
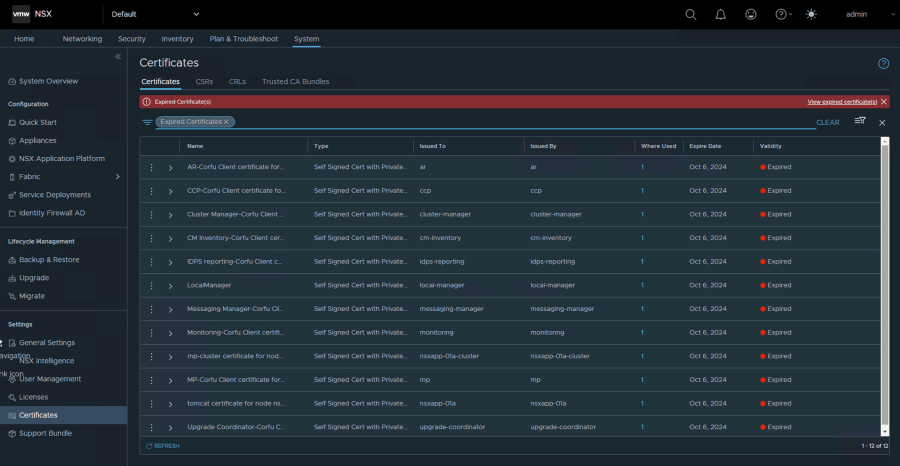
Si tienes un ambiente de NSX 4.1.x o superior, has llegado un día a la oficina y te has encontrado con un montón de alertas de certificados expirados. ¡Este post es para ti!

Contexto
- El entorno ejecuta NSX 4.1.0.2 o superior y se actualizó desde NSX-T 3.2.x.
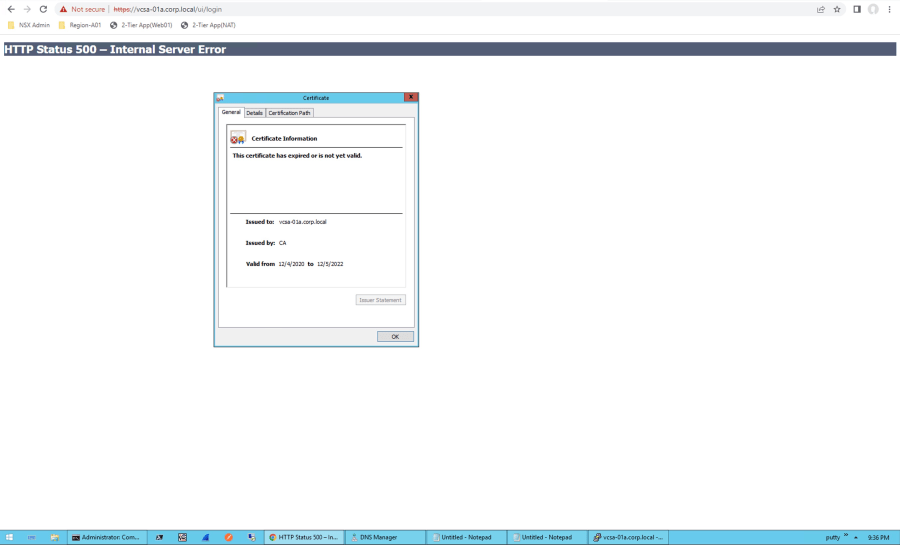
- Las alarmas de NSX indican que los certificados han expirado o están a punto de expirar.
- Los certificados que vencen contienen «Corfu Client» en su nombre.
Causa
Hay dos factores principales que pueden contribuir a este comportamiento:
- Los NSX Managers tienen muchos certificados para servicios internos.
En NSX-T 3.2.x, los certificados de servicio de Cluster Boot Manager (CBM) tenían un período de validez incorrecto de 825 días en lugar de 100 años.
Esto se corrigió a 100 años en NSX-T 3.2.3 y NSX 4.1.0.
Sin embargo, en cualquier entorno que haya ejecutado anteriormente NSX-T 3.2.x (anterior a 3.2.3), los certificados internos de CBM Corfu vencerán después de 825 días, independientemente de si se actualiza o no a la versión corregida. - En NSX-T 3.2.x, los certificados de servidor internos podían vencer y no se activaba ninguna alarma. No se produjo ningún impacto funcional.
A partir de NSX 4.1.0.2, las alarmas de NSX ahora controlan la validez de los certificados internos y se activan en el caso de certificados vencidos o que estén a punto de vencer.
Nota: En NSX 4.1.x, no hay impacto funcional cuando caduca un certificado interno. Sin embargo, las alarmas seguirán activándose y esto es lo que verás si estás frente esta situación, que podrás solucionar en menos de 5 min.


Solución
Siguiendo el KB NSX alarms indicating certificates have expired or are expiring nos dice que existe un script en Python que resuelve este problema como por arte de magia. Para ello solo necesitamos una VM con python instalado. La buena noticia es que el vCenter Server ya tiene los módulos que necesitamos para ejecutar estos scripts, así que no vamos a tener que desplegar nada, solo cargar el script al vCenter Server Appliance y lanzarlo desde ahí. Para mayor información por favor revisar el KB indicado anteriormente.
Procedimiento
Descargar el script
replace_certs_v1.7.pyque se encuentra al final del KB NSX alarms indicating certificates have expired or are expiring
Cargar el archivo a la carpeta
/tmpdel vCenter Server Appliance utilizando WinSCP o cualquier cliente SFTP.
Como persona responsable asegúrate de tener el Backup de NSX reciente. En mi caso, tomaré un snapshot, ya que es un ambiente Nested.
Hacer login al vCenter Server con el usuario
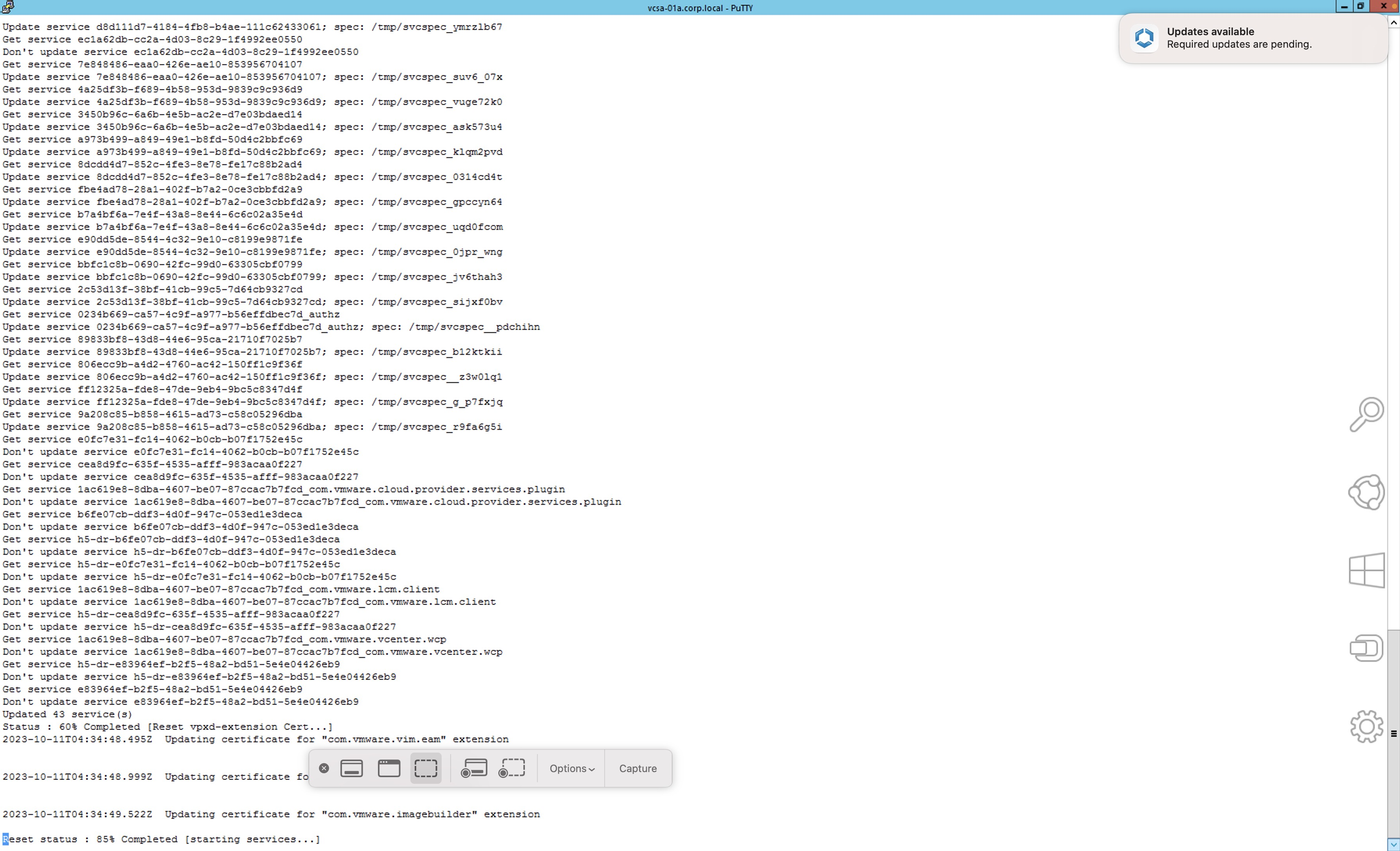
rooty navegar hasta la carpeta/tmp. Una vez aquí simplemente ejecutamos el siguiente comandopython3 replace_certs_v1.7.py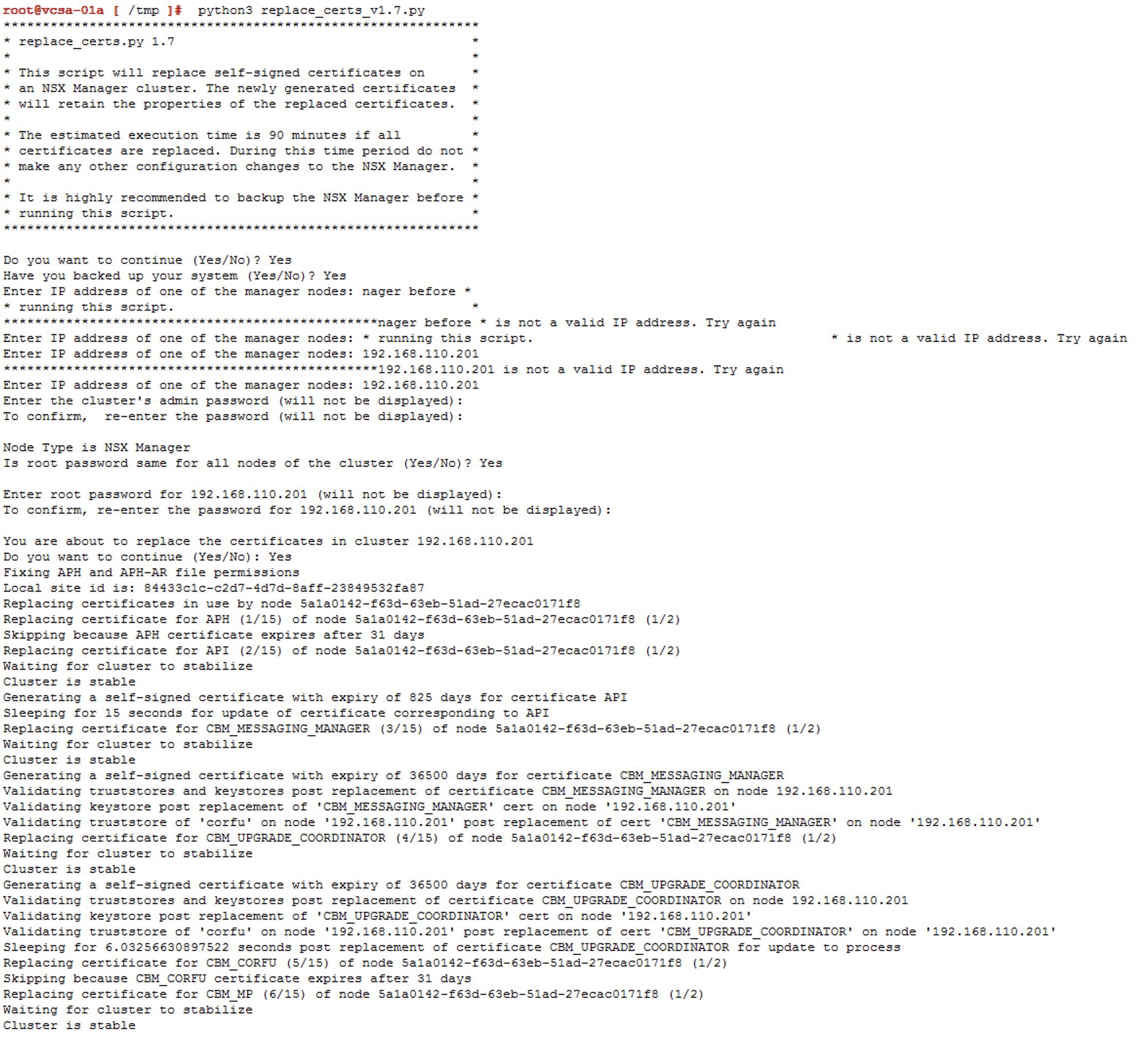

Nota: Lo único que tenemos que hacer es responder a las preguntas que nos realiza el script.
Resultado
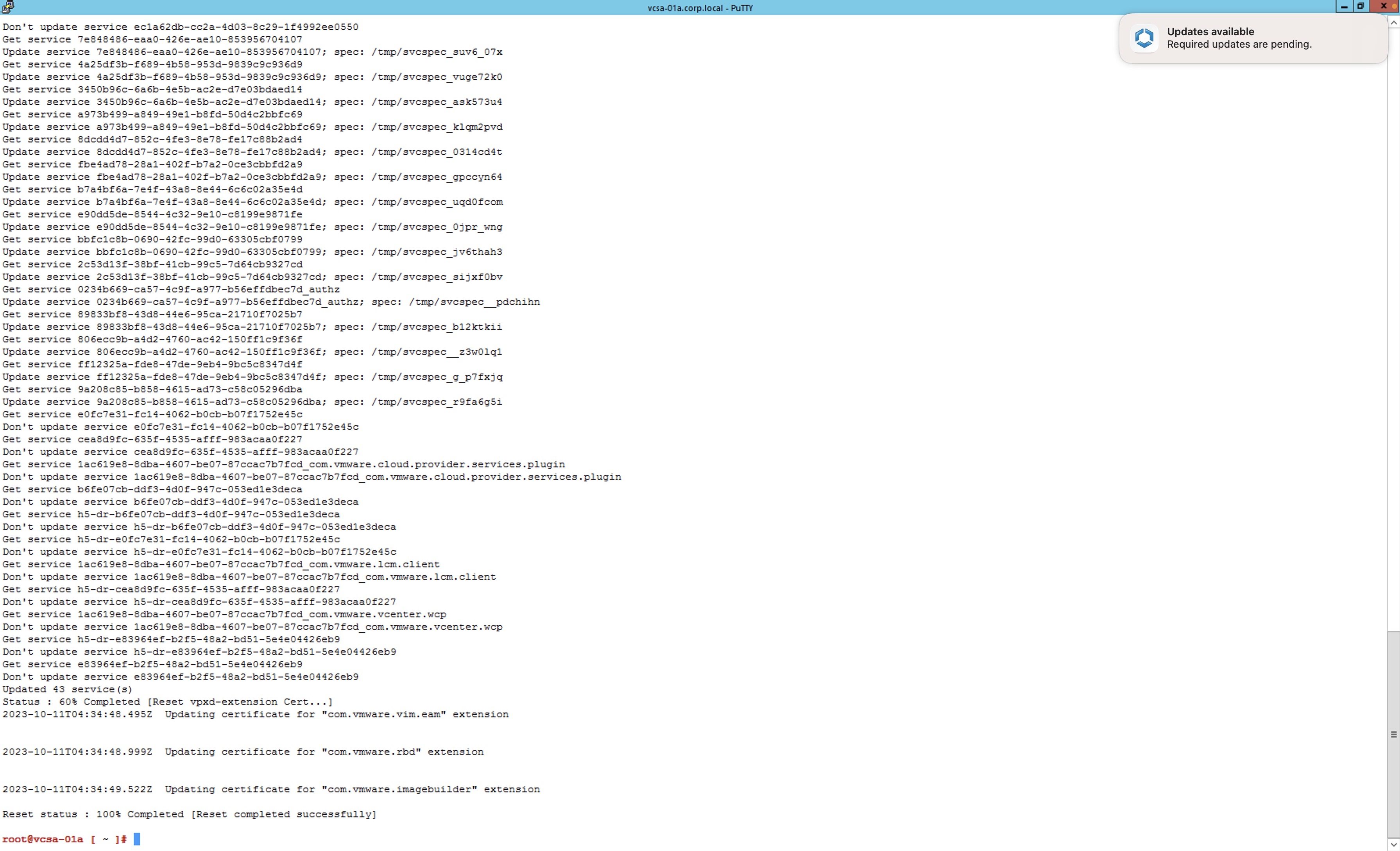
Una vez finaliza la ejecución del script, aproximadamente 30 minutos en el laboratorio, podemos ver que todas las alertas de certificados se han corregido.
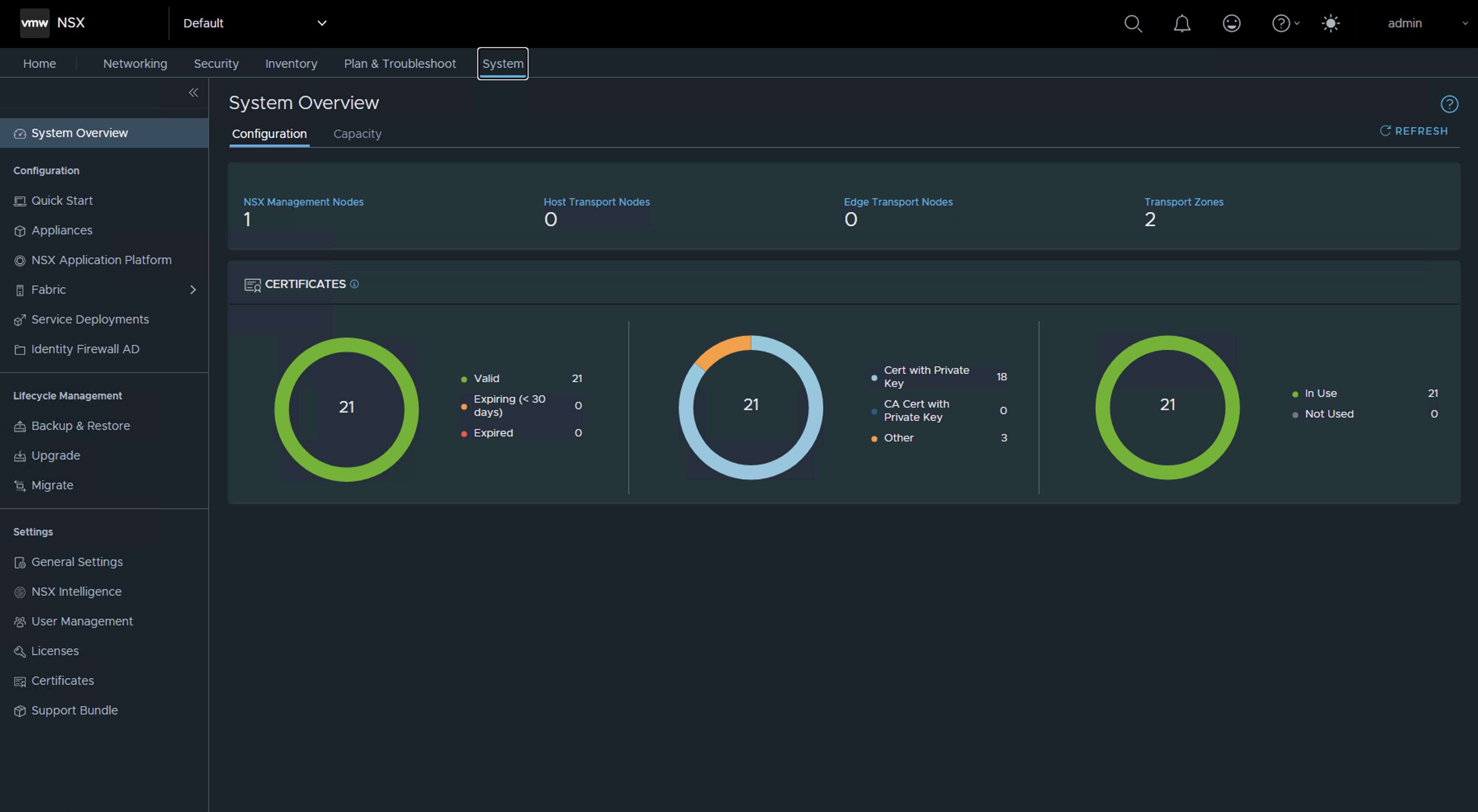
Si revisamos el certificado de uno de los NSX Manager, podremos ver que su fecha ha sido actualizada.
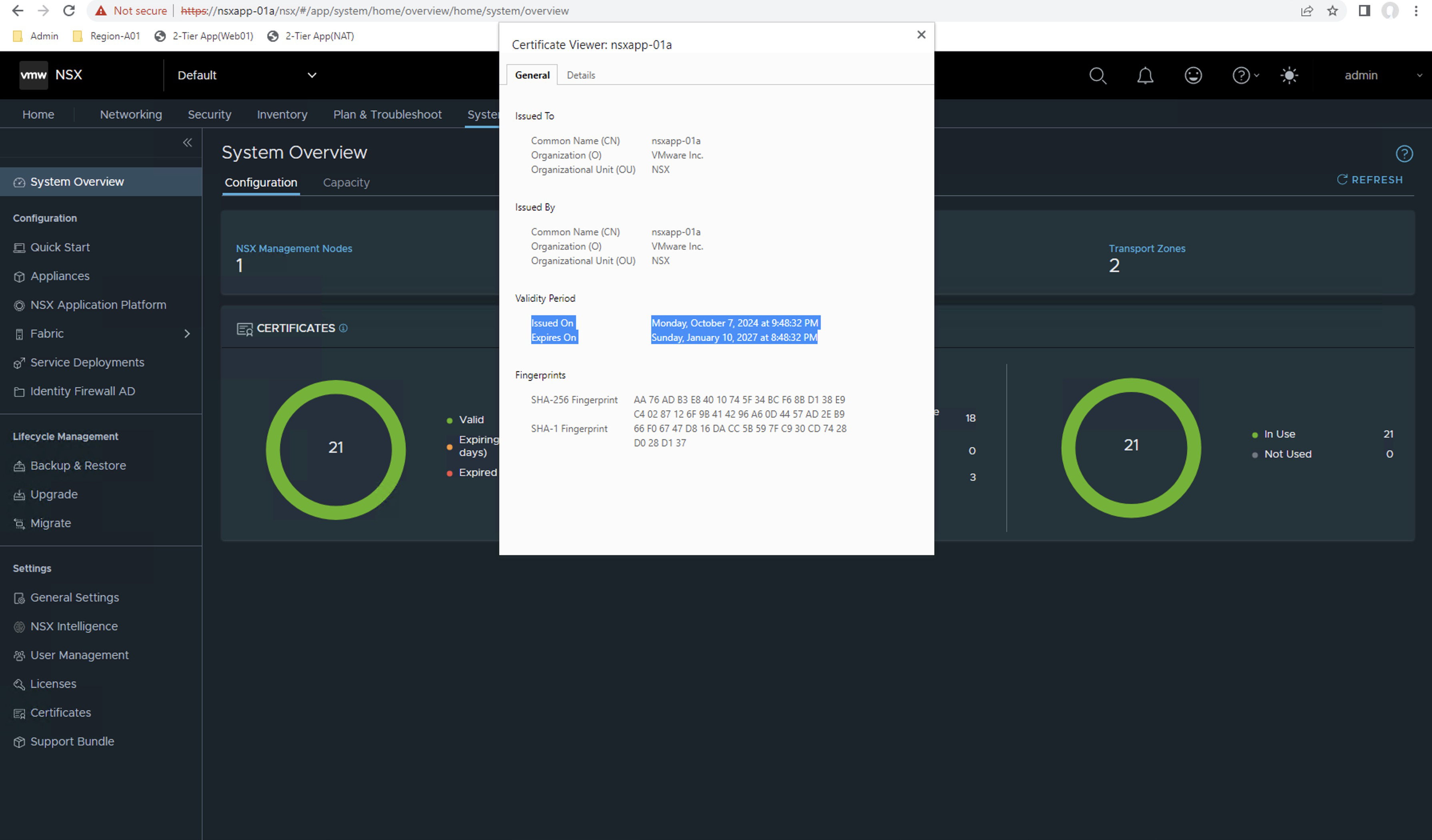
También podemos verificar que ya no tenemos alertas de Certificados en la sección Settings > Certificates

¡Y eso es todo amigos! Ya puedes pasar el susto y volver tus tareas habituales…
Actualización 13012025
La solución de este problema ha sido actualizada y ahora se puede utilizar el script CARR para resolver este problema. Consulte Uso del script CARR (Certificate Analyzer Resolver) para solucionar problemas relacionados con certificados en NSX para descargar el script actualizado.
Actualización 12122024
- Nota para las versiones NSX 4.1.2 o anteriores: debido a problemas de permisos de carpetas y archivos, es posible que el script no reemplace los certificados en la primera ejecución y los intentos posteriores sí los reemplacen. Asegúrese de ejecutar el script una segunda vez en caso de que no funcione la primera vez.
- Nota para NSX 4.1.1 y versiones posteriores: el script no rota
CBM_APIlos certificados (certificado de cliente API-Corfu), ya que estos están obsoletos en la versión 4.1.1. Consulte la resolución de KB#367857.
Después de completar el script, es posible que algunos certificados sin usar permanezcan en la interfaz de usuario con la columna “ Dónde se usa ” establecida en 0. Estos certificados se pueden eliminar si lo desea. - Nota para VCenter 8.0 U3: este script puede fallar en vCenter 8.0 U3 debido a problemas de incompatibilidad. Puede fallar con el error:
SshCommandExecutor: An error occurred: [digital envelope routines] unsupportedUnable to SSH to '192.168.x.x'. Please fix it and rerun the script
Solución: use una versión diferente de vCenter o utilice un dispositivo Linux diferente con los componentes necesarios para ejecutar el script. - Si el script finaliza con »
Keystore is not updated post replacement«, consulte el siguiente artículo: El script de reemplazo de certificado genera un error durante la ejecución: el almacén de claves no se actualiza después del reemplazo del certificado ‘CBM_X’ en el nodo ‘IP»
¡IMPORTANTE! He migrado blog del dominio nachoaprendevirtualizacion.com a nachoaprendeit.com. Si te ha servido este artículo deja tu buen Like y compártelo con tus colegas, estas aciones me ayudarán a optimizar los motores de búsqueda para llegar a más personas.

ATENCIÓN!!!
TODOS LOS NOMBRES DE VMS USADOS EN ESTE BLOG SON INVENTADOS Y OBEDECEN A UN AMBIENTE DE LABORATORIO PROPIO, UTILIZADO PARA FINES DE ESTUDIO.





























![clip_image001[7]](https://nachoaprendeit.com/wp-content/uploads/2020/03/clip_image0017.png "clip_image001[7]")































![clip_image001[5]](https://nachoaprendeit.com/wp-content/uploads/2019/10/clip_image0015.png "clip_image001[5]")

![clip_image001[7]](https://nachoaprendeit.com/wp-content/uploads/2019/10/clip_image0017.png "clip_image001[7]")
















![clip_image001[1]](https://nachoaprendeit.com/wp-content/uploads/2019/01/clip_image0011.png "clip_image001[1]")












