluster después de haberlo implementado con el NAPPA. Debido a que en muchas ocasiones, dependiendo de la versión del NSX que teníamos al momento de desplegar el NAPP (NSX Application Platform), la versión de dicho cluster puede quedarse en una versión fuera de soporte que puede generar problemas a medida que vamos actualizando nuestro ambiente de vSphere y de NSX.
Para efectos de laboratorio, hemos desplegado la versión más reciente de NAPP 4.2.0 y curiosamente el guest cluster se ha implementado usando la versión de TKR 1.23.8+vmware.3-tkg.1, que a la fecha está fuera de soporte. Este comportamiento es un issue conocido, para la herramienta de NAPPA y para evitar este comportamiento te invito a leer el siguiente post Desplegar NAPP con version de TKR soportado
Análisis de Compatibilidad
De acuerdo con la matriz de interoperabilidad deberíamos cumplir con las siguientes versiones mínimas de TKR.
Como podemos apreciar en la matriz de interoperabilidad, las versiones de TKR por debajo de 1.26.5 usadas por el guest cluster de NAPP, están actualmente fuera de soporte e incluso algunas de ellas podrían no ser compatible con tu NSX Intelligence o con tu vCenter Server.
Nota: El procedimiento explicado a continuación debe realizarse cuando hagamos una actualización de NSX o vCenter Server ya sea como consecuencia de una actualización de VMware Cloud Foundation (VCF) o cuando actualizamos estas soluciones de manera independiente, con el fin de mantener el clúster de NAPP compatible y dentro del soporte de VMware by Broadcom.
Nota: Debemos tener presente que la versión de TKR solo se puede subir de manera gradual, n + 1, es decir que si tenemos la versión 1.23, el primer salto debe ser a la 1.24 y así sucesivamente hasta alcanzar la versión requerida.
Iniciar sesión en el NAPPA vía SSH, con el usuario root ya que desde ahi podremos conectarnos al supervisor cluster sin necesidad de instalar ningún plugin en nuestra VM y vamos a ejecutar el siguiente comando.
Ejecutar el siguiente comando para iniciar conexión al Supervisor cluster. Sino sabes cuál es la IP del Supervisor Cluster solo ve al vCenter Server > Menu > Workload Management > Namespaces > Supervisor Cluster kubectl vsphere login --insecure-skip-tls-verify --server [IP_SupervisorCluster] --vsphere-username administrator@vsphere.local) Ahora vamos a elegir el contexto que tiene nuestro despliegue de napp, que debería ser napp-ns-default y para ello usamos el siguiente comando kubectl config use-context [context_name]
Vamos a validar las versiones compatibles de TKR disponibles en la Libreria de contenido unida a dicho namespace, con el siguiente comando kubectl get tkr Acá podemos apreciar que el NAPPA ha publicado en la librería de contenido tres imágenes, entre ellas la imagen de 1.27.6+vmware.1-fips.1-tkg.1 que es superior y compatible. Pero en el momento del despliegue ha usado la 1.23.8+vmware.3-tkg.1, lo cual es una pena porque ahora nos toca subir el Guest Cluster hasta llegar a esa version o una superior compatible de acuerdo con la matriz de interoperabilidad.
Nota: Durante el despliegue, NAPPA configura una librería de contenidos llamada NSX Content Library en el vCenter, con esas tres imágenes. Sin embargo, no podemos hacer el salto desde la v1.23.x hacia la v1.27.x como ya lo mencionamos antes, así que tendremos que cargar las imágenes a dicha librería.
Para descargar y subir a la librería de contenidos las imágenes que nos faltan debemos ir a la siguiente URL https://wp-content.vmware.com/v2/latest/lib.json o también podríamos crear una nueva Content Library Subsribed con la siguiente URL https://wp-content.vmware.com/v2/latest/lib.json y conectar el namespace con esa librería.
En este caso vamos a usar la primera opción y nuestro primer salto será hacia la versión v1.24.x En el repositorio vemos dos imágenes pero vamos a seleccionar la que se llama ob-22036247-tkgs-ova-photon-3-v1.24.11---vmware.1-fips.1-tkg.1 y que por supuesto sea compatible, de acuerdo con la matriz de interoperabilidad.Así que hacemos clic en ella y luego sobre photon-ova.ovf clic derecho para copiar el link
Vamos ahora a la librería de contenidos NSX Content Library > Actions > Import Library Item y seleccionamos la opción URL, donde vamos a pegar el link copiado anteriormente. Nota: En el item name, recomiendo colocarle el mismo nombre que tiene en el portal de descarga para que sea fácil identificarla.
Clic en IMPORTAR y esperamos que se descargue Repetir los pasos para las siguientes imágenes que seran los saltos graduales:
La Content Library debería verse de la siguiente forma. Recordemos que las imágenes que hemos seleccionado han sido selecionadas teniendo en cuenta la matriz de interoperabilidad entre NSX intelligence y Tanzu Kubernetes Releases. Ahora si lanzamos nuevamente el comando kubectl get tkr, las imágenes que hemos cargado deberían mostrarse con true en la columna READY y COMPATIBLE. OJO! No deberíamos aplicar ninguna imagen que no cumpla con estas condiciones.
Ahora lanzamos el siguiente comando para ver la siguiende versión disponible del cluster de kubernetes y el nombre del Guest Cluster que vamos a intervenir. kubectl get tanzukubernetescluster
Listamos los Tanzu Kubernetes releases kubectl get tanzukubernetesreleases
Ejecutamos el siguiente comando para editar el manifest de Guest Cluster kubectl edit tanzukubernetescluster/CLUSTER-NAME Aqui vamos a editar unicamente las lineas de las referencias para el controlplane y nodePools que aparecen dentro del objeto topology
Verifique en la salida del comando kubectl indique que la edición del manifiesto se realizó correctamente
Verifique con el siguiente comando que el Guest Cluster se este actualizando kubectl get tanzukubernetescluster Nota: En la salida del comando vemos que la columna READY dice False debemos esperar a que aparezca True. La paciencia es la clave, esto puede tomar hasta 30 min.
Una vez actualizada debería verse de la siguiente forma
Repetimos los pasos 8 a 11 hasta llegar a la versión de destino. Por ejemplo nuestro siguiente salto sera ala version v1.25.13---vmware.1-fips.1-tkg.1 y asi susesicamente. Sin embargo, antes de hacerlo lee las siguientes notas importantes.
Al finalizar deberíamos ver la versión de distribución de la siguiente manera
Notas importantes
Nota 1: Podemos monitorear el proceso desde napp-ns-default > Monitor
O en napp-ns-default > Compute debemos esperar hasta que la columna Phase pase de Updating a Running. Sin embargo, cuando aparece Running no indica que ya ha terminado. Aún podemos ver eventos y tareas corriendo en el inventario.
Nota 2: Durante cada salto de actualización veremos como se crean nodos adicional mientras ocurre el proceso. La actualización comienza por los nodos del Control Plane y despues en los nodos Worker. Es importante que antes de iniciar con el siguiente salto, verifiquemos no se encuentren tareas en ejecución, que la cantidad de nodos en el inventarios sea la correcta, en mi caso del LAB debería tener únicamente un Control Plane node y un Worker Node. En el siguiente pantallazo vemos un nodo de más, es decir que aún no ha terminado.
Una vez terminan todas las actividades, vamos a ver que el numero de nodos para el Guest Cluster en el inventario es el correcto. Sin embargo, aún debemos esperar que la solucion del NAPP se estabilice.
Nota 3: Debemos esperar que la solución de NSX Application Platform se muestre estable desde la consola de NSX. Esto puede tardar algunos minutos.
Nota 4: Si utilizamos la opción de Troubleshooting del NAPPA (NSX Application Platform Automation Appliance), podemos ver el momento en el que todos los Pods estén arriba.
o podemos usar el comando napp-k get pods -A
Screenshots de referencia para los actualizaciones (saltos) adicionales.
Salto a v1.25.13---vmware.1-fips.1-tkg.1
Salto a v1.26.12---vmware.2-fips.1-tkg.2
Salto a v1.27.10---vmware.1-fips.1-tkg.1
Actualizar Kubernetes Tools
Una vez hemos terminado con las actualizaciones y nos encontremos ahora en una versión compatible de acuerdo con la matriz de interoperabilidad de NSX Intelligence. Es probable que vea la siguiente alerta en la interface. Si estas en una version superior a NSX 4.1.2.2 seguramente no te va a salir esta alerta.
Server version v1.27.10+vmware.1-fips.1 and client version v1.23.3 are incompatible. Please upload Kubernetes Tools to resolve.
¡Y eso es todo amigos! Con este procedimiento vas a poder darle mantenimiento al cluster de Kubernetes (K8s) desplegado como parte de la solución NSX Application Platform (NAPP).
¡IMPORTANTE! He migrado blog del dominio nachoaprendevirtualizacion.com a nachoaprendeit.com. Si te ha servido este artículo deja tu buen Like y compártelo con tus colegas, estas aciones me ayudarán a optimizar los motores de búsqueda para llegar a más personas.
TODOS LOS NOMBRES DE VMS USADOS EN ESTE BLOG SON INVENTADOS Y OBEDECEN A UN AMBIENTE DE LABORATORIO PROPIO, UTILIZADO PARA FINES DE ESTUDIO.
If you have deployed NSX Application Platform (NAPP) using the latest version of NAPPA (NSX Application Platform Automation Appliance) and upon completion of the deployment you notice that the Guest Cluster supporting the NAPP solution is on a TKR (Tanzu Kubernetes release) version of v1.23.8, this post is for you, and I will explain how to resolve it in under 3 minutes.
Well, if you’re here, it’s because you’ve already realized that even though you’re using the latest version of NAPPA, it is deploying the Guest Cluster in an unsupported version (v1.23.8).
The bad news is that it is a reported issue with the NAPPA tool (version 4.2), which, although it has three images of TKR incorporated and loads them into the content library, ends up choosing version v1.23.8 instead of v1.27.6, even though both were shown as COMPATIBLE.
Solutions
At this point, you have two options: update from TKR v.1.23.8 until you reach at least v1.26.5, although I would recommend going for v.1.27.6. I will be posting an article for that update soon, so don’t miss it!
The other option, which is smarter and requires less effort, is to remove the deployment using the CLEANUP function of NAPPA to redeploy it while keeping in mind some considerations that I will explain later.
If you decided to remove the deployment, go to NSX Application Platform Automation Appliance, proceed next to the wizard until you reach the end. This is where your deployment should have finished; start from the last stage of deployment > Deploy NAPP and click on CLEANUP.
Note: If you had already activated any NAPP service with NSX Intelligence, go to the NSX graphical interface and click on remove that service; otherwise, it will not let you delete the deployment. Once the service is removed, it should look like the following image.
After doing the same (CLEANUP) in the Deploy TKGs stage. This will remove the deployment of NAPP and vSphere With Tanzu from your environment to simply redeploy it.
WARNING! Do this only if you have deployed vSphere With Tanzu using the NAPPA and only for the purpose of the NAPP.
At this point, you have only made a couple of clicks to remove the deployment, which is why it is my preferred option.
Now you just need to update NSX to version 4.1.2.2 or higher and relaunch the NAPP. This update is very straightforward; moreover, it will help you to get rid of one or two vulnerabilities that you might have in the environment.
In my case, I upgraded from NSX version 4.1.2.1 to version 4.1.2.5.
Here you just need to restart the NAPPA assistant from the beginning; the good news is that all the data is already preloaded, you just have to re-enter a couple of passwords.
If all has gone well, you should now have the Guest Cluster deployed that supports the NSX Application Platform (NAPP) in the supported and compatible version (v1.27.6).
And that’s all, friends! With this, we confirm that when we have a version of NSX higher than 4.1.2.2, the guest cluster is deployed with version v1.27.6.
ALL VM NAMES USED IN THIS BLOG ARE FICTITIOUS AND RELATE TO A CUSTOM LAB ENVIRONMENT USED FOR STUDY PURPOSES.
IMPORTANT! I have migrated the blog from the domain nachoaprendevirtualizacion.com to nachoaprendeit.com. If you found this article helpful, please give it a Like and share it with your colleagues; these actions will help me optimize search engines to reach more people.
Si estas desplegado NSX Application Platform (NAPP) utilizando la ultima versión de NAPPA (NSX Application Platform Automation Appliance) y al finalizar el despliegue vez que el Guest Cluster que soporta la solución de NAPP esta en una versión de TKR (Tanzu Kubernetes release) v1.23.8. Este post es para ti, y te explico en menos de 3 minutos como solucionarlo.
Pues bien, si estas acá es porque ya te diste cuenta que aunque estas usando la última versión del NAPPA, te esta desplegando el Guest Cluster en una versión fuera de soporte (v1.23.8).
La mala noticia es que es un issue reportado de la herramienta NAPPA (versión 4.2), que aunque tiene incorporadas tres imágenes de TKR y las carga en la librería de contenido, termina eligiendo la versión v1.23.8 y no la v1.27.6, aunque las dos se mostraban como COMPATIBLE.
Soluciones
En este punto tienes dos opciones, hacer actualizaciones desde la TKR v.1.23.8 hasta llegar mínimo a la v1.26.5 aunque yo recomendaría mejor la v.1.27.6. Estaré publicando un post para esa actualización. Así que, ¡No te lo pierdas!
O la otra opción, más inteligente y con menos esfuerzo, es eliminar el despliegue usando la función de CLEANUP del NAPPA para volverlo a lanzar teniendo algunas consideraciones que te explico más adelante.
Si decidiste eliminar el despliegue, ve a NSX Application Platform Automation Appliance, next a el wizard hasta llegar al final, aquí fue donde debió haber terminado tu despliegue, comienza por la última etapa del despliegue > Deploy NAPP y clic en CLEANUP
Nota: Si ya habías activado algún servicio del NAPP con NSX Intelligence, ve a la interface gráfica de NSX y haz clic en eliminar a ese servicio, de lo contrario no te va dejar eliminar el despliegue. Una vez eliminado el servicio, debe lucir como en la siguiente imagen.
Después hacer lo mismo (CLEANUP) en la etapa Deploy TKGs. Esto eliminará el despliegue de NAPP y vSphere With Tanzu de tu ambiente para simplemente volver a lanzarlo.
¡OJO! Hacer esto solo si has desplegado el vSphere With Tanzu usando el NAPPA y solo para el propósito del NAPP.
En este punto solo has hecho un par de clics para eliminar el despliegue, por eso es mi opción preferida.
Ahora solo tienes que hacer un update de NSX a la version 4.1.2.2 o superior y volver a lanzar el NAPP. Esta actualización es muy sencilla, además te va a ayudar a librarte de una que otra vulnerabilidad que puedas tener en el ambiente.
En mi caso pasé de la versión de NSX 4.1.2.1 a la version 4.1.2.5
Aquí ya solo debes volver a lanzar el asistente del NAPPA desde el principio, la buena noticia es que todos los datos ya aparece precargados, solo tienes que reingresar un par de passwords.
Si todo ha salido bien, deberías tener ahora desplegado el Guest Cluster que soporta la solución de NSX Application Platform (NAPP) en la versión soportada y compatible (v1.27.6).
¡Y eso es todo amigos! Con esto comprobamos que, cuando tenemos una versión den NSX superior a 4.1.2.2. El guest cluster se despliega con la versión v1.27.6.
TODOS LOS NOMBRES DE VMS USADOS EN ESTE BLOG SON INVENTADOS Y OBEDECEN A UN AMBIENTE DE LABORATORIO PROPIO, UTILIZADO PARA FINES DE ESTUDIO.
¡IMPORTANTE! He migrado blog del dominio nachoaprendevirtualizacion.com a nachoaprendeit.com. Si te ha servido este artículo deja tu buen Like y compártelo con tus colegas, estas aciones me ayudarán a optimizar los motores de búsqueda para llegar a más personas.
En el post anterior explicamos como realizar este mismo procedimiento con Gmail y ahora es el turno de explicarlo con Outlook que de igual forma debido a las mejoras en seguridad aplicadas por Microsoft se hace necesario utilizar ahora la funcionalidad llamada Contraseñas de Aplicaciones que como su nombre lo indica es una contraseña que generamos para permitir el acceso desde nuestro aplicativos a nuestra cuenta Outlook.
Dicho lo anterior, en esta oportunidad vamos a explicar entonces cómo podemos utilizar una cuenta de Outlook como SMTP Server de la solución VMware Aria Automation (antes vRealize Automation) para habilitar las notificaciones del servicio de Service Broker.
PROCEDIMIENTO
Ingresar a la cuenta Outlook que utilizaremos para ser configurada como SMTP server de Aria Automation. Sino tiene una puede crearla desde la pagina oficial de Outlook
Una vez dentro de la cuenta vamos a la parte superior derecha en donde aparece el nombre de usuario de la cuenta, hacemos click y después click en My Profile*
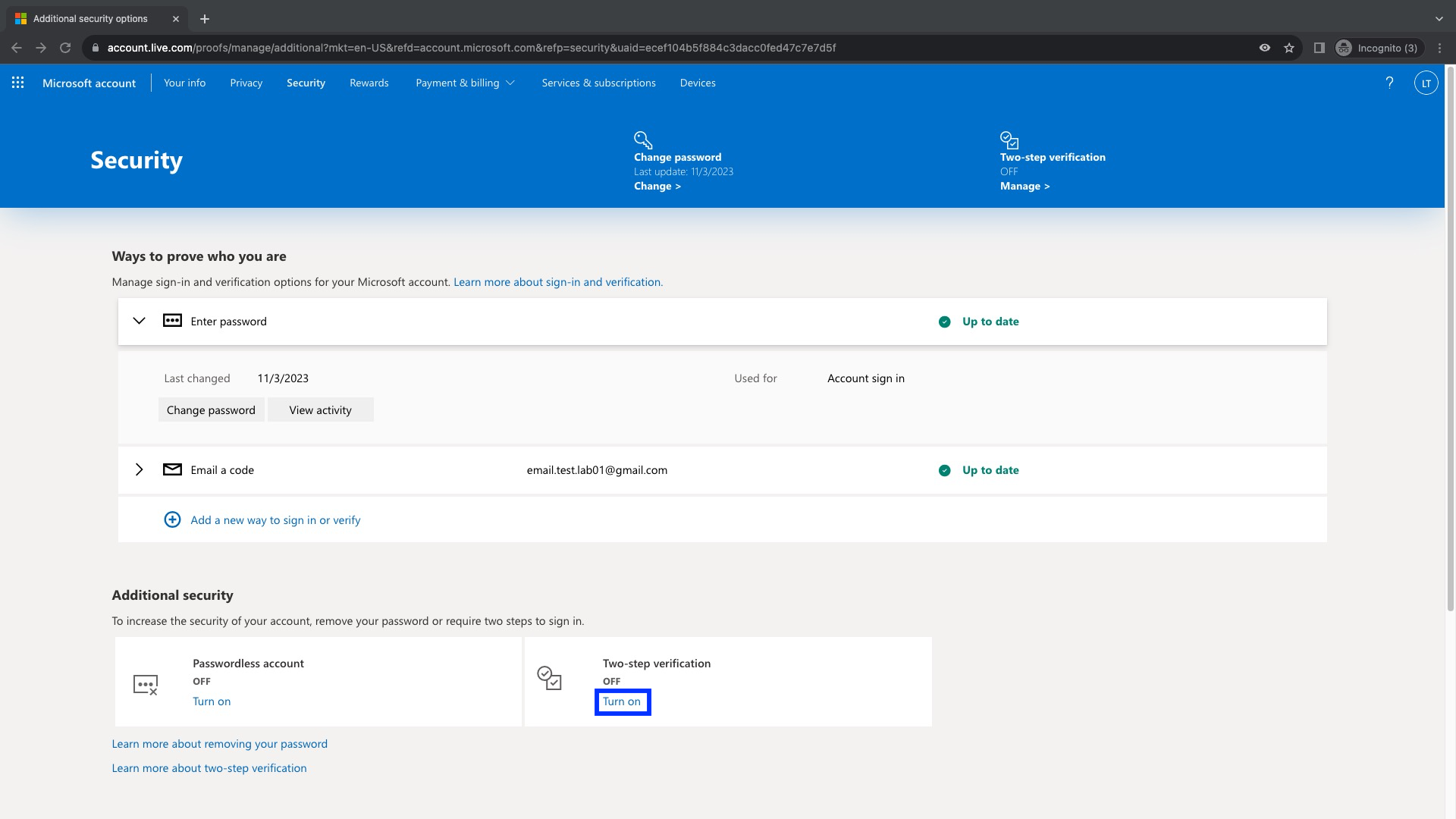
Después debemos hacer click en Security para posteriormente hacer click sobre el link Get Started, que se encuentra dentro de la sección Advanced security options
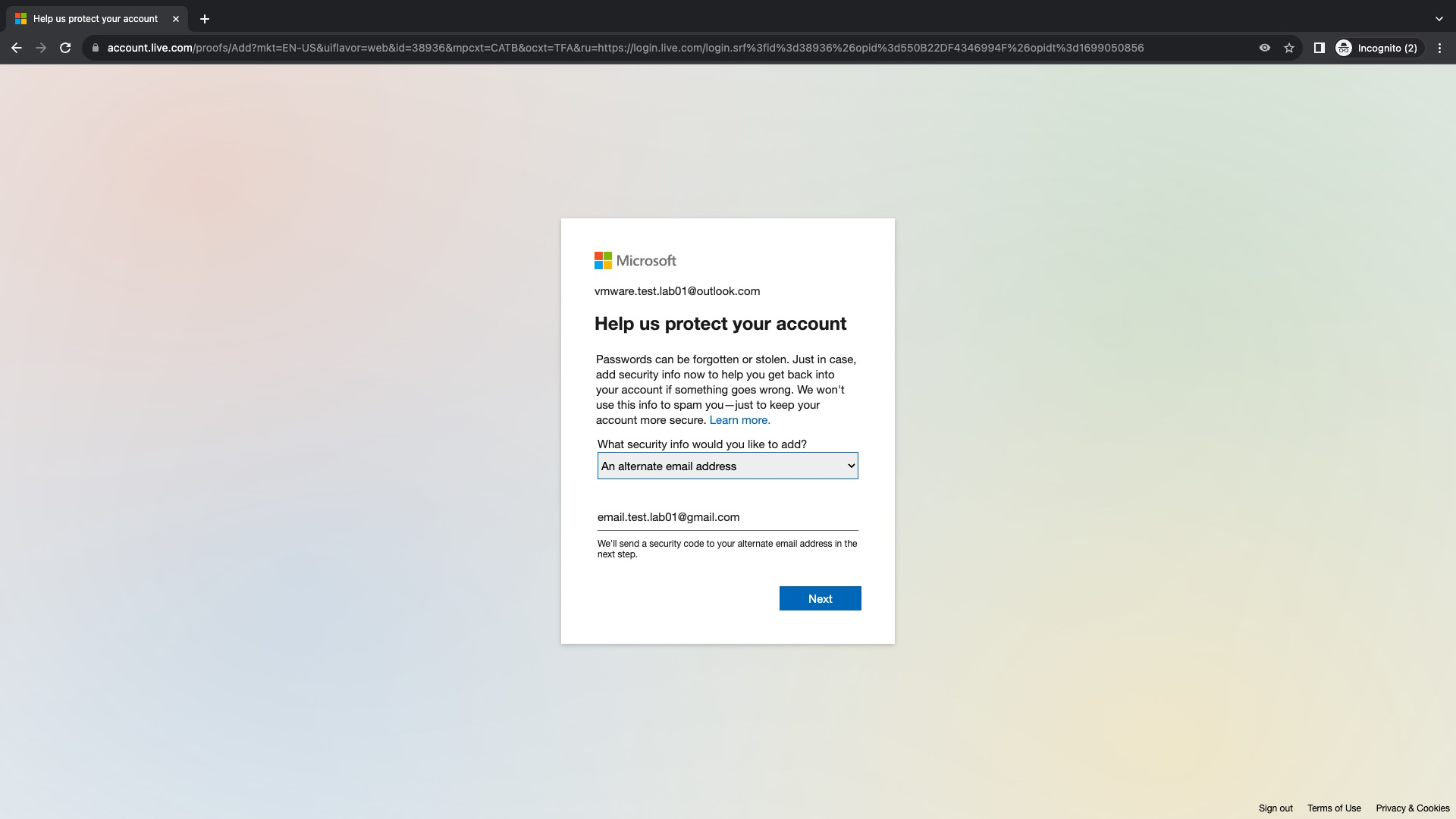
Si la cuenta es nueva, Microsoft nos solicita configurar una opción de seguridad para ayudarnos a proteger nuestra cuenta y para esto tenemos dos opciones An alternate email address o A phone number. En este caso he seleccionado la primera y he agregado una cuenta de gmail. Ahora hacemos click en Next
Ingresamos el código que nos debió haber llegado a nuestra cuenta de correo o teléfono especificada y después click en Next
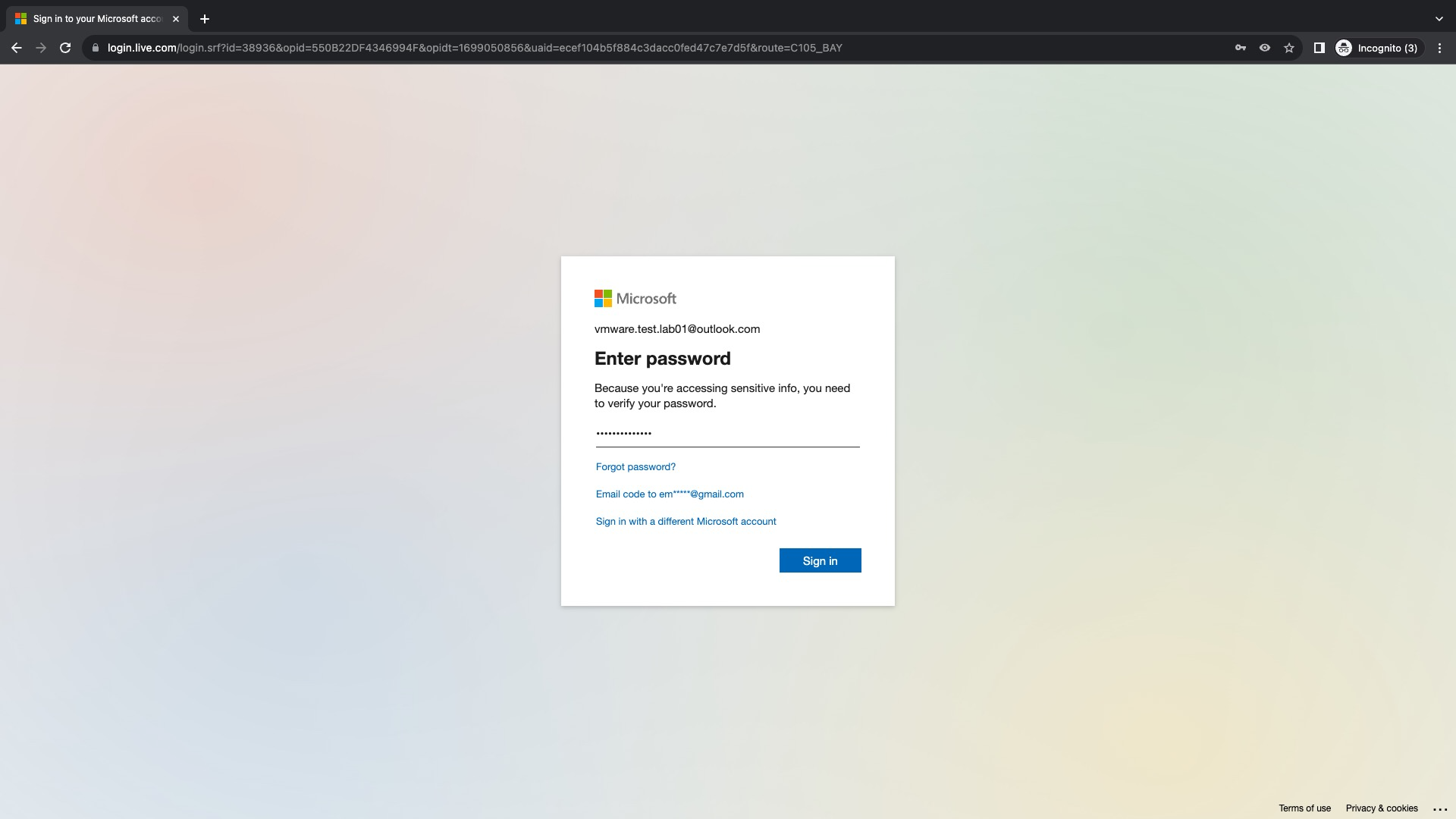
A continuación debemos ingresar el password de la cuenta debido a que estamos accediendo a información sensible y después click en Sign In
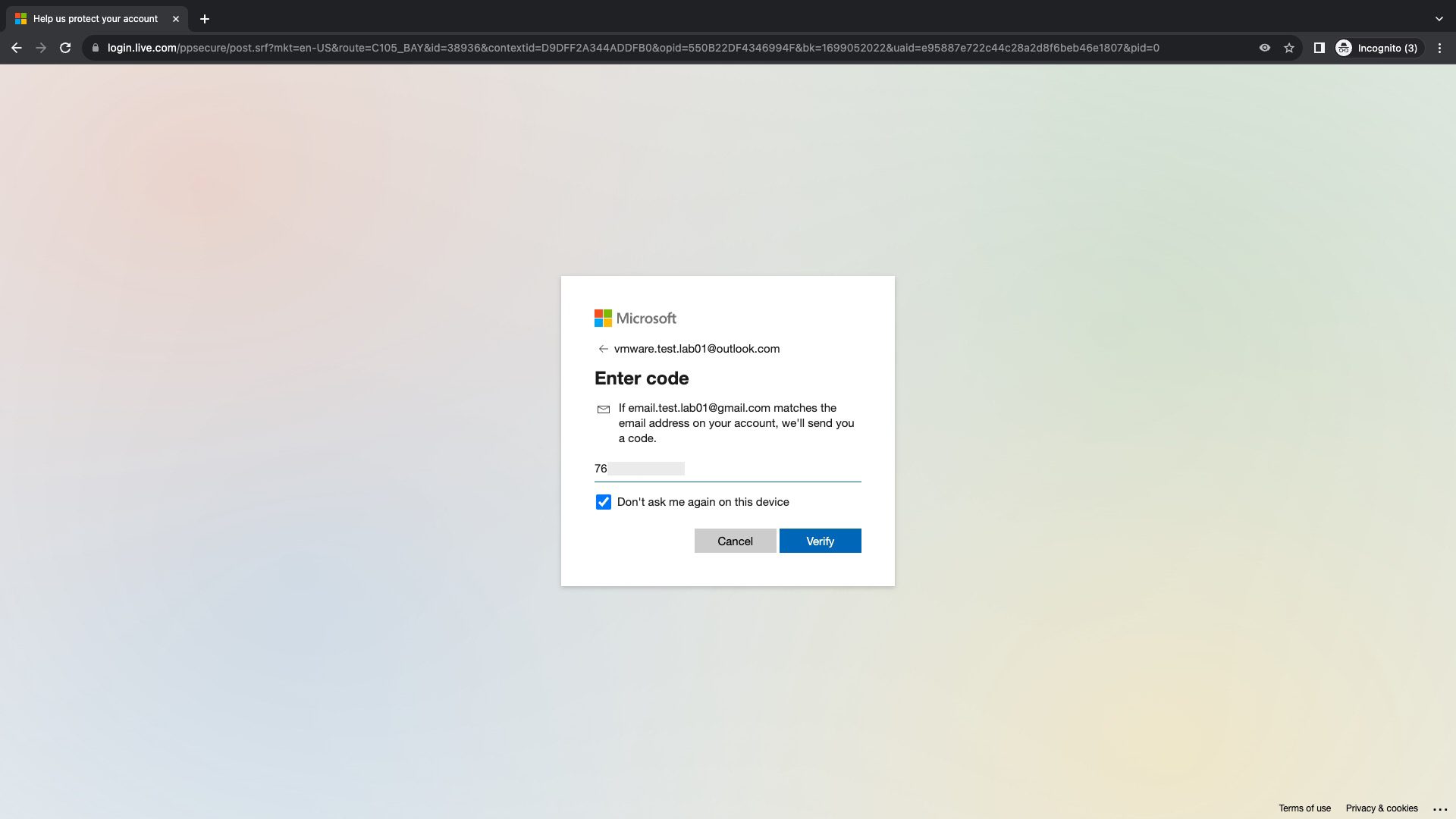
Debemos ahora verificar nuestra identidad en la cuanta de correo que agregamos en el paso anterior haciendo clic en el nombre de la cuenta
Ingresamos la cuenta de correo completa que se muestra enmascarada para verificar que es nuestra cuenta y que conocemos los datos. Recordar que este caso configuramos una cuenta alterna de gmail, razón por la cual esta validación la vamos a hacer desde la cuenta de gmail. Estos pasos de verificación puede ser diferentes si seleccionamos A phone number en el paso anterior. Click en Send code para recibir el código en la cuenta de email especificada.
Ingresamos el código de verificación que nos llegó y click en Verify
En este punto podemos hacer click en el link No gracias para no configurar una App que nos permita ingresar sin password.
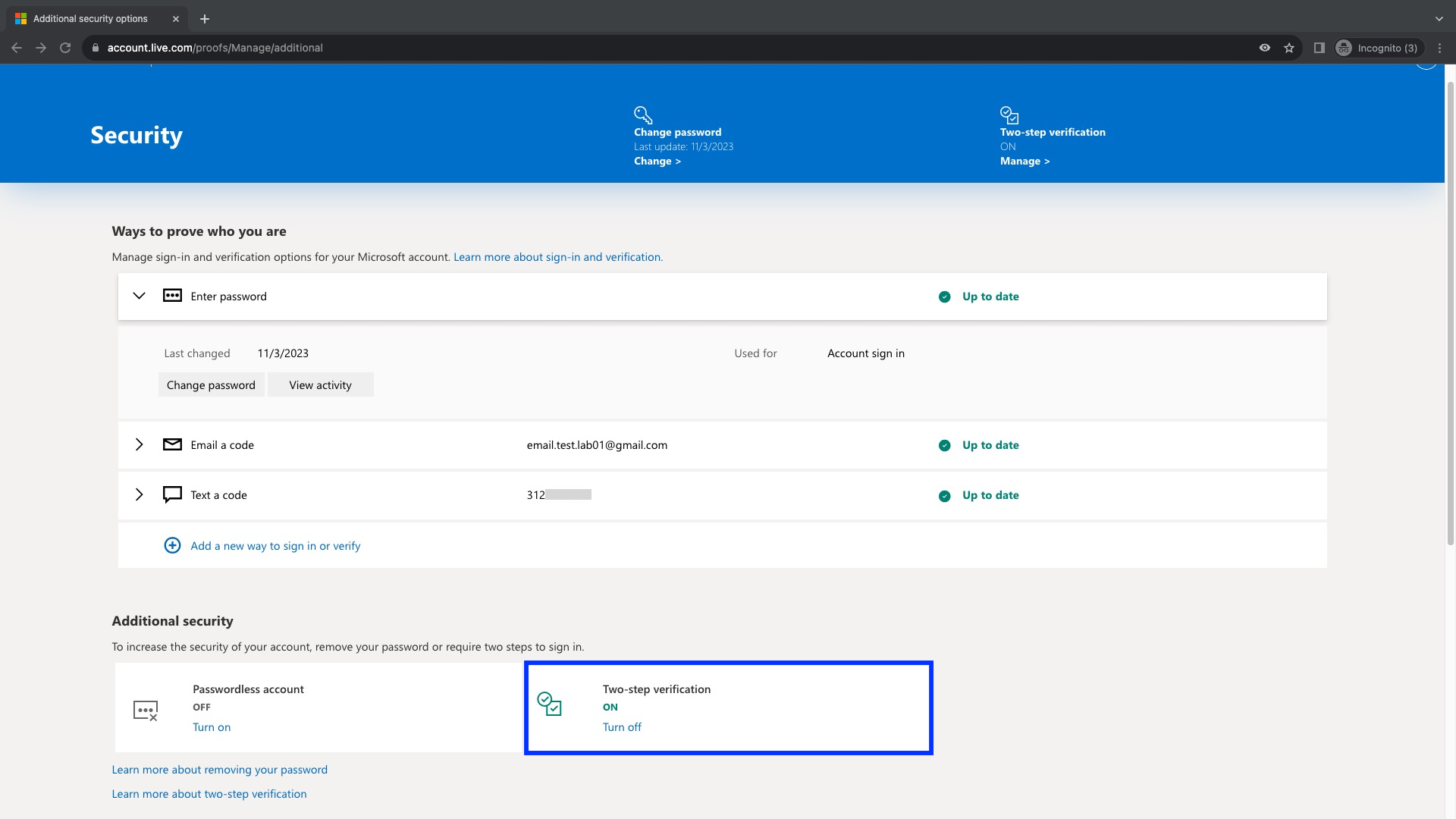
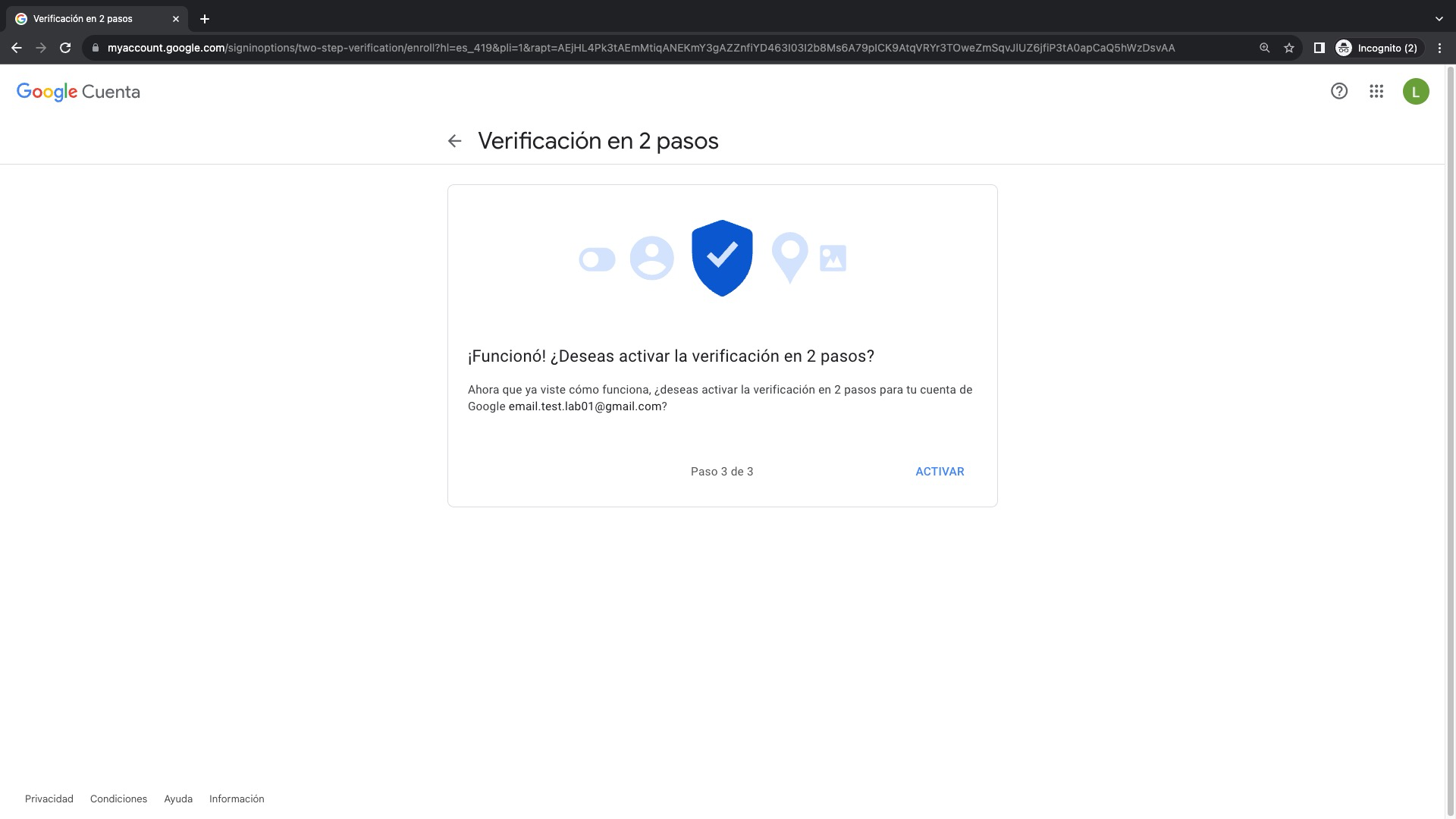
Ahora, un paso muy importante para poder utilizar las Contraseñas de aplicación es que debemos activar la Verificación en 2 Pasos haciendo click en Turn On que se encuentra bajo la sección Additional security
Leemos detenidamente en que consiste la verificación en 2 pasos y click en Next
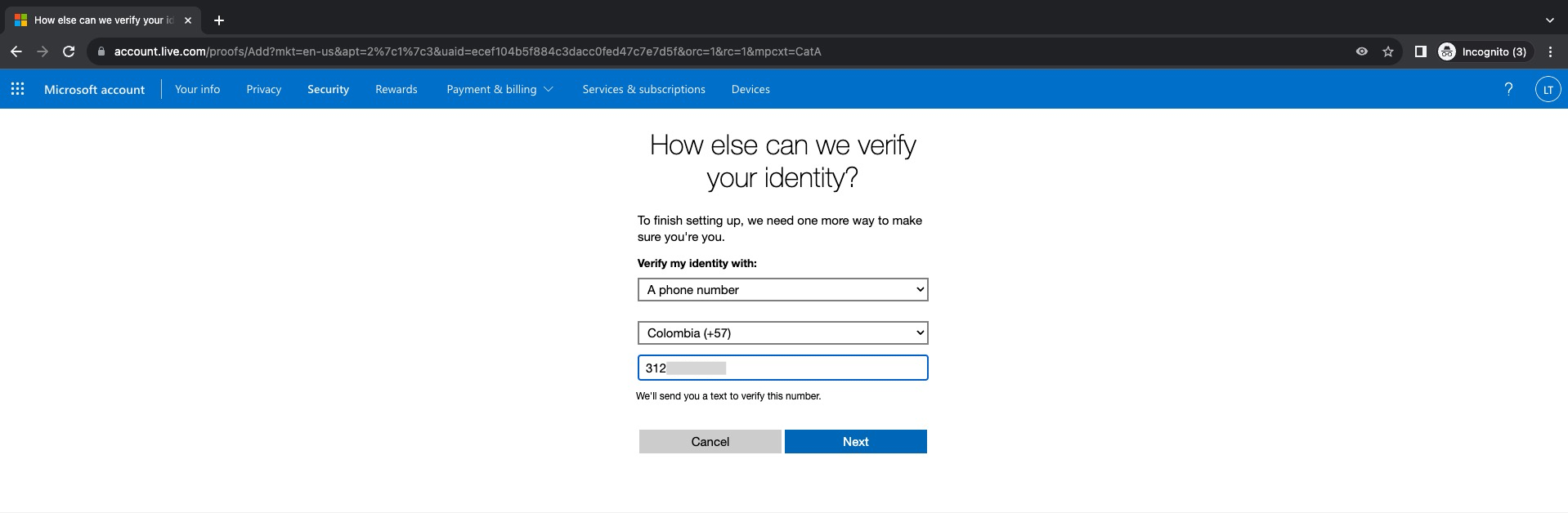
Debemos ahora definir una opción para verificar nuestra identidad, en este caso al igual que lo como lo hicimos en Gmail seleccionaremos A phone number e ingresamos el numero de teléfono
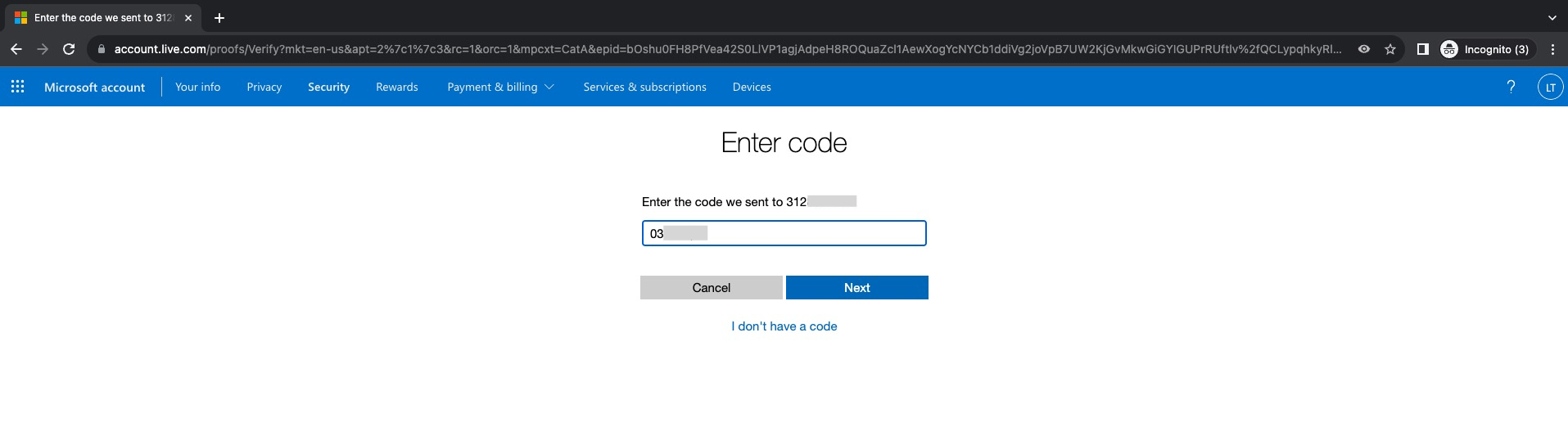
Ingresamos el código que nos debió haber llegado a nuestro teléfono y después click en Next
15. Si el código es correcto deberíamos ver que la Verificación en 2 pasos ha sido activada y un código has sido generado para efectos de recuperación. Guarde este código en un lugar seguro y no lo comparta. Click en Next
16. En Set up your smart phone with an app password click en Next
En Some other apps and devices need an app password too click en Finish
Ahora podemos ver que la verificación en 2 pasos ha sido activada para esta cuenta
En la pestaña donde estamos debemos hacer el down para ubicar la sección App passwords (Contraseñas de Aplicaciones) y hacemos click en el link Create a new app password
Ingresamos la contraseña de la cuenta outlook para poder ingresar a esta opción
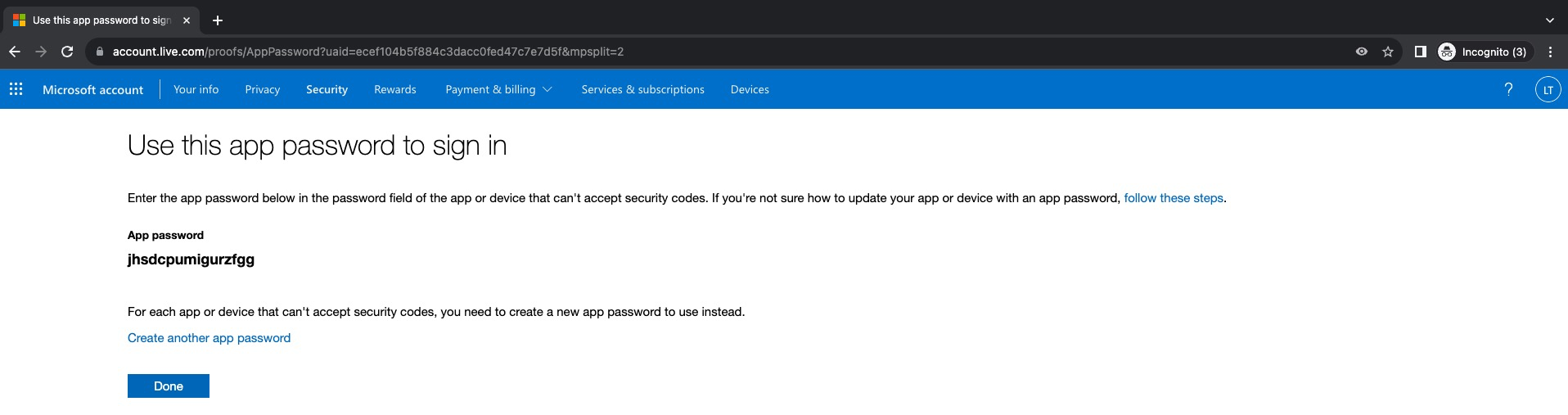
A continuación una Contraseña de Aplicaciones se ha creado y este será el password que debemos utilizar para la integración con Aria Automation o cualquier solución de VMware. Click en Done para terminar
Vamos ahora a realizar la configuración en el servicio de Service Broker de Aria Automation, para esto hacemos login en la solución y en el menu principal hacemos click en **Service Broker
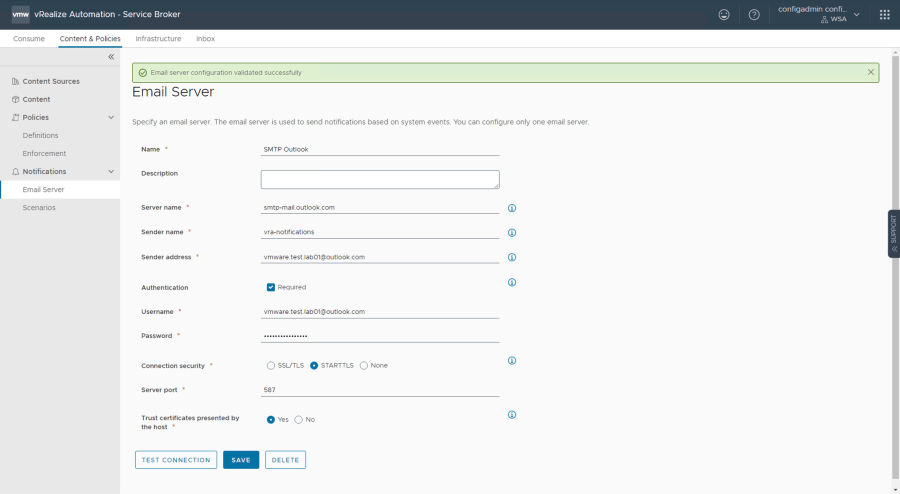
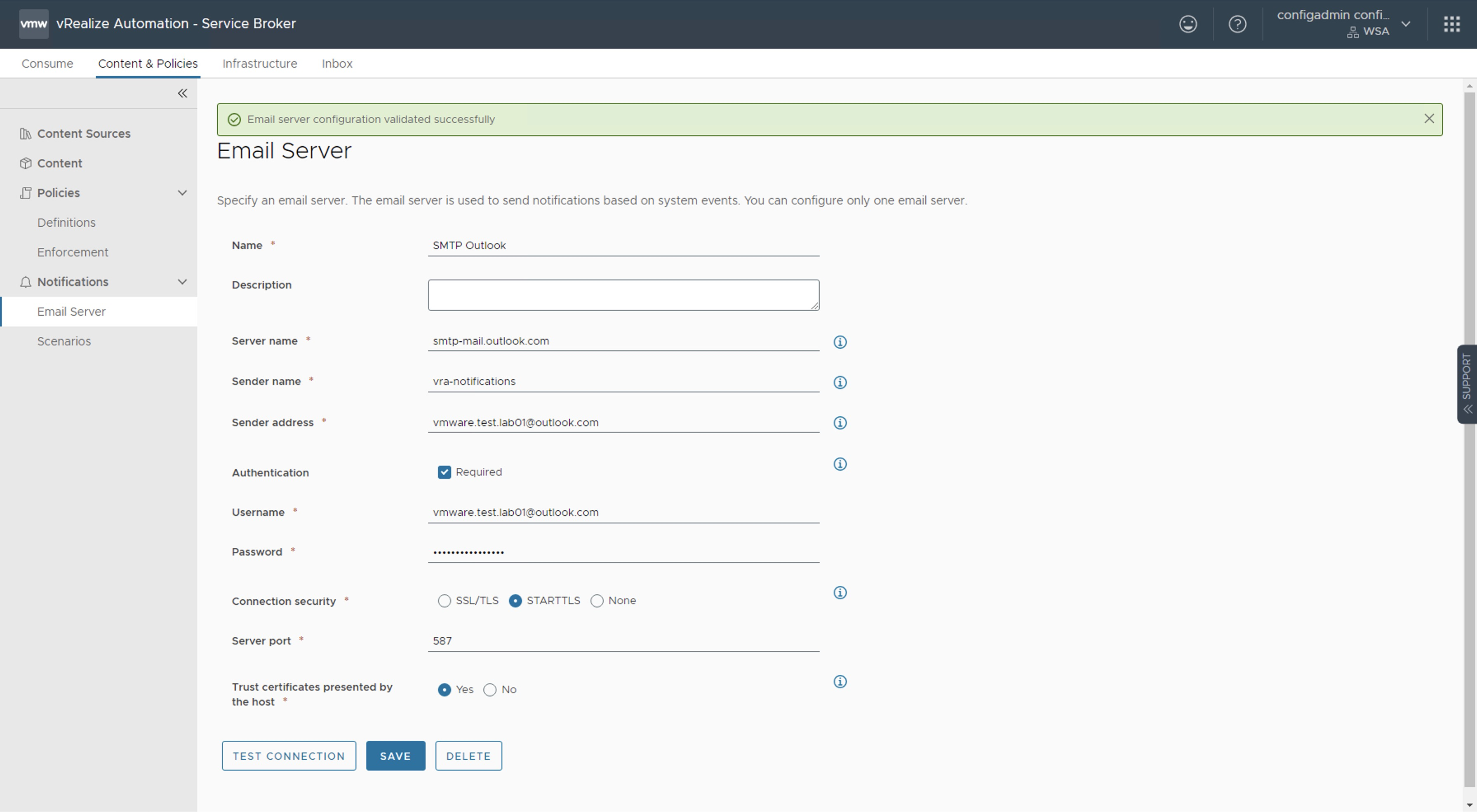
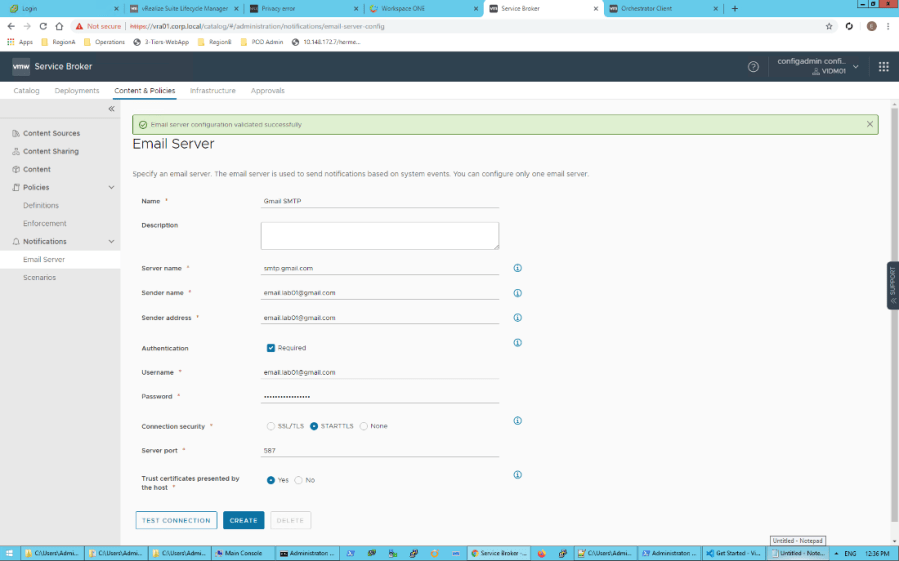
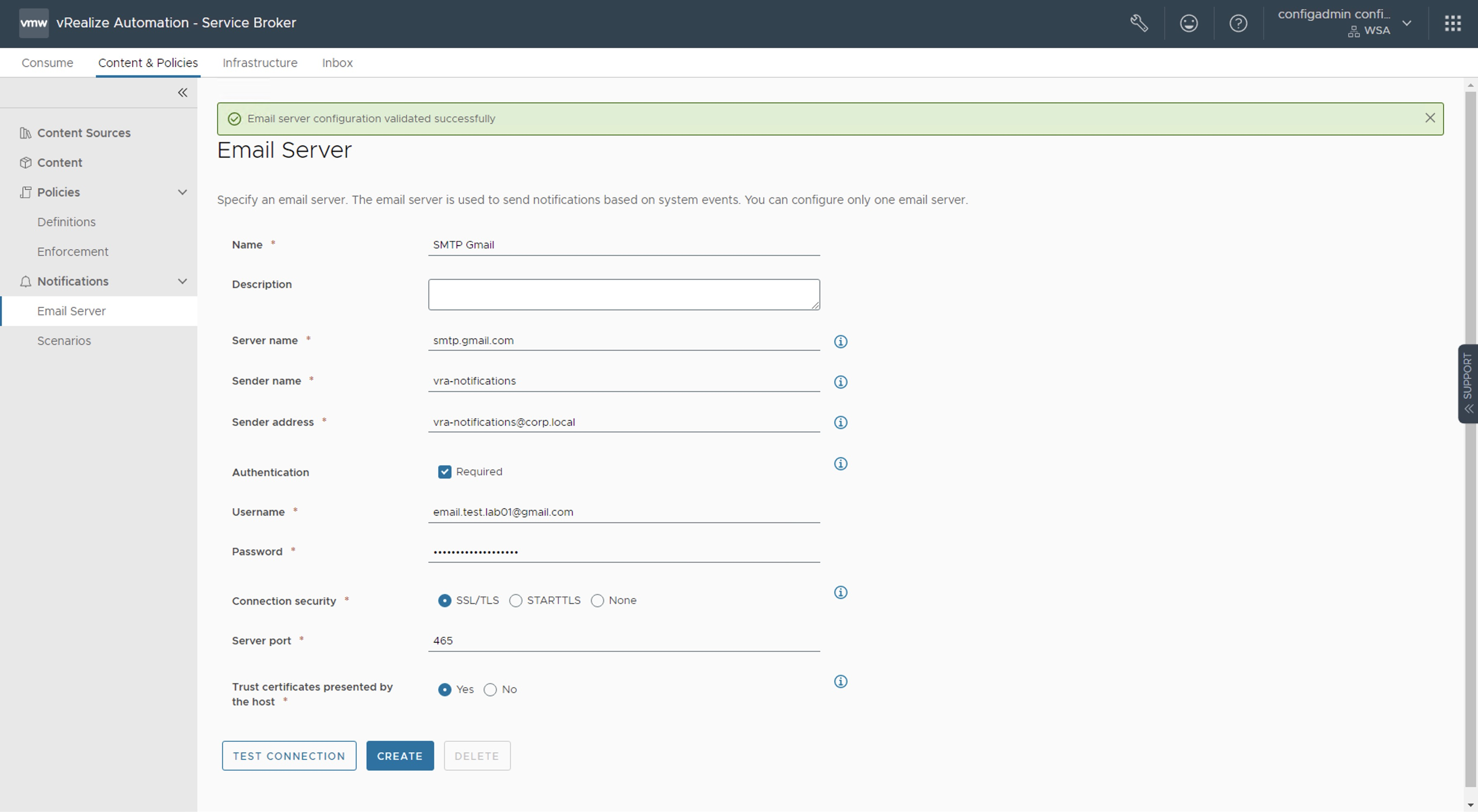
Después vamos a Content & Policies -> Notifications -> Email Server. Llenamos los datos como sigue y después click TEST CONNECTION. Si la conexión ha sido exitosa, entonces click en CREATE
Los datos importantes aquí son los siguientes:
Server Name: smtp-mail.outlook.com Sender Name: Alias para el emisor de la notificación Sender Address: vmware.test.lab01@outlook.com (a diferencia de la configuración con Gmail esta si debe ser una cuenta válida) User Name: vmware.test.lab01@outlook.com (cuenta de email creada) Password:jhsdcpumigurzfgg (La contraseña de aplicaciones creada en el paso anterior) Connection Security: STARTLS Server port: 587 Trust certificates presented by the host: Yes
Nota: La ruta para llegar hasta Notifications -> Email Server podría ser diferente dependiendo de la version.
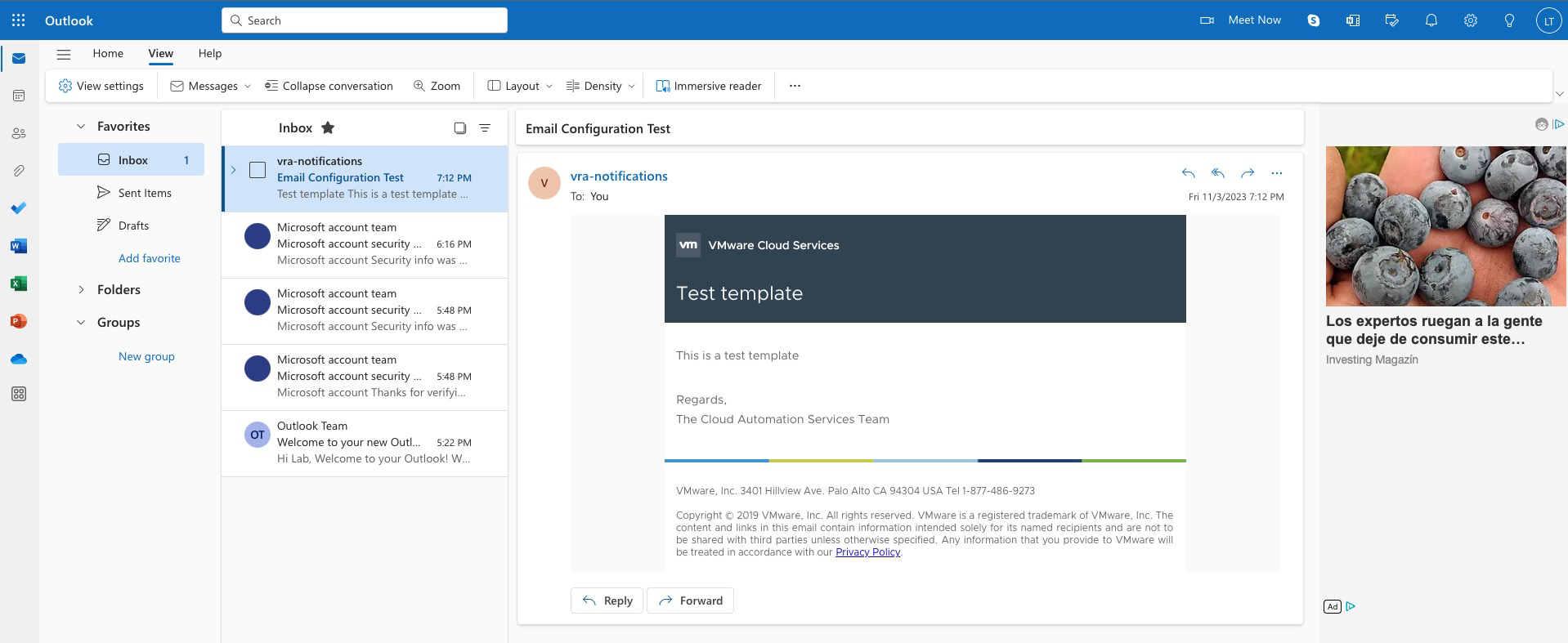
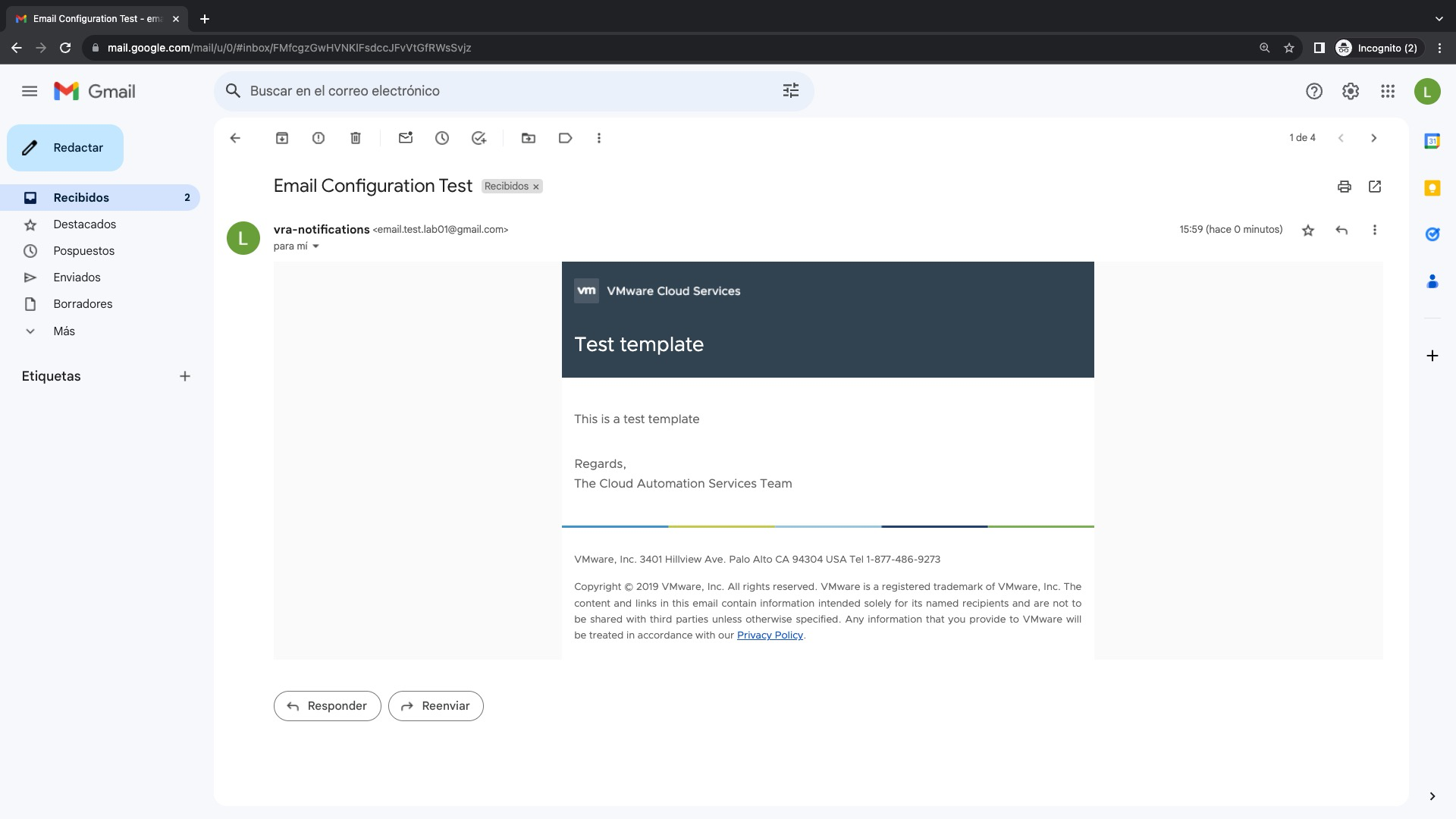
Nota: Al hacer click sobre el botón TEST CONNECTION deberíamos ver un banner color verde con el mensaje Email server configuration validated successfully
Como resultado del TEST CONNECTION recibiremos ademas un correo electrónico en la cuenta email configurada para el usuario con el cual estamos haciendo el TEST CONNECTION. Es decir, en este caso estamos logueados en Aria Automation con el usuario configadmin que es un usuario local de Workspace One Access, el cual tiene en su atributo email la cuenta de correo electrónico creada anteriormente.
(Opcional) Para validar o cambiar la cuenta de correo electrónico configurada en un usuario local de Workspace One Access debemos hacer login en la solución con un usuario administrador y después navegar hasta Administration Console
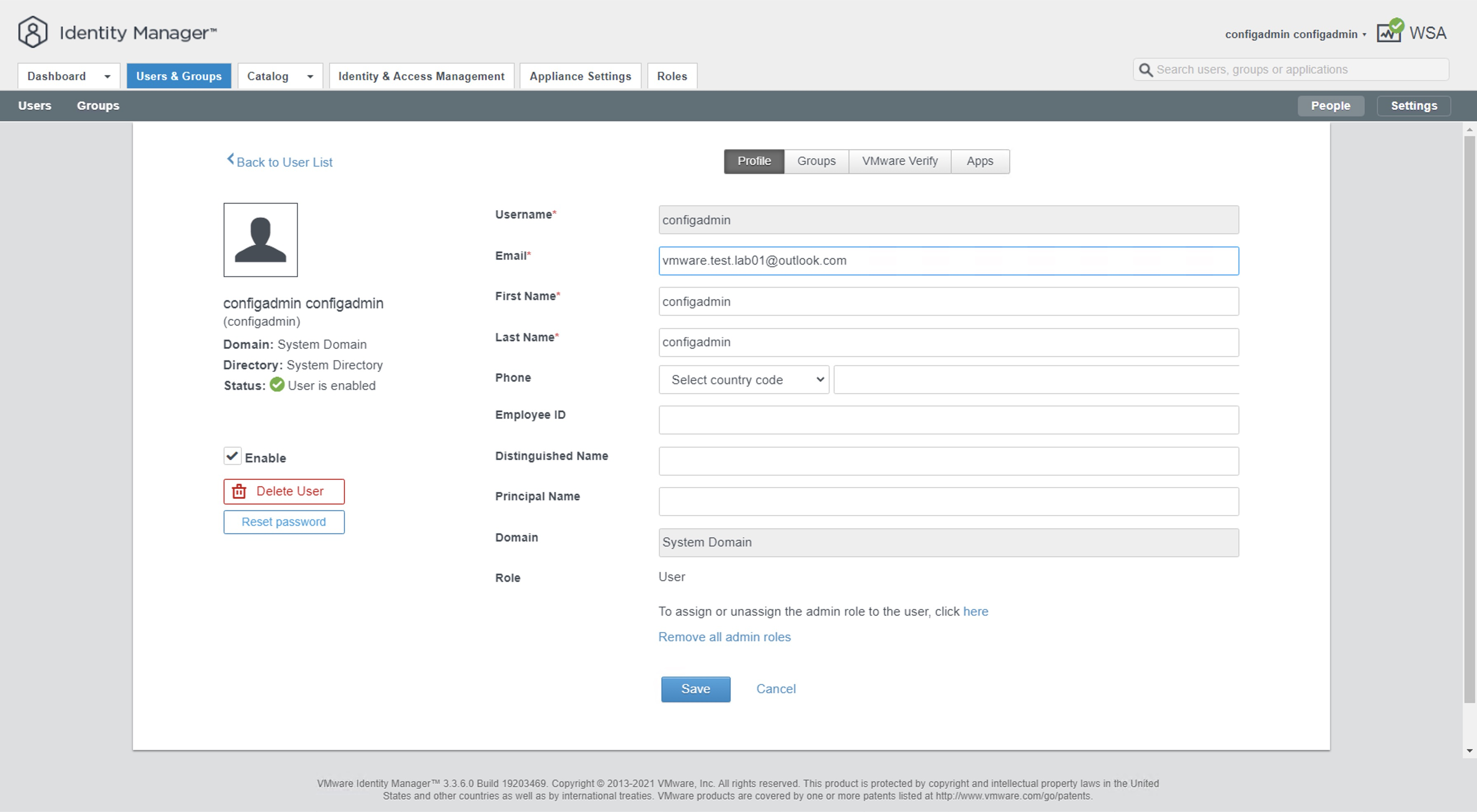
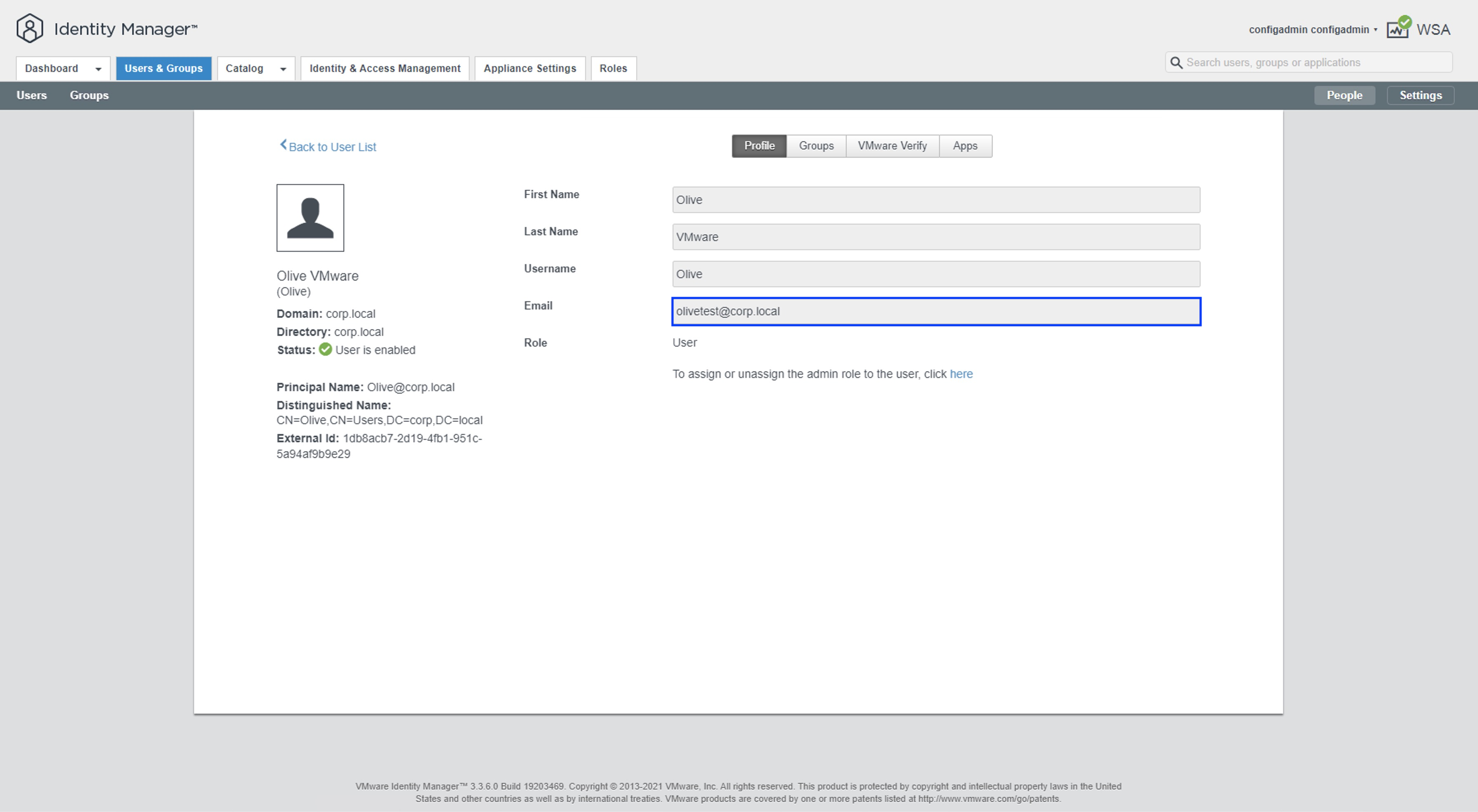
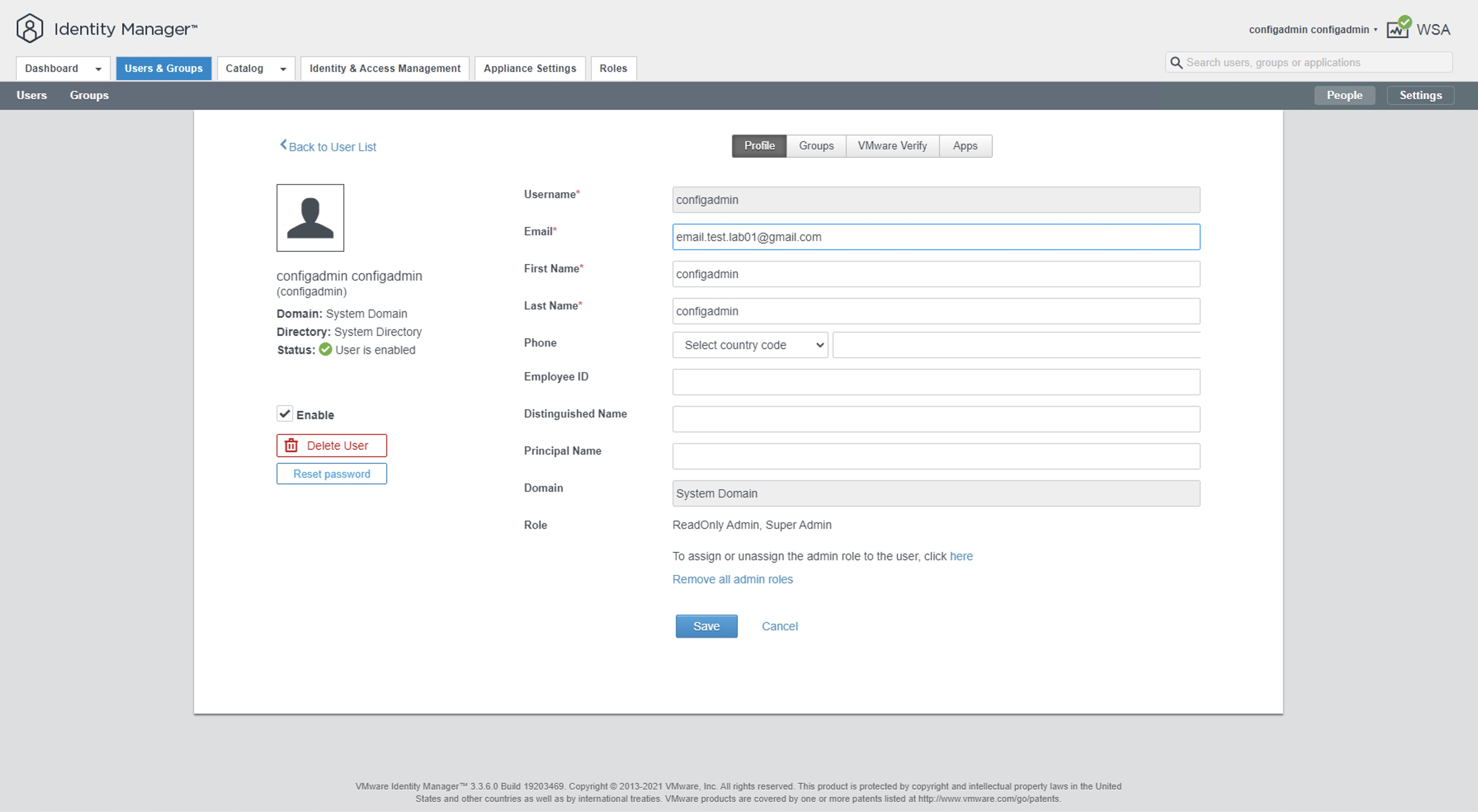
Una vez dentro, podemos navegar hasta la pestaña User & Groups para ver la información de cada uno de los usuarios
Nota: Aquí podemos ver algunos usuarios que son locales (System Domain) y algunos que son de dominio (corp.local). Para los usuarios locales podemos editar el email simplemente haciendo click sobre el usuario y cambiando el valor del campo email.
Nota: En este caso hemos utilizado la cuenta de correo que hemos creado en Outlook, pero podría ser cualquiera.
Por otro lado, para los usuario que son sincronizaos desde el dominio, este campo debe ser editado directamente el Active Directory
Una vez realizados los pasos anteriores, podemos aprovechar las notificaciones que envía Aria Automation Service Broker a los usuario para cada uno de los escenarios indicados en la documentación oficial Send email notifications to Automation Service Broker users
TODOS LOS NOMBRES DE VMS USADOS EN ESTE BLOG SON INVENTADOS Y OBEDECEN A UN AMBIENTE DE LABORATORIO PROPIO, UTILIZADO PARA FINES DE ESTUDIO.
¡IMPORTANTE! He migrado blog del dominio nachoaprendevirtualizacion.com a nachoaprendeit.com. Si te ha servido este artículo deja tu buen Like y compártelo con tus colegas, estas aciones me ayudarán a optimizar los motores de búsqueda para llegar a más personas.
En un post anterior habíamos explicado como realizar este mismo procedimiento. Sin embargo, con las mejoras en seguridad aplicadas por Gmail la opción para permitir Aplicaciones Menos Seguras ya no esta disponible. En consecuencia Gmail ha habilitado una opción para utilizar el SMTP utilizando ahora una funcionalidad llamada Contraseñas de Aplicaciones que como su nombre lo indica es una contraseña que generamos para permitir el acceso desde nuestro aplicativos a nuestra cuenta Gmail.
Dicho lo anterior, en esta oportunidad vamos a explicar entonces cómo podemos utilizar una cuenta de Gmail como SMTP Server de la solución VMware Aria Automation (antes vRealize Automation 8.x) para habilitar las notificaciones del servicio Service Broker.
PROCEDIMIENTO
Ingresar a la cuenta Gmail que utilizaremos para ser configurada como SMTP server de Aria Automation. Sino tiene una puede crearla desde la pagina oficial de Gmail
Una vez dentro de la cuenta vamos a la parte superior derecha en donde aparece el nombre de usuario de la cuenta, hacemos click y después click en Administrar tu Cuenta de Google
Una vez dentro, debemos hacer click en Seguridad para posteriormente hacer click sobre el símbolo > frente a Verificación en 2 pasos, que se encuentra dentro de la sección Cómo acceder a Google
Leemos detenidamente en que consiste la Verificacion en 2 pasos y hacemos click en el botón Comenzar
Definimos un numero de teléfono para la verificación y escogemos la opción que deseemos para recibir los códigos. En este caso dejare la default Mensaje de texto y click en Siguiente
Ingresamos el código que nos debió haber llegado a nuestro celular y después click en Siguiente
Si el código es correcto deberíamos tener el siguiente mensaje y hacemos click en el botón Activar
Una vez activada la Verificacion en 2 pasos debe verse de la siguiente manera.
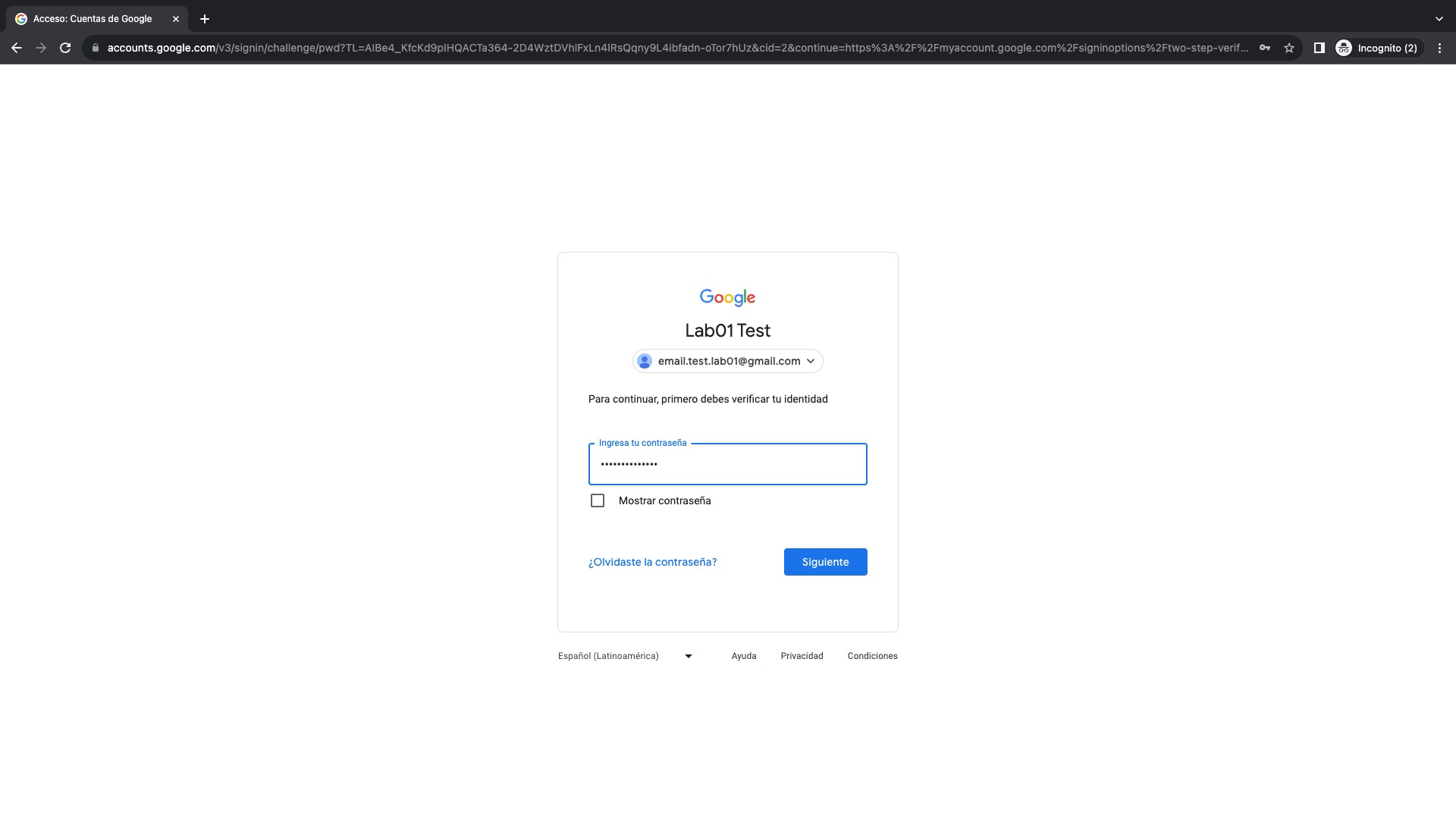
Hacemos nuevamente click sobre el símbolo > frente a Verificacion en 2 pasos e ingresamos la contraseña de la cuenta Gmail para poder ingresar a esta opción
10. Una vez autenticados vamos a hacer scroll down hasta encontrase la sección Contraseñas de aplicaciones y hacemos click sobre el símbolo > para proceder a configurar la contraseña de aplicación que usaremos en VMware Aria Automation durante la configuración del SMTP server
Nota: Actualmente vemos que aparece Ninguna bajo Contraseñas de aplicaciones
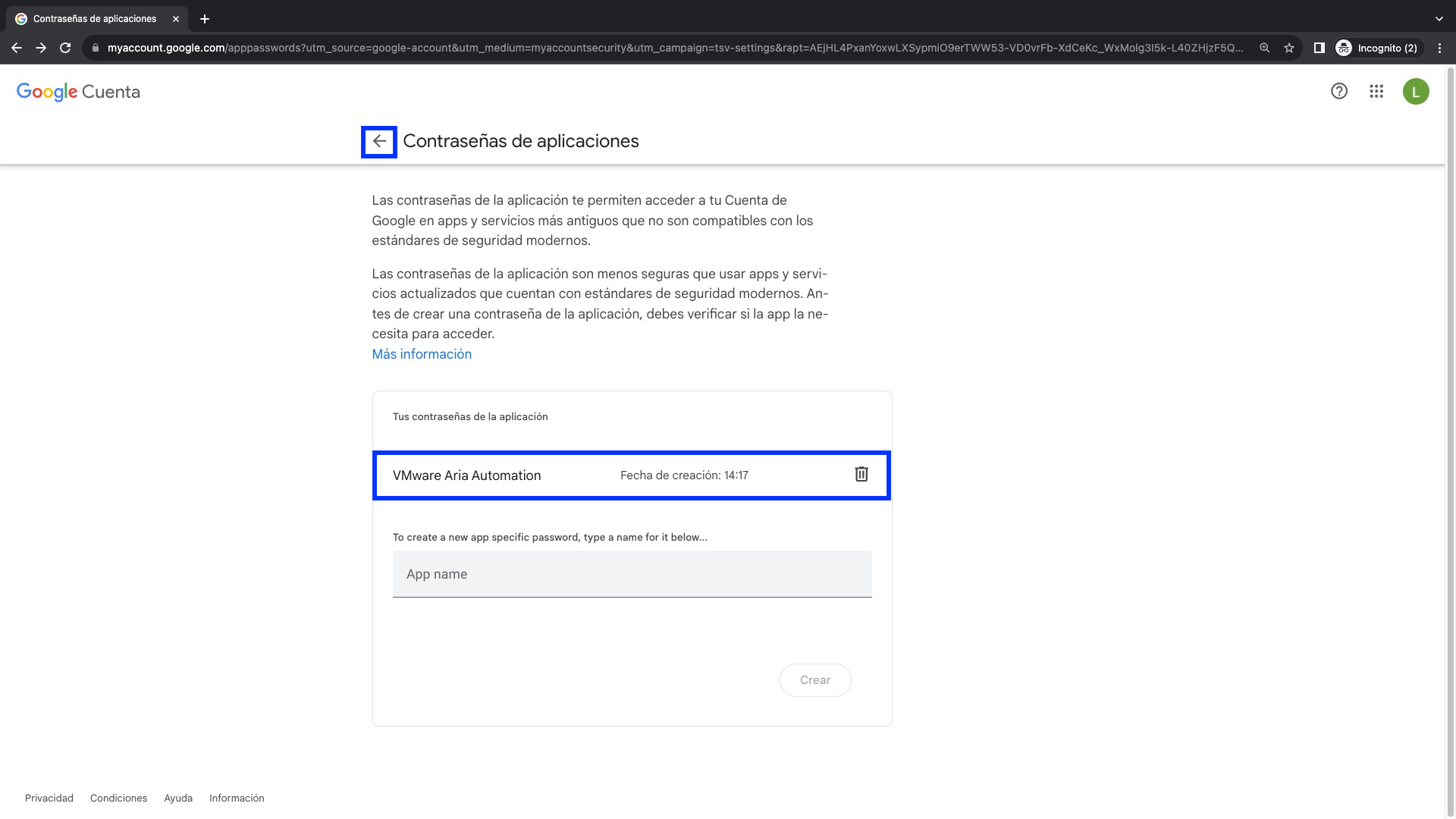
Dentro de Contraseñas de Aplicaciones lo único que tenemos que hacer es crear un nombre para nuestra aplicación (App Name) y después click en Crear. Para este caso hemos definido el nombre VMware Aria Automation
La Contraseña de Aplicación se mostrara en pantalla y debemos copiarla guardarla en un lugar seguro antes de finalizar haciendo click en el botón Listo
Nota: La contraseña generada en este caso es rxgm yubk ktop vxhk y debe ser guardada respetando los espacio que ésta incluye.
Vemos que ahora aparece listada nuestra nueva aplicación creada y podemos volver a atrás si lo deseamos. Hasta aquí es todo lo que teníamos que hacer en la cuenta de Gmail.
Vamos ahora a realizar la configuración en el servicio de Service Broker de Aria Automation, para esto hacemos login en la solución y en el menu principal hacemos click en **Service Broker
Después vamos a Content & Policies -> Notifications -> Email Server. Llenamos los datos como sigue y después click TEST CONNECTION. Si la conexión ha sido exitosa, entonces click en CREATE
Los datos importantes aquí son los siguientes:
Server Name: smtp.gmail.com Sender Name: Alias para el emisor de la notificación Sender Address: Es la cuenta de email utilizada para enviar las notificaciones. No necesariamente debe ser una cuenta real User Name: email.test.lab01@gmail.com (cuenta de email creada) Password:rxgm yubk ktop vxhk (La contraseña de aplicaciones creada en el paso anterior respetando los espacios) Connection Security: SSL/TLS (puede ser también STARTLS, por el contrario la opción None no funcionará) Server port: Aparece automáticamente dependiendo del protocolo de comunicación seleccionado en Connection Security Trust certificates presented by the host: Yes
Nota: La ruta para llegar hasta Notifications -> Email Server podría ser diferente dependiendo de la version.
Nota: Al hacer click sobre el botón TEST CONNECTION deberíamos ver un banner color verde con el mensaje Email server configuration validated successfully
Como resultado del TEST CONNECTION recibiremos ademas un correo electrónico en la cuenta email configurada para el usuario con el cual estamos haciendo el TEST CONNECTION. Es decir, en este caso estamos logueados en Aria Automation con el usuario configadmin que es un usuario local de Workspace One Access, el cual tiene en su atributo email la cuenta de correo electrónico creada anteriormente.
(Opcional) Para validar o cambiar la cuenta de correo electrónico configurada en un usuario local de Workspace One Access debemos hacer login en la solución con un usuario administrador y despues navegar hasta Administration Console
Una vez dentro, podemos navegar hasta la pestaña User & Groups para ver la información de cada uno de los usuarios
Nota: Aquí podemos ver algunos usuarios que son locales (System Domain) y algunos que son de dominio (corp.local). Para los usuarios locales podemos editar el email simplemente haciendo click sobre el usuario y cambiando el valor del campo email.
Nota: En este caso hemos utilizado la cuenta de correo que hemos creado en Gmail, pero podría ser cualquiera.
Por otro lado, para los usuario que son sincronizaos desde el dominio, este campo debe ser editado directamente el Active Directory
Una vez realizados los pasos anteriores, podemos aprovechar las notificaciones que envía Aria Automation Service Broker a los usuario para cada uno de los escenarios indicados en la documentación oficial Send email notifications to Automation Service Broker users
ATENCIÓN!!!
TODOS LOS NOMBRES DE VMS USADOS EN ESTE BLOG SON INVENTADOS Y OBEDECEN A UN AMBIENTE DE LABORATORIO PROPIO, UTILIZADO PARA FINES DE ESTUDIO.
¡IMPORTANTE! He migrado blog del dominio nachoaprendevirtualizacion.com a nachoaprendeit.com. Si te ha servido este artículo deja tu buen Like y compártelo con tus colegas, estas aciones me ayudarán a optimizar los motores de búsqueda para llegar a más personas.
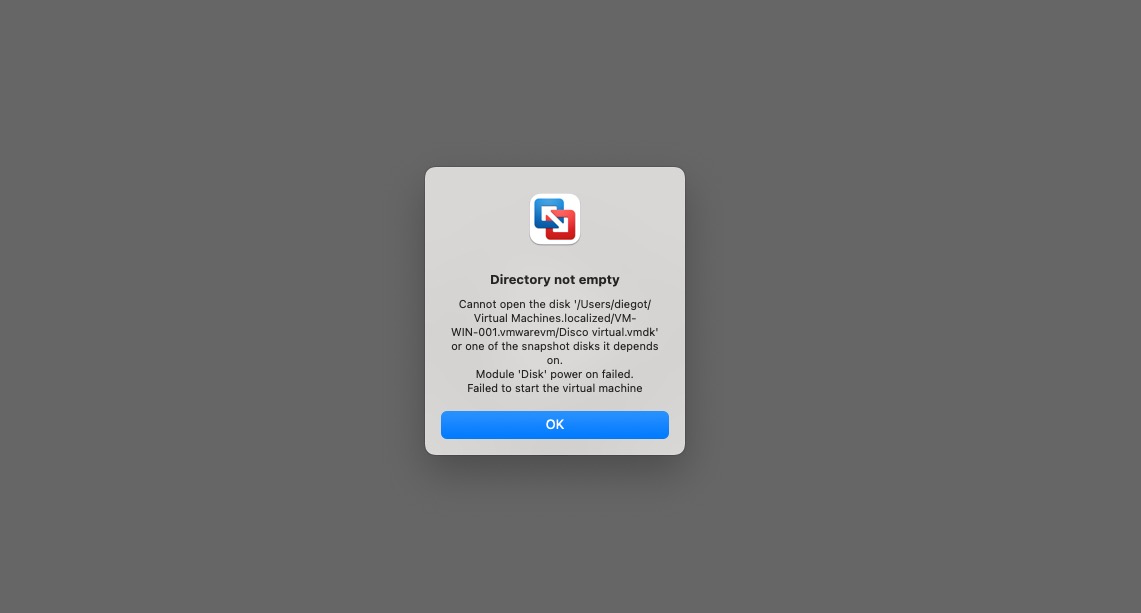
Si después de un apagado forzado o una actualización tu Virtual Machine (VM) en VMware Fusion muestra el siguiente error, este post te muestra como salir de este problema rápidamente.
Cannot open the disk '/User/XXXX/Virtual Machines.localized/YYYY.vmwarevm/Disco Virtual.vmdk' or one of the snapshot disk it depends on.`
Module 'Disk' power on failed. failed to start the virtual machine
Procedimiento
Buscar la VM en la siguiente ruta que te indica el error. De forma predeterminada, los paquetes de máquinas virtuales se almacenan en Macintosh HD/Users/User_name/Documents/Virtual Machines. Según la versión de Fusion y la configuración de Mac OS, el nombre de esta última carpeta puede ser Virtual Machines.localized.
Nota: Las máquinas virtuales que se ejecutan desde particiones de Boot Camp se almacenan en Macintosh HD/Users/User_name/Library/Application Support/VMware Fusion/Virtual Machines/Boot Camp. Aquí solo se almacenan los archivos de configuración de máquinas virtuales de Fusion para la partición de Boot Camp; Fusion utiliza la partición de Boot Camp como disco virtual.
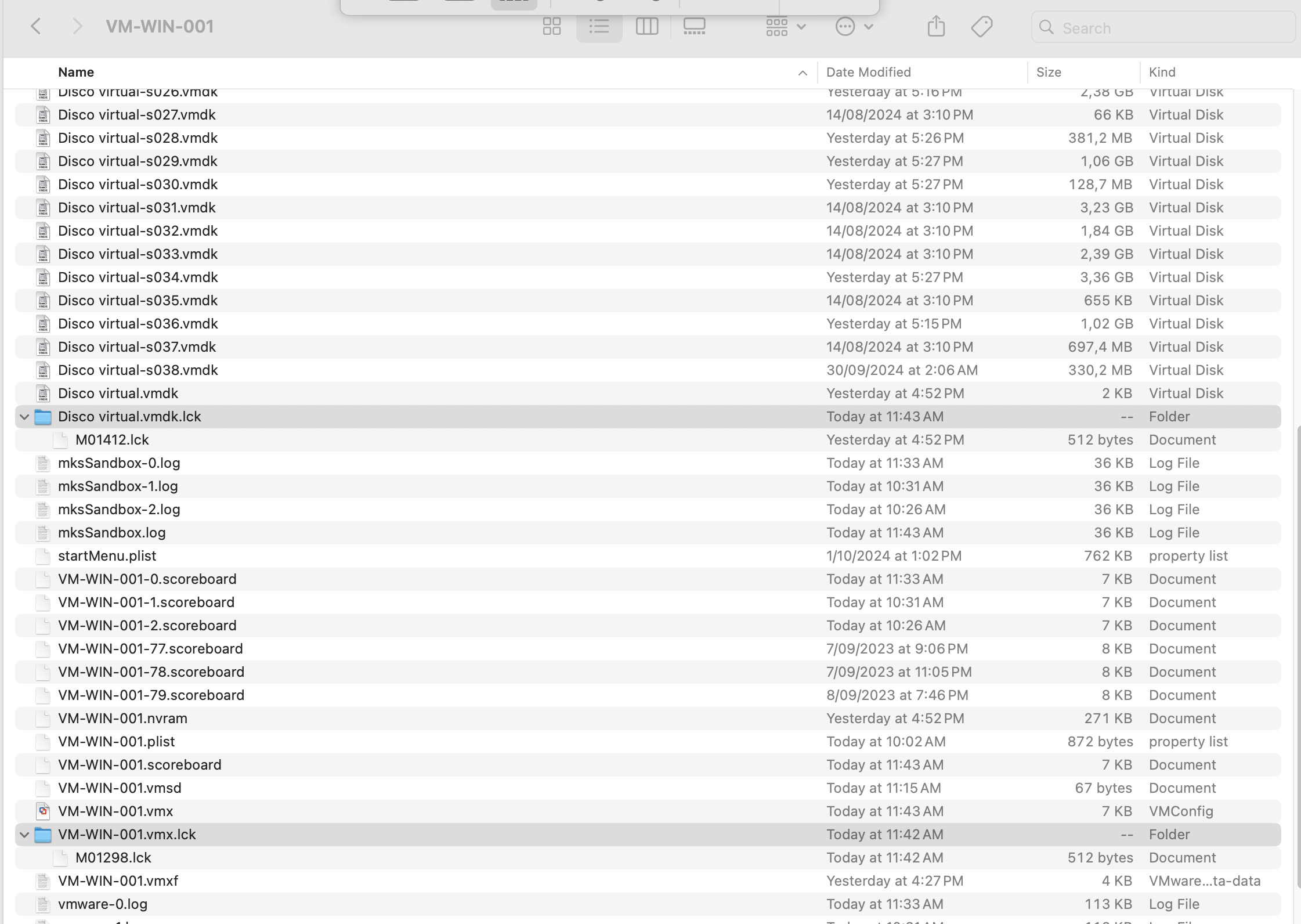
Una vez localizado el archivos de la VM, vamos a hacer clic derecho sobre el y despues Show Package Contents
La acción anterior nos llevará a un nuevo directorio donde debemos localizar las carpetas con el nombre .lck al final, en este caso tengo dos carpetas
Por último, solo debemos eliminar esas carpetas y volver a intentar el Power On de la máquina virtual en VMware Fusion
¡Y eso es todo amigos! Con este procedimiento vas a poder desbloquear una Máquina Virtual (VM) en VMware Fusion que por X o Y razón resultó bloqueada!
¡IMPORTANTE! He migrado blog del dominio nachoaprendevirtualizacion.com a nachoaprendeit.com. Si te ha servido este artículo deja tu buen Like y compártelo con tus colegas, estas aciones me ayudarán a optimizar los motores de búsqueda para llegar a más personas.









































 Now we will choose the context that has our napp deployment, which should be
Now we will choose the context that has our napp deployment, which should be 



 Repeat the steps for the following images that will be the gradual jumps:
Repeat the steps for the following images that will be the gradual jumps: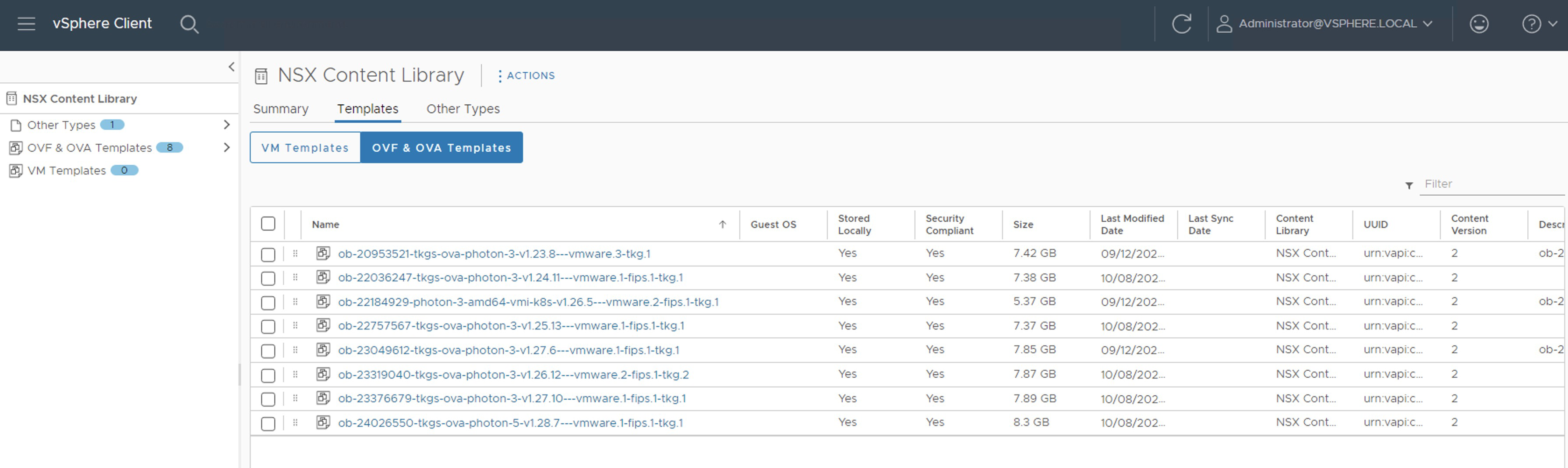 Now if we run the command
Now if we run the command