Si administras infraestructura vSphere y tienes workloads que simplemente no pueden darse el lujo de esperar — sistemas de trading financiero, plataformas de streaming en tiempo real, o control industrial — este artículo es para ti.
VMware by Broadcom publicó en enero 2025 una guía técnica completa sobre cómo optimizar vSphere 8 para este tipo de cargas. El problema es que ese documento asume que ya sabes mucho. Aquí te traigo lo más útil y accionable, explicado de verdad, sin más preámbulo.
CONTENIDO
- ¿De qué hablamos cuando decimos latency-sensitive?
- Baseline Requirements — antes de tocar cualquier cosa
- Host Considerations — empezando desde el BIOS
- VM Considerations — el sizing importa más de lo que crees
- Latency Sensitivity por VM — el setting que muchos ignoran
- Networking — VMXNET3 y más allá
- Comandos de operación útiles
- Conclusion
¿De qué hablamos cuando decimos latency-sensitive?
Antes de entrar en configuraciones, hay que entender qué problema estamos resolviendo, porque si aplicas todo esto a las VMs equivocadas, solo vas a complicarte la vida.
Latencia, en este contexto, es el tiempo que tarda una aplicación en recibir un dato, procesarlo y responder. Para la mayoría de las aplicaciones empresariales, unos milisegundos de más no importan. Pero hay aplicaciones donde ese retardo sí importa — y mucho.
Hablamos de cosas como:
- Una plataforma que procesa órdenes de bolsa en tiempo real, donde microsegundos de diferencia pueden costar dinero.
- Un sistema de control de manufactura que necesita responder a una señal del piso de producción sin demora.
- Una plataforma de broadcast de video en vivo donde cualquier jitter (variación en el tiempo de entrega de paquetes) se ve como glitch en la pantalla del usuario final.
Estas aplicaciones necesitan acceso constante y predecible al procesador y a la red. El problema es que vSphere, por defecto, está configurado para hacer algo muy diferente: consolidar workloads y ser eficiente. Eso significa compartir recursos, hacer balanceo dinámico, y priorizar el uso eficiente de CPU sobre el acceso inmediato a ella. Para workloads normales eso es perfecto. Para estos, es exactamente lo que no queremos.
Lo que vamos a hacer en este artículo es ajustar vSphere para que, en lugar de compartir y balancear, garantice y dedique. Y eso empieza mucho antes de tocar una VM — empieza en el BIOS del servidor físico.
Baseline Requirements — antes de tocar cualquier cosa
Antes de ajustar un solo parámetro, confirma que tu ambiente cumple con lo mínimo recomendado. Aplicar tuning de performance sobre versiones viejas de software o hardware desactualizado es tirar tiempo — las optimizaciones que vamos a ver dependen de capacidades que solo existen en versiones recientes.
| Componente | Requerimiento mínimo | ¿Por qué importa? |
|---|---|---|
| vSphere | 8.0 U3 (o mínimo 7.0 U3) | Las mejoras de scheduling y vTopology automática llegaron en estas versiones |
| Virtual Hardware | Versión 21 o superior | Las versiones viejas pueden bloquear instrucciones del procesador que necesitamos |
| VM Tools | 12.4.5 o superior | Afecta la comunicación entre el guest OS y el hypervisor |
| Procesadores | Generación actual con BIOS/microcode vigente | Los procesadores modernos tienen capacidades de scheduling que los viejos no |
Dicho eso, ahora sí vamos al corazón del tuning del servidor fisico.
Host Considerations — empezando desde el BIOS
Mucha gente piensa que el tuning de performance en vSphere empieza en el vCenter. En realidad empieza mucho antes — en el BIOS del servidor físico. Y esto es algo que se pasa por alto constantemente.
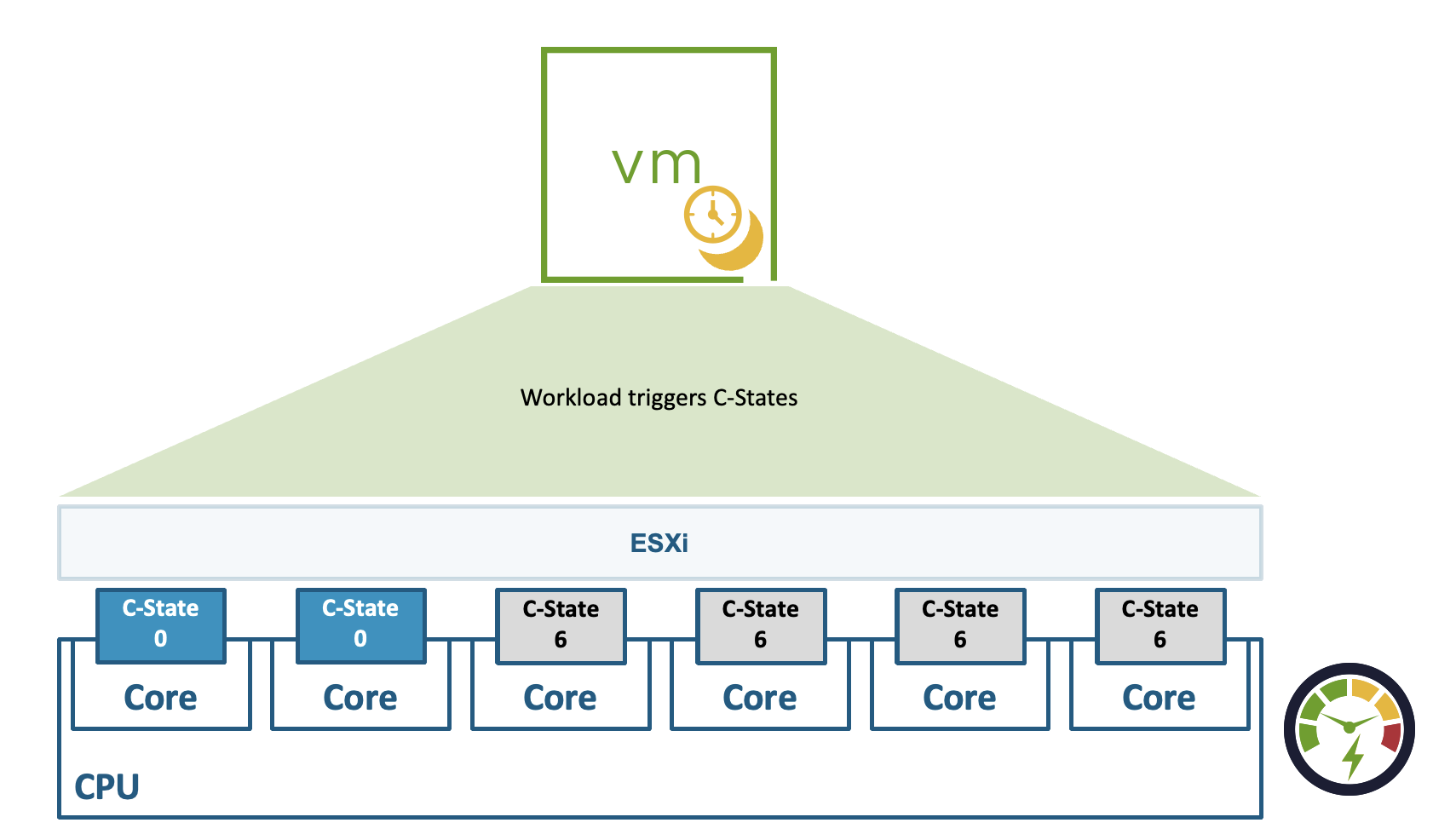
Aquí está la situación: los procesadores modernos son inteligentes. Demasiado inteligentes para lo que necesitamos. Están diseñados para ahorrar energía cuando no hay carga, bajando su frecuencia de operación. Cuando llega trabajo, suben la frecuencia de nuevo. Esto es excelente para eficiencia energética, pero es un desastre para latencia, porque ese proceso de subir y bajar frecuencia toma tiempo — y ese tiempo es latencia impredecible para tu aplicación.
Lo que vamos a hacer en el BIOS es decirle al procesador: «olvídate de ahorrar energía, quiero que operes siempre a máxima capacidad y de forma predecible».
Configuración de BIOS recomendada
| Setting | Valor recomendado | ¿Qué hace y por qué lo tocamos? |
|---|---|---|
| Power Management | High Performance | Le dice al servidor que priorice rendimiento sobre ahorro de energía. Sin esto, el CPU puede estar a velocidad reducida justo cuando tu aplicación lo necesita. |
| Hyper-Threading | Enabled | Permite que cada core físico ejecute dos hilos simultáneamente. Más capacidad de procesamiento paralelo para los worlds del hypervisor. |
| Turbo Boost | Enabled | Permite al CPU subir temporalmente su frecuencia por encima del valor base cuando hay demanda. Lo dejamos activo porque da más rendimiento pico. |
| Energy Efficient Turbo | Disabled | Es una versión «inteligente» del Turbo Boost que decide cuándo activarse basándose en el consumo de energía. Lo desactivamos porque queremos un comportamiento predecible, no uno que varía según métricas de energía. |
| P States | Disabled | Los P-States son los distintos niveles de frecuencia y voltaje a los que puede operar el CPU. Desactivarlos fuerza al procesador a correr siempre al mismo nivel, eliminando las variaciones de latencia que ocurren cuando cambia de estado. |
| C States | Disabled | Los C-States son estados de «sueño» del procesador — cuando no hay trabajo, el CPU se «apaga» parcialmente para ahorrar energía. Despertar desde un C-State toma tiempo. Lo desactivamos para que el CPU nunca entre en modo de bajo consumo. |
| C1E Enhanced Mode | Disabled | Es una variante mejorada del C-State más básico (C1). Mismo principio: si está activo, el CPU puede entrar en modo de ahorro aunque sea brevemente, generando latencia inesperada. |
| QPI/UPI Power Management | Disabled | QPI/UPI es el bus de alta velocidad que conecta múltiples procesadores entre sí (en servidores dual-socket). Si tiene power management activo, esa conexión entre CPUs puede operar a velocidad reducida. Para latencia, la queremos siempre a máxima velocidad. |
| Node Interleaving | Disabled | Cuando está activo, el servidor distribuye la memoria automáticamente entre los nodos NUMA (más sobre NUMA adelante). Parece buena idea, pero en realidad le quita al sistema operativo la capacidad de hacer una gestión inteligente de la memoria. Lo desactivamos para que el OS y el hypervisor controlen dónde va cada dato. |
EVC — otro factor que poca gente considera
EVC (Enhanced vMotion Compatibility) es una función de vSphere que «normaliza» las instrucciones del procesador que ven las VMs, para que puedan moverse con vMotion entre hosts con CPUs de diferentes generaciones. Suena bien, ¿verdad? El problema es que para lograrlo, oculta instrucciones del procesador que podrían beneficiar el rendimiento de tu aplicación.
Para workloads latency-sensitive, usa el baseline de EVC más reciente compatible con tus CPUs, o simplemente desactívalo. Si todos tus hosts tienen la misma generación de CPU, no necesitas EVC de todas formas. Más detalles en KB 313545.
vMotion y DRS — úsalos con cabeza
vMotion migra una VM de un host a otro «en vivo», sin apagarla. Durante ese proceso, hay un momento en que la VM se pausa brevemente — hasta 1 segundo según la documentación oficial. Para aplicaciones normales, un segundo no se nota. Para una aplicación que procesa transacciones financieras o controla maquinaria industrial, 1 segundo puede ser catastrófico.
DRS (Distributed Resource Scheduler) usa vMotion automáticamente para balancear la carga entre hosts. Si DRS está en modo automático, puede mover tus VMs críticas en cualquier momento sin que tú lo decidas.
La recomendación es simple: planifica cuándo y cómo se hacen estos movimientos. No los dejes en automático para workloads latency-sensitive. Úsalos solo en ventanas de mantenimiento planificadas.
Muy bien, con el hardware ajustado, el siguiente paso es optimizar las VMs que van a correr sobre él.
VM Considerations — el sizing importa más de lo que crees
Ya ajustamos el BIOS. Ahora viene la parte donde muchos administradores cometen errores — el tamaño y la configuración de las VMs. La tentación natural es «poner muchos recursos para que no le falte nada». Para latencia, esa lógica es exactamente al revés.
Rightsize VMs — más no siempre es mejor
Primero, un concepto que vas a ver mucho en esta sección: NUMA (Non-Uniform Memory Access). Los servidores modernos tienen múltiples procesadores físicos (sockets), y cada uno tiene su propio «bnaco de memoria» directamente conectada. Acceder a la memoria propia de un CPU es rápido. Acceder a la memoria del otro CPU, cruzando el bus QPI/UPI que mencionamos antes, es más lento — puede ser hasta 2x más lento.
Ese «cruzar al otro CPU para buscar datos» es lo que queremos evitar a toda costa en workloads latency-sensitive.
Por esta razon, recomendamos tres reglas concretas:
1. No hagas la VM más grande que un NUMA node físico. Si tu servidor tiene dos sockets con 32 cores cada uno, y haces una VM de 48 vCPUs, vSphere va a tener que distribuirla entre los dos NUMA nodes. Eso significa que parte de los accesos de memoria van a ser remotos — lentos. Mantén las VMs dentro de un solo NUMA node.
2. Haz la VM tan pequeña como sea suficiente para su función. Una VM más pequeña es más fácil de ubicar completamente dentro de un NUMA node, y genera menos competencia por recursos del sistema. No le pongas 32 vCPUs si la aplicación usa 8. Puedes siempre agregar recursos después si los necesita.
3. Reserva 4–8 cores físicos para el host — y no los asignes a VMs. El ESXi no solo ejecuta VMs. Tiene sus propios procesos que trabajan en nombre de las VMs: recibir paquetes de red, procesarlos antes de entregarlos a la VM, manejar interrupciones de hardware, etc. Estos procesos compiten por CPU con todo lo demás. La única forma de protegerlos es no llenar el host al 100% de capacidad — deja esos cores libres para el hypervisor.
sched.cpu.latencySensitivity.sysContexts en la documentación, no lo vas a encontrar. Fue removido en vSphere 7.0 y ya no existe. No lo configures.
Virtual Hardware Version — no la dejes en la versión vieja
Cuando creas una VM, vSphere le asigna una versión de hardware virtual. Esa versión define qué capacidades tiene disponibles la VM — incluyendo a qué instrucciones del procesador puede acceder. Una VM con Virtual Hardware 13 corriendo en un host con vSphere 8 está, literalmente, usando una versión vieja de todo aunque el host sea moderno.
Usa Virtual Hardware versión 21 con vSphere 8.0 U3. Si tienes VMs viejas que migraste, actualiza la versión del hardware virtual.
vTopology — que la VM «vea» el hardware como realmente es
vTopology es la forma en que vSphere presenta la topología del procesador físico a la VM. En términos simples: ¿la VM cree que tiene 8 cores en 1 socket, o 2 cores en 4 sockets? ¿Sabe que existen múltiples NUMA nodes?
Esto importa porque el sistema operativo guest (Windows, Linux) y las aplicaciones que corren dentro de la VM toman decisiones de scheduling basadas en esa topología. Si la VM tiene una vista distorsionada del hardware, el guest OS va a tomar malas decisiones sobre dónde ejecutar threads y dónde almacenar datos — aumentando la latencia.
Antes de vSphere 8, la configuración por defecto era 1 core por socket, lo cual era casi siempre incorrecto. vSphere 8 aplica automáticamente la vTopology correcta la primera vez que enciendes una VM nueva. El problema es que las VMs que migraste desde versiones anteriores no se ajustan automáticamente — esas las tienes que revisar y corregir manualmente o actualizarles el Virtual Hardware a una versión 20 o superior que ya hace la tarea por ti.
Disable Hot-Add — este feature y la latencia no se llevan bien
vCPU Hot-Add es la capacidad de agregar vCPUs a una VM sin apagarla. Suena útil. El problema es que para implementarlo, vSphere tiene que deshabilitar vNUMA en esa VM.
vNUMA es lo que le permite a la VM «ver» los múltiples NUMA nodes del servidor físico, para que el guest OS pueda hacer una gestión inteligente de la memoria. Sin vNUMA, la VM ve el servidor como si tuviera memoria uniforme en todos lados — lo que se llama topología UMA — y pierde la capacidad de optimizar accesos de memoria.
En resumen: habilitar Hot-Add para «tener flexibilidad» le quita a la VM la capacidad de gestionar bien su memoria, y eso incrementa la latencia. Para workloads latency-sensitive, mantén Hot-Add deshabilitado.
Con las VMs bien configuradas, el siguiente paso es activar el setting más poderoso de todos — y el que más gente pasa por alto.
Latency Sensitivity por VM — el setting que muchos ignoran
Esta es, probablemente, la configuración individual más impactante de todo este artículo. Y la mayoría de los administradores no saben que existe.
Latency Sensitivity es un setting que se activa por VM individualmente. Cuando lo pones en «High», vSphere cambia fundamentalmente cómo maneja esa VM. Son tres cambios críticos:
1. La VM obtiene acceso exclusivo a los cores físicos. Normalmente, vSphere comparte los cores físicos entre múltiples VMs y sus propios procesos. Con Latency Sensitivity en High, cada vCPU de esa VM «toma posesión» de un core físico. Ningún otro proceso, ninguna otra VM, puede correr en ese core mientras la VM lo esté usando. ¿El resultado? El ready time (el tiempo que una VM espera para que le den turno de CPU) cae prácticamente a cero.
2. El vCPU bypasea el scheduler del VMkernel. El scheduler es el componente del hypervisor que decide quién usa el CPU y cuándo. Pasarlo siempre tiene un costo en tiempo — pequeño, pero constante. Con acceso exclusivo a los cores, vSphere puede saltarse ese paso y dejar que el vCPU opere directamente, sin intermediarios. Esto acelera significativamente las operaciones de halt y wake-up del vCPU — que son muy frecuentes en aplicaciones de alta velocidad.
3. VMXNET3 se auto-optimiza. Cuando esta función está activa y la VM usa adaptadores de red VMXNET3, vSphere deshabilita automáticamente el interrupt coalescing (la práctica de agrupar múltiples interrupciones de red en una sola para ahorrar CPU) y el LRO (Large Receive Offload, que agrupa paquetes recibidos). Ambas técnicas ahorran CPU pero introducen pequeños retrasos. Para latencia, preferimos pagar el costo en CPU y obtener la respuesta inmediata.
Cómo activarla (3 pasos obligatorios)
Los tres pasos son obligatorios — no opcionales. Si no haces el 1 y el 2, el paso 3 no funciona correctamente.
Paso 1 — CPU Reservation: Edit Settings → Virtual Hardware → CPU → Reservation
Aquí tienes que reservar CPU en MHz para la VM. La fórmula es simple: frecuencia base del procesador × número de vCPUs. Por ejemplo, si tu CPU corre a 2.4 GHz y la VM tiene 8 vCPUs: 2,400 MHz × 8 = 19,200 MHz de reserva.
Esto garantiza que el host siempre tenga esos recursos disponibles para la VM — no puede dárselos a nadie más.
Paso 2 — Memory Reservation: Edit Settings → Virtual Hardware → Memory → Reservation → Reserve all guest memory (All locked)
Toda la memoria de la VM queda «bloqueada» en RAM física. Ninguna página de memoria puede ser movida a disco (swap). Para latencia, el acceso a disco en lugar de RAM es inaceptable.
Paso 3 — Latency Sensitivity: Edit Settings → VM Options → Advanced → Latency Sensitivity → High
Parámetros avanzados adicionales
Una vez activada la Latency Sensitivity, agrega estos tres parámetros en Edit Settings → VM Options → Advanced → Configuration Parameters → Edit Configuration → Add Configuration Parameters:
sched.cpu.affinity.exclusiveNoStats = TRUEmonitor.forceEnableMPTI = TRUEtimeTracker.lowLatency = TRUE
Estos complementan la configuración de Latency Sensitivity con ajustes más finos de cómo el hypervisor maneja el tiempo y el scheduling de esa VM específica.
Con las VMs configuradas, queda una capa más que afinar. Si señor, la Red.
Networking — VMXNET3 y más allá
La red es el otro gran factor de latencia. Los datos tienen que llegar a la VM lo más rápido posible, con el menor procesamiento intermedio. Aquí hay varias capas que podemos optimizar.
VMXNET3 — el punto de partida
VMXNET3 es el adaptador de red paravirtualizado de VMware. «Paravirtualizado» significa que fue diseñado específicamente para correr dentro de una VM sobre vSphere — no es una emulación de hardware real. Eso lo hace significativamente más eficiente que otros adaptadores virtuales.
Siempre usa VMXNET3 como el adaptador de red en tus VMs latency-sensitive. Si tienes VMs con adaptadores E1000 o E1000E, cámbialos.
Balance Tx y Rx — para alto throughput bidireccional
Si tu VM necesita enviar y recibir datos al mismo tiempo a alta velocidad (piensa en un sistema que procesa streams de entrada mientras genera respuestas de salida), agrega estos parámetros directamente en el archivo VMX de la VM:
ethernetX.pnicFeatures = 4ethernetX.ctxPerDev = 3
(Reemplaza ethernetX con el nombre del adaptador correspondiente, por ejemplo ethernet0)
Esto activa paralelismo en la capa de networking de vSphere — básicamente, permite que múltiples threads procesen el tráfico de red simultáneamente en lugar de hacerlo en serie. El resultado es un balance más equitativo entre el ancho de banda de transmisión y recepción. Requiere que RSS (Receive Side Scaling) esté habilitado en la NIC física del host.
SR-IOV y DirectPath I/O — cuando VMXNET3 no alcanza
Para workloads extremos — más de 50,000 paquetes por segundo — VMXNET3 puede quedarse corto. En esos casos, considera estas dos tecnologías que permiten a la VM acceder directamente al hardware de red, eliminando capas de virtualización:
| Tecnología | Cómo funciona | Cuándo usarla |
|---|---|---|
| DirectPath I/O | La VM accede directamente a 1 NIC física. No hay capa virtual de por medio. | Cuando 1 VM necesita todo el rendimiento de 1 NIC física |
| SR-IOV | La NIC física se divide en múltiples «NICs virtuales» (VFs) que cada VM accede directamente | Cuando varias VMs necesitan acceso casi-directo a hardware compartiendo 1 NIC física |
SmartNICs / DPUs — el siguiente nivel
vSphere 8 soporta DPUs (Data Processing Units), también conocidas como SmartNICs. Son tarjetas de red con su propio procesador dedicado que pueden tomar workloads del networking stack que normalmente correría en los CPUs del host.
Con el modo VMXNET3 UPTv2, el tráfico de red de la VM puede ir directamente a la DPU y su interfaz de red, sin pasar por los CPUs del host — reduciendo latencia y liberando cores para la aplicación. Y a diferencia de DirectPath I/O, esto sí mantiene compatibilidad con DRS, HA y otras funciones de vSphere 8.
Comandos de operación útiles
Ya con todo configurado, necesitas herramientas para monitorear que todo esté funcionando como esperas. Aquí los comandos más útiles del día a día.
Ver estadísticas de la NIC física
Útil para confirmar que la NIC está operando correctamente y ver contadores de errores o drops:
esxcli network nic stats get -n vmnicX
(Reemplaza vmnicX con el nombre de tu NIC, por ejemplo vmnic0)
Ver y ajustar ring buffers
Los ring buffers son áreas de memoria donde la NIC almacena paquetes antes de que el CPU los procese. Si son muy pequeños y llegan muchos paquetes rápido, se llenan y los paquetes se descartan. Para streams UDP en particular, esto es crítico.
# Ver cuál es el máximo que soporta la NICesxcli network nic ring preset get -n vmnicN# Ver el tamaño actual configuradoesxcli network nic ring current get -n vmnicN# Aumentar los ring buffers (rx = receive, tx = transmit)esxcli network nic ring current set -n vmnicX -r 2048 -t 1024
Compara el preset máximo con el valor actual. Si el actual es mucho menor al máximo, aumentarlo puede reducir drops de paquetes.
Monitoreo con net-stats
net-stats -A -t WwqQi -i 2
Agrega | grep para filtrar por lo que te interesa. Los contadores clave son rxeps y txeps — si ves que suben, tienes drops de paquetes. El campo de thread utilization te ayuda a identificar contención en el scheduling de red.
Deshabilitar queue pairing
En workloads donde se transmite mucho más de lo que se recibe (como streaming de video saliente), una función llamada queue pairing puede generar un cuello de botella: el thread que procesa la recepción también tiene que procesar las confirmaciones de transmisión, y si hay muchas transmisiones, puede atrasarse y agotar el buffer de la vNIC.
esxcli system settings advanced set -o /Net/NetNetqRxQueueFeatPairEnable -i 0
Conclusion
Lo que cubrimos aquí son los ajustes de mayor impacto y más aplicables para la mayoría de los entornos. El white paper oficial de Performance Tuning for Latency-Sensitive Workloads va más allá y cubre escenarios más específicos que dejamos fuera a propósito para no complicar el artículo:
- Afinización manual del thread de transmisión (Tx) de la VM a un core físico específico
- Asociación de VMs a NUMA nodes específicos para alinearlas con la NIC física
- Tuning de Photon OS con kernel
linux-rt(basado en PREEMPT_RT) para cargas de tiempo real dentro del guest - Enhanced Datapath para workloads NFV
- Lista completa de comandos
esxcli networkcon referencia de parámetros
He migrado el blog del dominio nachoaprendevirtualizacion.com a nachoaprendeit.com. Si te ha servido este artículo, deja tu buen 👍 Like y compártelo con tus colegas. Estas acciones me ayudarán a optimizar los motores de búsqueda para llegar a más personas y a motivarme a seguir compartiendo este tipo de artículos.