¡Bienvenidos a esta serie post con visión técnica de lo nuevo que ha venido incorporando vSphere en los últimos años!
¿POR QUÉ AHORA?
Estando de cara al cliente en mi dia a dia me he dado cuenta que muchos clientes siguen utilizando vSphere en sus versiones 8.x sin conocer las nuevas funcionalidades, y operandolo como si nunca hubiera existido un update que mejora el rendimiento, la seguridad o la gestión del entorno virtual.
Por esta razon, estoy convencido que es crucial que nuestros clientes estén informados sobre estas capacidades para optimizar su infraestructura. Y aunque ya está disponible VCF 9.0 y vSphere 9.0, es importante conocer en las versiones actuales que la mayoria de nuestros clientes tienen, para facilitar la transición a nuevas versiones y garantizar que la infraestructura esté alineada con las mejores prácticas.
Con el fin de fomentar la adopción de VMware Cloud Foundation, he creado una serie de blogs que resumen las mejoras o What’s New de vSphere 8.x, abordando características como la escalabilidad, la integración con la nube, la resiliencia y herramientas de administración que simplifican la labor del administrador de sistemas.
Sin mas preámbulo les dejo los links a cada una de ellas. Les aseguro que no les tomará mas de 20 minutos comocer todo lo que vSphere nos trajo antes de la version 9.x.
¡IMPORTANTE! He migrado blog del dominio nachoaprendevirtualizacion.com a nachoaprendeit.com. Si te ha servido este artículo deja tu buen Like y compártelo con tus colegas, estas aciones me ayudarán a optimizar los motores de búsqueda para llegar a más personas, y a motivarme a seguir compartiendo este tipo de artículos.
TODOS LOS NOMBRES DE VMS USADOS EN ESTE BLOG SON INVENTADOS Y OBEDECEN A UN AMBIENTE DE LABORATORIO PROPIO, UTILIZADO PARA FINES DE ESTUDIO.
¡Bienvenidos a un ultimo capítulo de esta serie de posts donde exploramos la evolución de vSphere 8.x! En esta ocasión hablaremos de vSphere 8.0 Update 3, liberado el 25 de junio de 2024, una de las actualizaciones más completas de la serie 8.x.
El objetivo sigue siendo el mismo: dar a nuestros clientes, partners y comunidad una visión clara de las mejoras que VMware ha ido incorporando en cada release. Y es que, aunque ya estamos viendo llegar VMware Cloud Foundation 9, la mayoría de las organizaciones hoy en día siguen ejecutando cargas críticas sobre vSphere 8.x.
Así que acompáñame a revisar, de manera resumida y técnica, las novedades más importantes que trajo este update.
Antes de hablar de lo nuevo, es importante revisar lo que se va. Cada versión de vSphere deja atrás tecnologías que ya no cumplen con los estándares modernos de seguridad y eficiencia. Veamos qué funciones han sido marcadas como obsoletas o eliminadas en vSphere 8.0 U3.
IMPORTANTE: La vida útil de vSphere 7 termina el 2 de octubre de 2025, así que este es un momento clave para planear la migración.
Obsolecencias destacadas
Update Manager baselines y APIs.
Autenticación integrada con Windows, RSA SecureID directo y Smart Card directo.
Boot en SD/USB y BIOS heredado (migrar a UEFI + Secure Boot).
NPIV en Fibre Channel, soporte CIM/SLP, Trust Authority, SDRS y SIOC para IO Latency.
TPM 1.2, CPUs y dispositivos I/O en fin de vida.
Soporte para Guest OS antiguos (incluyendo MacOS en KB 88698).
Remociones
Cliente local de vSphere.
Adaptadores Software FCoE y RoCE v1.
Binarios de 32 bits.
Cifrados inseguros como SHA1.
Nota: si aún dependes de estas tecnologías, es hora de actualizar.
Comencemos ahora si con lo interesante de este release que probablemente es el que mas mejoras ha incluido en la version vSphere 8.x
vSphere Supervisor
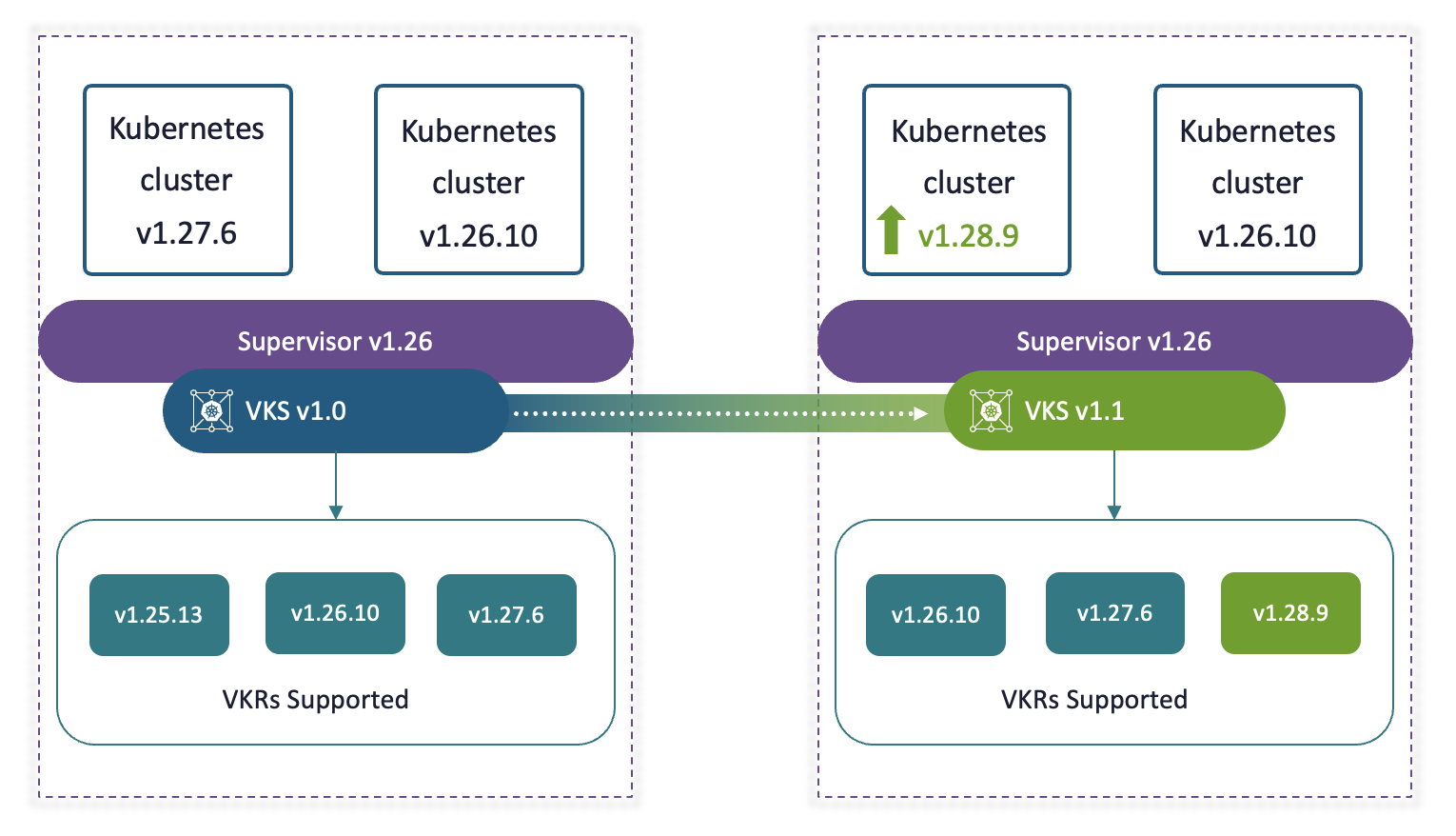
Kubernetes sigue siendo protagonista en la evolución de vSphere. En esta versión, VMware da un paso importante para separar el ciclo de vida de Kubernetes del de vCenter, lo que trae más flexibilidad y rapidez. Vamos a ver cómo esto impacta a los clústeres y qué mejoras llegan para los administradores.
Kubernetes desacoplado de vCenter: ahora el servicio VKS tiene lanzamientos asíncronos alineados con versiones upstream que le nos permite actualizar el cluster de Kubernetes independientemente de los upgrades del vCenter o Supervisor.
Autoscaling nativo para clústeres Kubernetes (minima versión soportada v1.25):
Escala nodos cuando aumenta la demanda.
Escala hacia abajo cuando hay recursos sobreutilizados.
Soporte para vSAN Stretched Cluster permite desplegar clústeres de Kubernetes sobre una infraestructura vSAN distribuida en dos sitios geográficos distintos. Gracias a esto, si un sitio completo falla, el otro puede seguir operando, garantizando alta disponibilidad y resiliencia para las cargas de trabajo de Kubernetes.
Rotación automática de certificados del Supervisor sin intervención manual (solo alerta si falla). En vSphere 8.0 U3 elimina la necesidad de intervención manual cuando un certificado está por expirar. El sistema se encarga de renovar los certificados de forma automática antes de su vencimiento.en vSphere 8.0 U3 elimina la necesidad de intervención manual cuando un certificado está por expirar. El sistema se encarga de renovar los certificados de forma automática antes de su vencimiento.
Backup & Restore de VMs en namespaces vía VADP, con recreación automática de objetos del Supervisor.
En vSphere 8.0 U3 se habilita la integración del VM Service con Advanced Data Protection (VADP) para realizar backup y restore de máquinas virtuales dentro de namespaces.
VM Class expandida: más opciones de hardware administradas desde el vCenter UI.
En lugar de definir cada ajuste manualmente, los usuarios pueden referirse a una VM Class como plantilla completa, mientras que los administradores mantienen un control granular sobre qué configuraciones de hardware estarán disponibles para los usuarios de autoservicio.
Local Consumption Interface (LCI): Ofrece una interfaz gráfica que simplifica el consumo de servicios básicos, permitiendo desplegar VMs y clústeres de Kubernetes con generación automática de YAML y soporte para configuraciones como balanceadores de carga y volúmenes persistentes, reduciendo la complejidad y acelerando las operaciones.
Lifecycle Management
Mantener la infraestructura actualizada sin interrumpir el negocio es clave. En vSphere 8.0 U3 encontramos avances en la forma de actualizar, configurar y parchar nuestro entorno, con menos caídas y más control. Revisemos estas mejoras en la gestión del ciclo de vida.
vCenter Reduced Downtime Update: migración con switchover automático u opcional manual, minimizando la caída del servicio.
vSphere Configuration Profiles: gestión declarativa de configuración a nivel de clúster, con soporte de baselines.
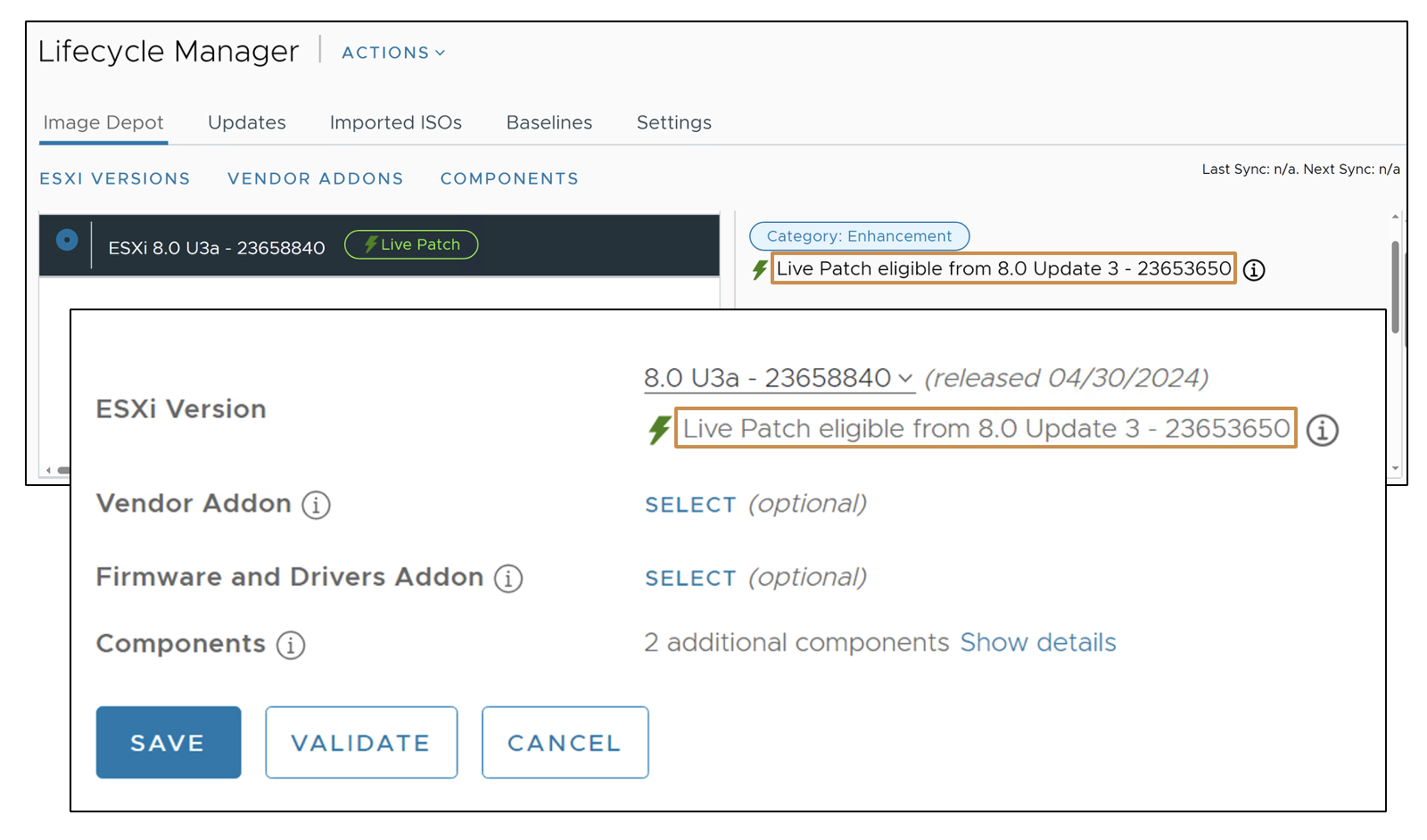
vSphere Lifecycle Manager (vLCM):
Live Patch: aplicar parches sin evacuar VMs.
Staging, remediación paralela y soporte para hosts standalone.
El hardware evoluciona y vSphere también. En este update vemos soporte optimizado para DPUs, GPUs y CPUs de última generación, con mejoras que apuntan directamente a workloads de IA, cómputo intensivo y memoria acelerada. Descubramos qué trae de nuevo este soporte.
Dual DPU Support
Modo HA: active/standby con failover transparente.
Modo Capacidad: 2 DPUs independientes, duplicando capacidad de offload.
CPUs y memoria
Soporte optimizado para Intel Xeon y AMD EPYC con aceleradores integrados (QAT, AMX, AVX-512).
Scheduler mejorado para CPUs de muchos núcleos.
NVMe para memoria (Tech Preview): más cargas in-memory con menor TCO.
GPUs
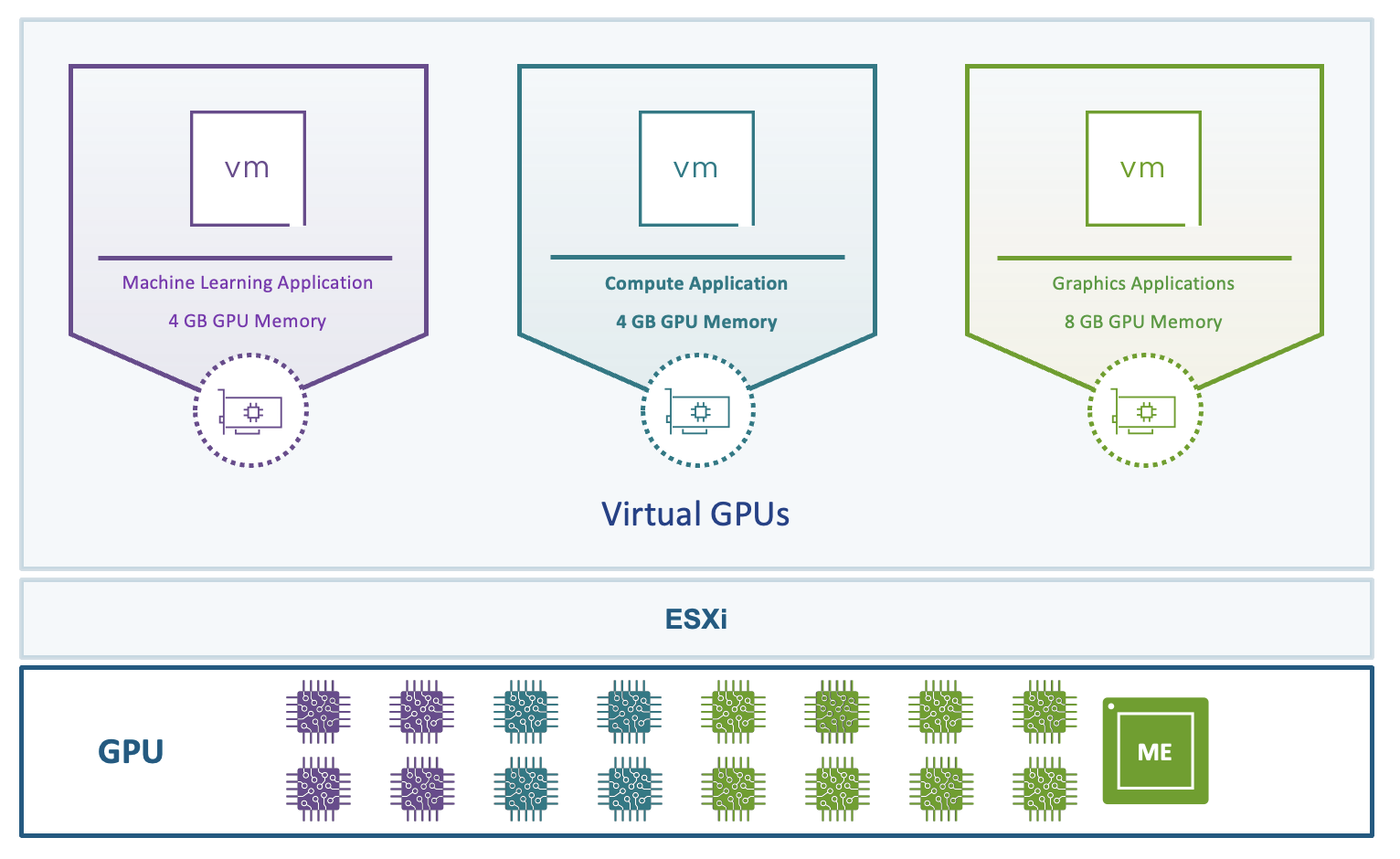
Perfiles flexibles de vGPU con mezcla de workloads gráficos y de cómputo.
Cluster-level GPU Monitoring: visibilidad centralizada de consumo.
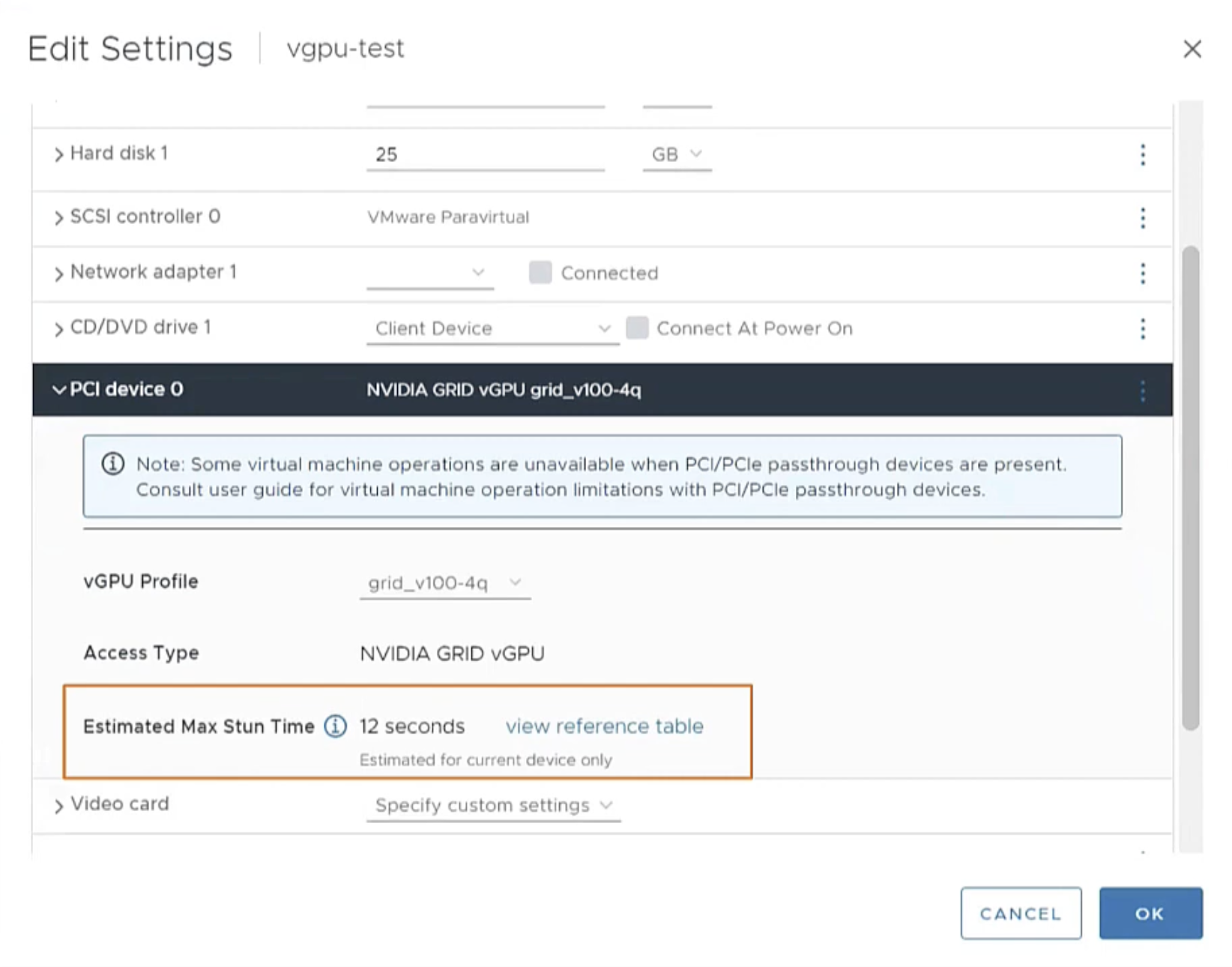
Mejoras en movilidad de VMs con vGPU, con control de stun time en vMotion.
Availability & Resilience
La alta disponibilidad no es opcional en entornos críticos. Con esta actualización, vSphere introduce mejoras para mantener los clústeres resilientes y con menor footprint, asegurando continuidad incluso en escenarios distribuidos. Veamos los cambios más relevantes.
vSphere Cluster Service embebido en ESXi:
Solo 2 VMs por clúster.
Sin footprint en almacenamiento.
Fault Tolerance para Metro Clusters (vSAN y no-vSAN): permite ubicar primario y secundario en sitios distintos.
Workloads y eficiencia
No todo es más potencia: también se trata de eficiencia. vSphere 8.0 U3 incorpora funciones que permiten ahorrar energía y optimizar despliegues de máquinas virtuales sin perder flexibilidad. Aquí te cuento cómo impacta esto en las cargas de trabajo diarias.
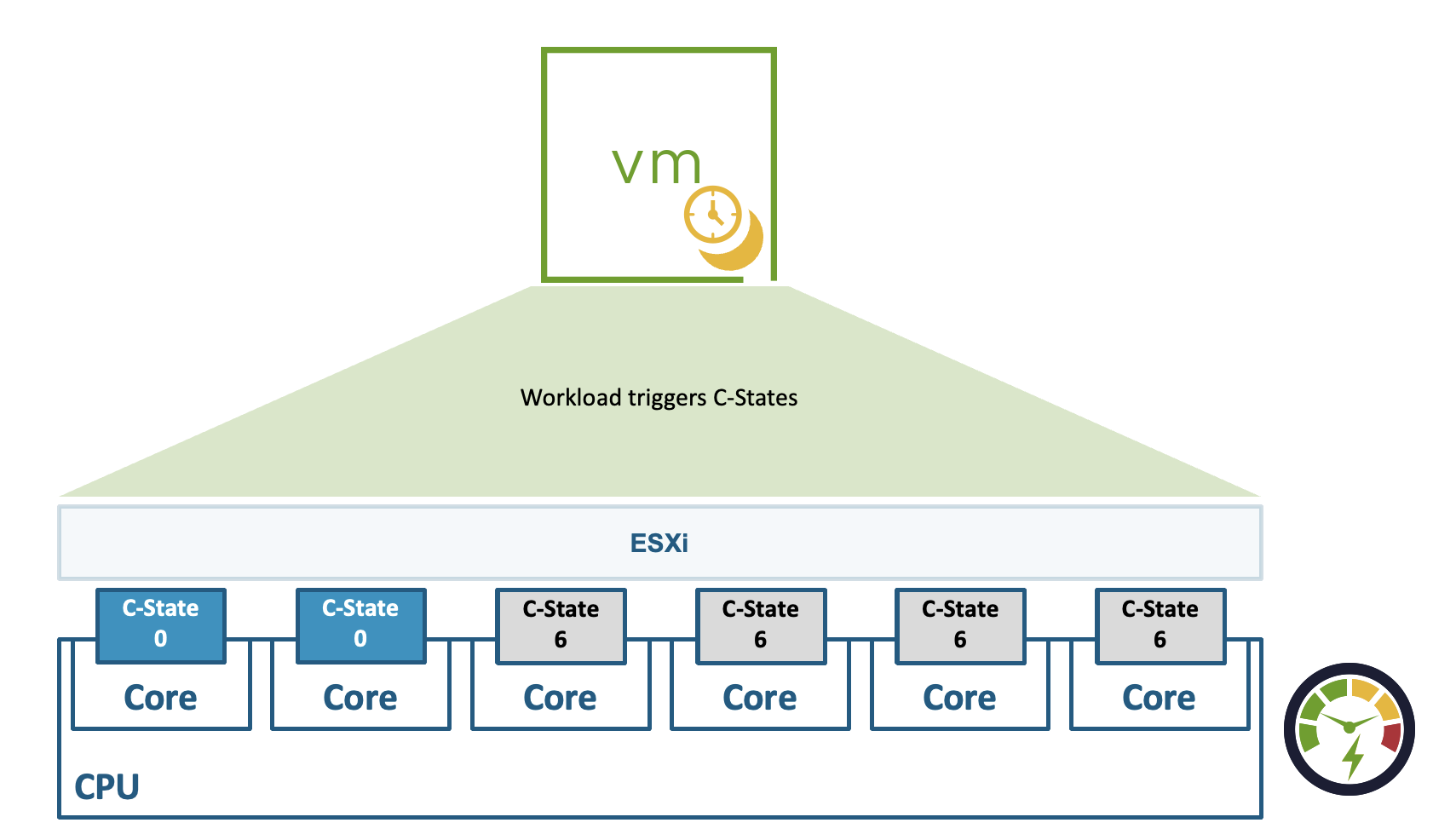
CPU C-State Virtualization: permite a las cargas invocar modos de ahorro profundo de energía en CPUs.
OVF/OVA con personalización de hardware al desplegar desde Content Library.
Self-Service Resolution: reactivar operaciones de VM deshabilitadas sin tocar la BD de vCenter.
Seguridad y Cumplimiento
La seguridad sigue siendo prioridad en cada release. En vSphere 8.0 U3 se amplían las opciones de identidad, se simplifica la gestión de cifrados y se refuerzan las guías de endurecimiento (Hardening) con automatización. Exploremos qué significa esto para proteger mejor nuestros entornos.
PingFederate como nuevo IdP soportado.
TLS & Cipher Suite Profiles: configuración rápida de suites modernas vía API/PowerCLI.
Security Configuration Guides actualizados, ahora incluyen vSAN y scripts para auditoría/remediación.
Storage
El almacenamiento es el corazón de cualquier plataforma virtualizada. En vSphere 8.0 U3, VMware introduce soporte extendido para vVols, NVMe y NFSv4.1, además de optimizaciones que reducen tiempos y mejoran el rendimiento. Vamos a desglosar estas novedades.
vVols Stretched Cluster (soporte inicial con SCSI y Uniform).
UNMAP en vVols con NVMe (manual y automático).
UI mejorada para registro y troubleshooting de Storage Providers.
WSFC sobre vVols con NVMeoF con shared disks (sin RDMs).
Clustered VMDK con NVMe-TCP (se suma a NVMe-FC de U2).
NVMeoF mejorado: soporte de reservas y copy optimization.
FPIN (Fabric Performance Impact Notification): alertas de congestión en FC.
Reducción drástica en tiempos para inflar discos Thin ➝ EZT en VMFS.
NFSv4.1 con nConnect: mayor throughput usando múltiples conexiones.
CNS/CSI: soporte para hasta 250 file shares y migración de PVs entre datastores no compartidos.
Conclusión
vSphere 8.0 U3 no es solo una actualización más: es, hasta ahora, la versión que más mejoras y cambios ha incorporado en la serie 8.x, abarcando desde seguridad, almacenamiento y eficiencia operativa, hasta soporte de hardware de nueva generación para IA, GPUs y DPUs.
Esta actualización marca un punto de quiebre porque nos prepara directamente para la adopción de VMware Cloud Foundation 9, asegurando que las organizaciones que actualicen a vSphere 8.0 U3 tengan la base más sólida, segura y moderna para dar el salto al ya liberado vSphere 9.0.
Con estas capacidades, VMware demuestra que vSphere sigue siendo el pilar confiable para workloads tradicionales y nativos de nube, al mismo tiempo que prepara el camino hacia el futuro de la infraestructura empresarial.
¡IMPORTANTE! He migrado blog del dominio nachoaprendevirtualizacion.com a nachoaprendeit.com. Si te ha servido este artículo deja tu buen Like y compártelo con tus colegas, estas aciones me ayudarán a optimizar los motores de búsqueda para llegar a más personas, y a motivarme a seguir compartiendo este tipo de artículos.
TODOS LOS NOMBRES DE VMS USADOS EN ESTE BLOG SON INVENTADOS Y OBEDECEN A UN AMBIENTE DE LABORATORIO PROPIO, UTILIZADO PARA FINES DE ESTUDIO.
Como hemos aprendido hasta ahora. VMware continuó innovando con el lanzamiento de vSphere 8.0 Update 2, una actualización que mejora la eficiencia operativa, la resiliencia y la flexibilidad de la plataforma. Esta versión introduce nuevas funcionalidades para reducir el tiempo de inactividad en actualizaciones, mejorar la administración de certificados, fortalecer la seguridad y optimizar la gestión de cargas de trabajo.
A continuación, detallamos las principales mejoras de esta actualización liberada el 21 de septiembre de 2023.
Actualizaciones de vCenter con Menos Tiempo de Inactividad
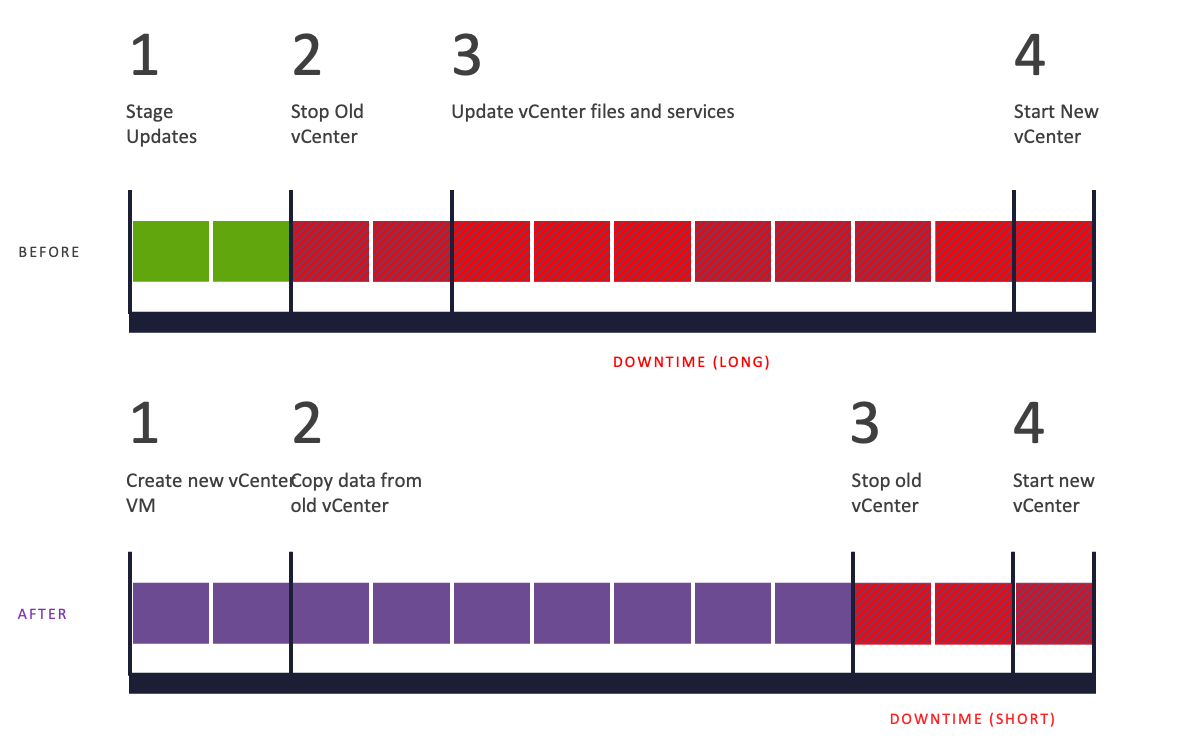
Una de las principales novedades es el vCenter Reduced Downtime Update, que minimiza la interrupción del servicio al actualizar vCenter. Ahora, se despliega un nuevo appliance de vCenter mientras el actual sigue en funcionamiento. El tiempo de inactividad solo ocurre en la fase final, cuando los servicios del vCenter antiguo se detienen y se activan en el nuevo, reduciendo la interrupción a menos de 5 minutos.
Esto mejora la continuidad operativa, minimiza el impacto en los usuarios y facilita el proceso de rollback en caso de ser necesario. Esto sin duda nos permite tener actividades de Actualización y parchado más eficientes.
Mayor Resiliencia en el Patching de vCenter
Los parchados del vCenter ahora incluyen snapshots automáticos de la particion LVM (Logical Volume Manager) antes de aplicar parches, lo que facilita la recuperación en caso de fallas. Es importante aclarar que no es un snapshot a nivel de VM.
Además, el proceso permite pausas y reversiones si es necesario. En el evento de una falla en el parchado, podemos hacer rollback a las última versión de backup del LVM.
Nota: Esto no reemplaza los mecanismos de backup por imagen o por archivo que deberíamos tener en nuestro ambiente para proteger la Virtual Machine de vCenter Server.
2. Seguridad y Administración de Certificados Mejorada
Cambios de Certificados Sin Interrupciones
vSphere 8.0 U2 introduce la capacidad de renovar o reemplazar certificados del vCenter sin reiniciar los servicios. Esto reduce la necesidad de programar ventanas de mantenimiento y minimiza riesgos operativos.
Refuerzo en Seguridad Contra Ransomware
Se han mejorado las configuraciones predeterminadas para proteger el entorno desde el primer momento. Además, se han actualizado las guías de seguridad y se han agregado scripts de PowerCLI para auditorías y correcciones automatizadas.
3. Gestión de Clústeres y Almacenamiento Más Flexible
Mejoras en la Gestión de vSAN
Ahora, vSphere Lifecycle Manager (vLCM) puede administrar la imagen de los nodos witness de vSAN de manera independiente, lo que proporciona más control y flexibilidad en la administración del almacenamiento.
Soporte Mejorado para Sistemas Operativos Invitados
En esta versión tenemos la posibilidad de personalizar OUs en Active Directory al unir un sistema Windows.
Por otro lado, los mensajes de error en el panel de Task son más descriptivos cuando los archivos están bloqueados, incluyendo detalles del host que mantiene el bloqueo. Y es que a quien no le ha pasado que encuentran las VMs apagadas y no las pueden encender? Bueno pues ahora el mensaje de error nos permite identificar cuál host tiene bloqueado los archivos.
4. Optimización para Workloads con GPU y AI
Expansión del Ecosistema de DPU y GPU
VMware continúa trabajando en incrementar su ecosistema de Partner para proporcionar a sus clientes compatibilidad con múltiples fabricantes de dispositivos DPUs y GPUs. Recordemos que en versiones anteriores solo estaba soportado NVIDIA y AMD Pensando.
Desde esta versión de vSphere (vSphere 8.0 U2), ahora podemos soportar hasta 16 vGPUs en una sola máquina virtual, así como hasta 32 dispositivos de transferencia directa. Esto permite que vSphere admita los modelos y cargas de trabajo de IA/ML más grandes y complejos que necesitan toda esa aceleración de hardware.
También podemos ahora configurar el tiempo máximo de aturdimiento «stun» para vMotion en cargas de trabajo con GPU.
Por último, se ha mejorado la colocación y balanceo de cargas de trabajo de GPU para optimizar el uso de recursos.
Novedades en Virtual Hardware
Pasemos ahora a las mejoras en el Virtual Hardware. Y aprovecho para resaltar la importancia de realizar el proceso de actualización de VMtools y Virtual Hardware una vez completado el proceso de actualización de vCenter y ESXi. Debido a que esto suele ser una actividad que es pasada por alto por los administradores, impidiendo que la actualizacion de la infraestructura sea completa y se accedan a las mejoras a nivel de las VMs.
Soporte para hasta 32 dispositivos de passthrough por VM.
Compatibilidad mejorada con NVMe 1.3 y 256 discos vNVMe por VM.
Sensibilidad a alta latencia con Hyperthreading activado.
5. Innovación para DevOps y Kubernetes
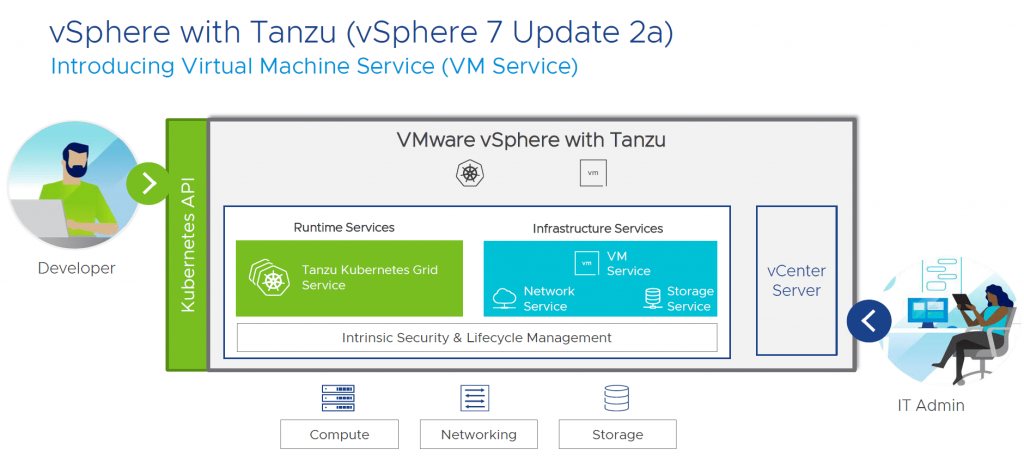
Mejoras en VMware vSphere with Tanzu
Exportación e importación de configuraciones de Supervisor Clusters para una rápida replicación de entornos.
Servicio de VM mejorado, permitiendo la provisión de VMs Windows y Linux junto con contenedores. Los usuarios de DevOps pueden usar kubectl para implementar y personalizar máquinas virtuales de Windows en sus namespaces. Los datos de personalización de invitados de Windows, que utilizan el formato estándar SysPrep, se encapsulan como un secret y se incluyen en la especificación de implementación de la máquina virtual.
Self-Service VM Images, donde los desarrolladores pueden gestionar imágenes de VM mediante kubectl. Teniendo la posibilidad no solo de leer el contenido de la Content Library sino además publicar contenido dentro de la misma.
Conclusión
vSphere 8.0 U2 es una actualización clave que mejora la eficiencia, seguridad y flexibilidad de la plataforma. Con un enfoque en minimizar el tiempo de inactividad, reforzar la seguridad y mejorar la experiencia de administración, esta versión sigue posicionándose como la mejor opción para entornos empresariales modernos.
Si deseas conocer más detalles, consulta la documentación oficial de VMware o experimenta estas mejoras en tu infraestructura.
Recursos
¡IMPORTANTE! He migrado blog del dominio nachoaprendevirtualizacion.com a nachoaprendeit.com. Si te ha servido este artículo deja tu buen Like y compártelo con tus colegas, estas aciones me ayudarán a optimizar los motores de búsqueda para llegar a más personas, y a motivarme a seguir compartiendo este tipo de artículos.
TODOS LOS NOMBRES DE VMS USADOS EN ESTE BLOG SON INVENTADOS Y OBEDECEN A UN AMBIENTE DE LABORATORIO PROPIO, UTILIZADO PARA FINES DE ESTUDIO.
Muy bien como lo explicamos en el post anterior Novedades Clave de vSphere 8.0 GA: Mejoras y Funcionalidades En esta oportunidad hablaremos solo de las características que fueron incluidas en vSphere 8.0 U1 y. Recordemos que el objetivo final de esta serie de post de novedades de vSphere es tener una visión general de la evolución del producto hasta la fecha. Y estar preparados para la actualización de vSphere 9.0 que ya fue liberada.
Continuando con nuestro camino de adopción de la solución vSphere, componente principal de VMware Cloud Foundation, en este artículo recordaremos las nuevas funciones y mejoras que vSphere 8 Update 1 trajo consigo el 18 de Abril de 2023, mejorando la eficiencia operativa, elevando la seguridad y potenciando las cargas de trabajo.
Podemos categorizar las mejoras de vSphere en tres temas principales:
Administración Eficientemente: Hacer que sea más fácil para los clientes operar sus infraestructuras de TI de la manera más eficiente posible.
Seguridad: Cada función se convierte en una característica de seguridad, lo que permite a los equipos de TI centrarse en ser seguros en lugar de solo asegurar.
Potenciar Cargas de Trabajo: Introducir soporte para nuevas tecnologías de hardware, como GPUs y DPUs.
Administración Eficientemente
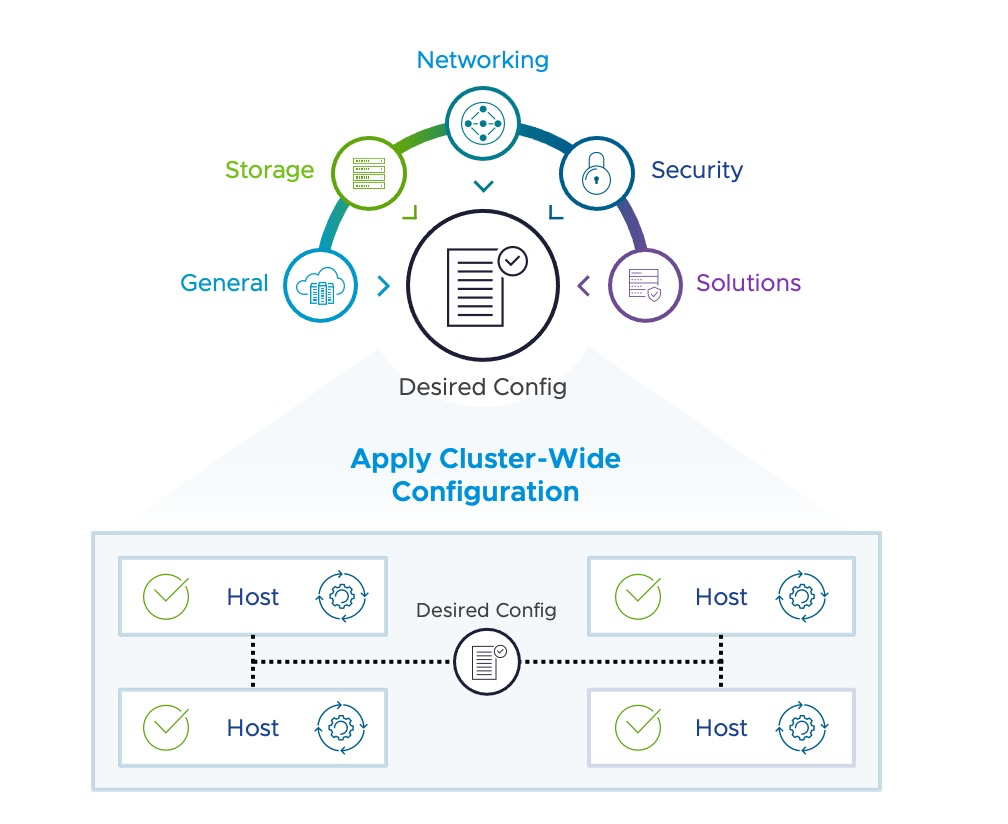
vSphere Configuration Profile
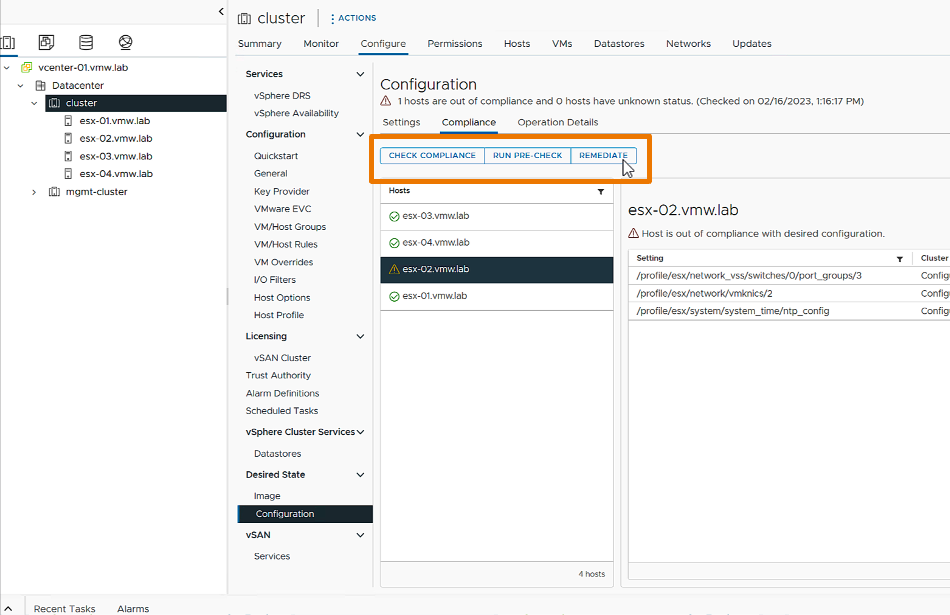
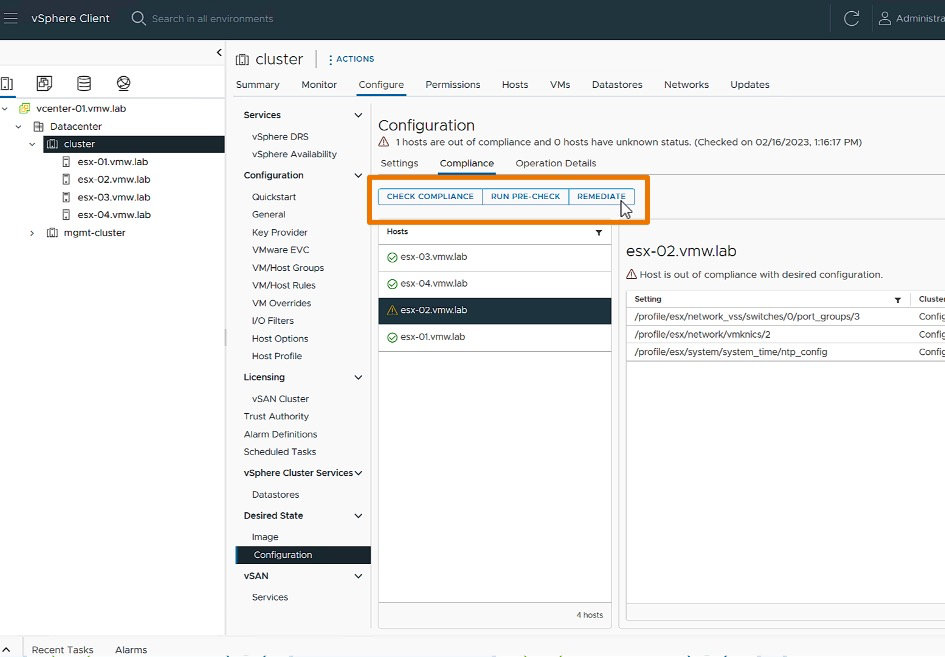
Comenzamos con los vSphere Configuration Profile, que facilitan la gestión de la configuración del clúster. Esta nueva función permite a los administradores establecer configuraciones deseadas a nivel de clúster en formato JSON, verificar la conformidad de los hosts y remediar cualquier incumplimiento.
Si bien esta funcionalidad fue introducida en vSphere 8.0 GA como Tech Preview, en vSphere 8 Update 1 comenzó a ser completamente soportada. Permitiendo la configuración de vSphere Distributed Switch que no estaba disponible en la version anterior.
vSphere Lifecycle Manager (vLCM)
Además, se mejoró el vSphere Lifecycle Manager (vLCM) para admitir hosts standalone. Esto incluyó la capacidad de definir imágenes personalizadas y gestionar hosts en ubicaciones remotas con conectividad limitada. Desde esta versión todo lo que se espera de vLCM esta disponible para hosts Standalone.
Flexibilidad en Cargas de Trabajo de GPU
Con vSphere 8 Update 1, ahora se pueden asignar diferentes perfiles de GPU a diferentes cargas de trabajo en la misma máquina. Esto permite a los administradores maximizar la utilización de recursos de GPU.
Mejoras en vSphere con Tanzu
Se han realizado mejoras significativas en la integración de Tanzu Supervisor Services, permitiendo su uso con vSphere Distributed Switch, lo que facilita su implementación y gestión.
Como parte de las mejoras incorporadas al entonces vSphere with Tanzu, se añadieron nuevas funcionalidad al vSphere Virtual Machine Service (VM Service), incluido en la versión vSphere 7 Update 2a , y que básicamente permite implementar y gestionar Virtual Machines mediante las API estándar de Kubernetes, al mismo tiempo que permite al administrador de TI controlar el consumo de recursos y la disponibilidad del servicio. Si quiere saber un poco más de VM Service lo invito a leer este corto articulo Introducing the vSphere Virtual Machine Service escrito por Glen Simon.
Como parte de esas mejoras al VM service el equipo de DevOps ahora puede traer tu propia imagen, lo que permite a los usuarios crear imágenes que se pueden almacenar en una biblioteca de contenido.
Adicionalmente, los desarrolladores pueden ahora lanzar la consola de las VMs utilizando el comando kubectl sin necesidad de tener acceso al vCenter Server.
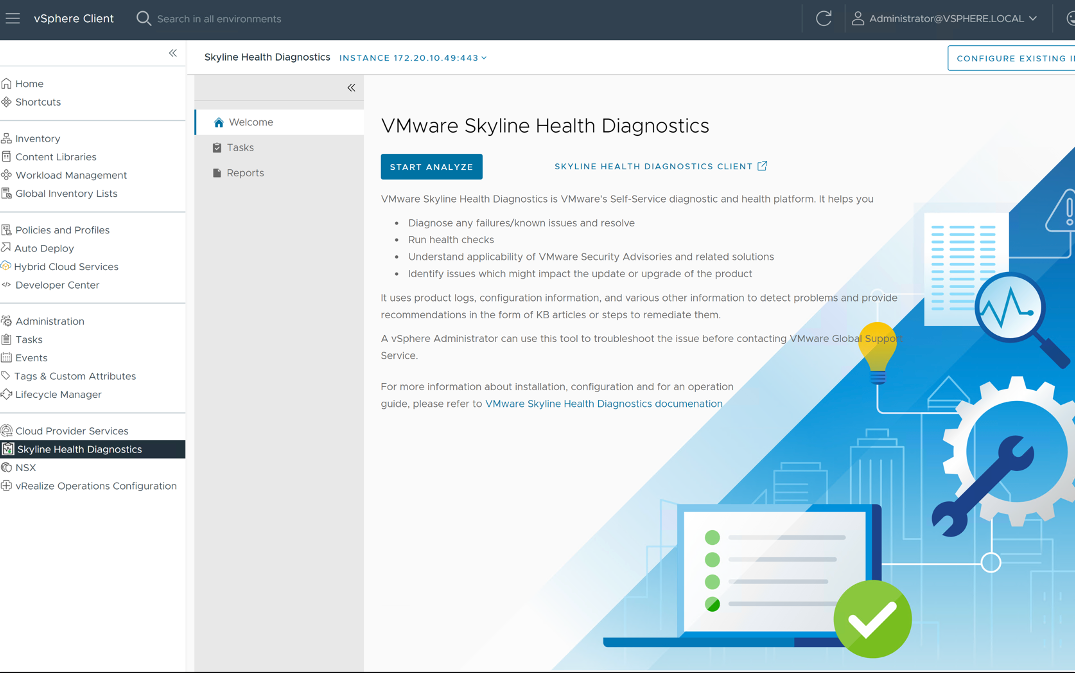
Por si esto fuera poco, vSphere 8 Update 1 introdujo un workflow en el vSphere Client para desplegar y registrar el Skyline Health Diagnostics y de esta manera registrarlo facilmente con vCenter.
Mejoras en Seguridad
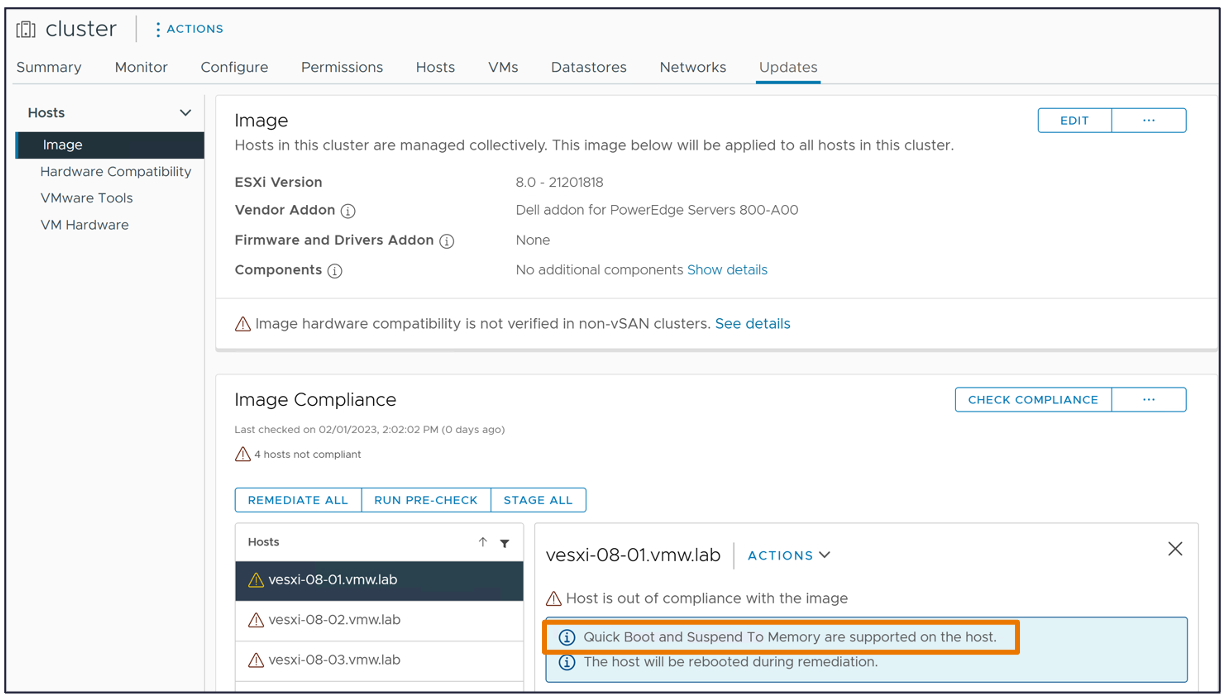
La seguridad es una prioridad constante. En vSphere 8 Update 1, se ha abordado la compatibilidad entre ESXi Quick Boot (introducido en vSphere 6.7) y TPM 2.0, permitiendo un reinicio rápido sin comprometer la seguridad.
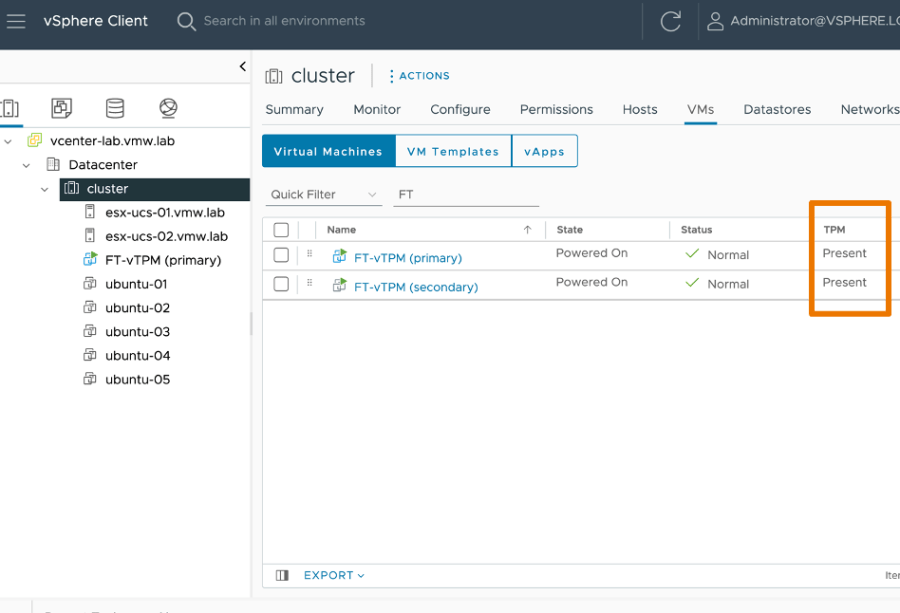
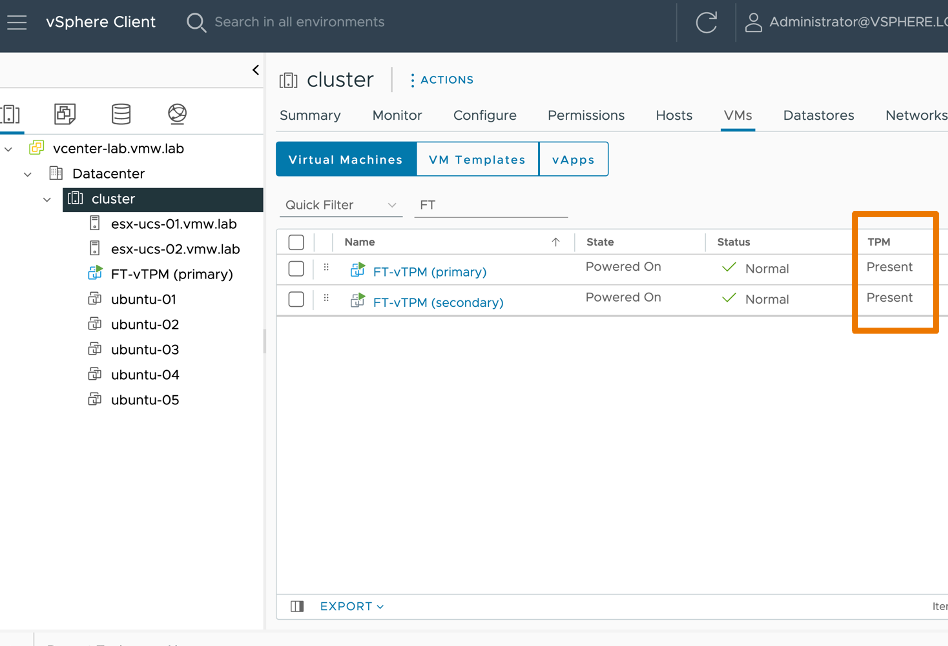
También se ha mejorado el soporte para vTPM, permitiendo que las máquinas virtuales protegidas con vTPM sean totalmente tolerantes a fallos, es decir que podamos protegerlas con Fault Tolerance.
Identidad y Autenticación
Se introdujo soporte para el proveedor de identidad Okta, lo que permite una gestión más moderna de identidades y autenticación multifactor. Esto se alinea con las mejores prácticas de seguridad actuales. Lo mejor es que no se require el uso de ADFS, nos permite introducir 2FA/MFA y además nos permite tener un Single Sing-On consistente dentro de la organización.
Potenciar Cargas de Trabajo
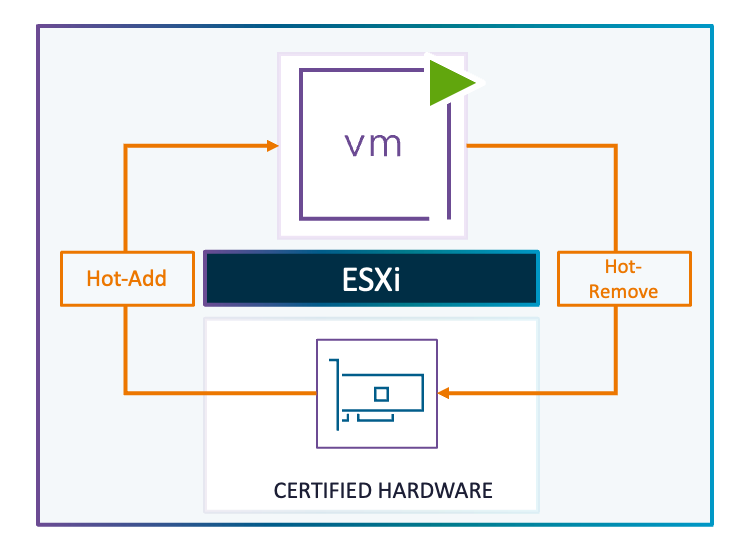
Hemos realizado importantes mejoras en VM DirectPath I/O, permitiendo la adición y eliminación en caliente de dispositivos NVMe, usando APIs, lo que reduce el tiempo de inactividad de la carga de trabajo.
Además, se extendió el soporte para la tecnología NVIDIA NVSwitch, que permite una comunicación de alta velocidad entre múltiples GPUs, llegando hasta 900 GB/s, lo que es crucial para aplicaciones de inteligencia artificial y computación de alto rendimiento. En esta versión (vSphere 8.0 U1) podíamos conectar hasta 8 GPUs en un Switch NVIDIA usando el protocolo NVLink
Conclusión
Estas mejoras en vSphere 8 Update 1 no solo mejoraron la eficiencia operativa y la seguridad, sino que también permitieron a los clientes aprovechar al máximo sus cargas de trabajo. Para más información y recursos adicionales, visita el Centro de Recursos de VMware.
¡Gracias por tu atención y espero que encuentres útiles estas nuevas características que fueron lanzadas hace un tiempo pero que probablemente no sabías, no recordabas o nunca habías escuchado hablar de ellas! No vemos en el vSphere 8 Update 2 y Update 3 para completar este path de adopción de la tecnología vSphere.
Recursos
¡IMPORTANTE! He migrado blog del dominio nachoaprendevirtualizacion.com a nachoaprendeit.com. Si te ha servido este artículo deja tu buen Like y compártelo con tus colegas, estas aciones me ayudarán a optimizar los motores de búsqueda para llegar a más personas, y a motivarme a seguir compartiendo este tipo de artículos.
TODOS LOS NOMBRES DE VMS USADOS EN ESTE BLOG SON INVENTADOS Y OBEDECEN A UN AMBIENTE DE LABORATORIO PROPIO, UTILIZADO PARA FINES DE ESTUDIO.
¡Bienvenidos a esta serie post con visión técnica de lo nuevo que ha venido incorporando vSphere en los últimos años!
¿POR QUÉ AHORA?
Si bien esta información salió hace algunos años, en el campo me he dado cuenta que muchos de nuestros cliente siguen usando vSphere en sus versiones 8.x sin saber que funcionalidades se han incluido.
Ya esta disponible VCF 9.0 y con el nuevas funcionalidades para vSphere 9.0, pero antes de llegar allá enfoquémonos en lo que la mayoria de nuestros clientes tienen actualmente y en cómo podemos ayudarlos a sacarle el mayor provecho a su infraestructura. Así que con el fin de mejorar la adopción de VMware Cloud Foundation en nuestros clientes, partners y comunidad en general, he decidido crear una serie de blogs, donde resumiremos las mejoras incorporadas en cada uno los lanzamientos de las productos que componen la solución de VCF.
Ahora, teniendo en cuenta que vSphere es el Core, comenzaremos por aquí. En este blog, exploraremos de forma muy resumida las características más destacadas y las mejoras que vSphere 8.0 GA trajo a la mesa hace un par de años (2022/10/11).
Para no hacer este blog tan largo, explicaremos solo lo correspondiente a vSphere 8.0 GA y en las siguiente entradas, hablaremos de las características que se han venido incorporando con el lanzamiento de cada uno de los updates. Esto con el objetivo de tener al final una visión general de la evolución del producto hasta la fecha. ¡Así que vamos a sumergirnos en el contenido!
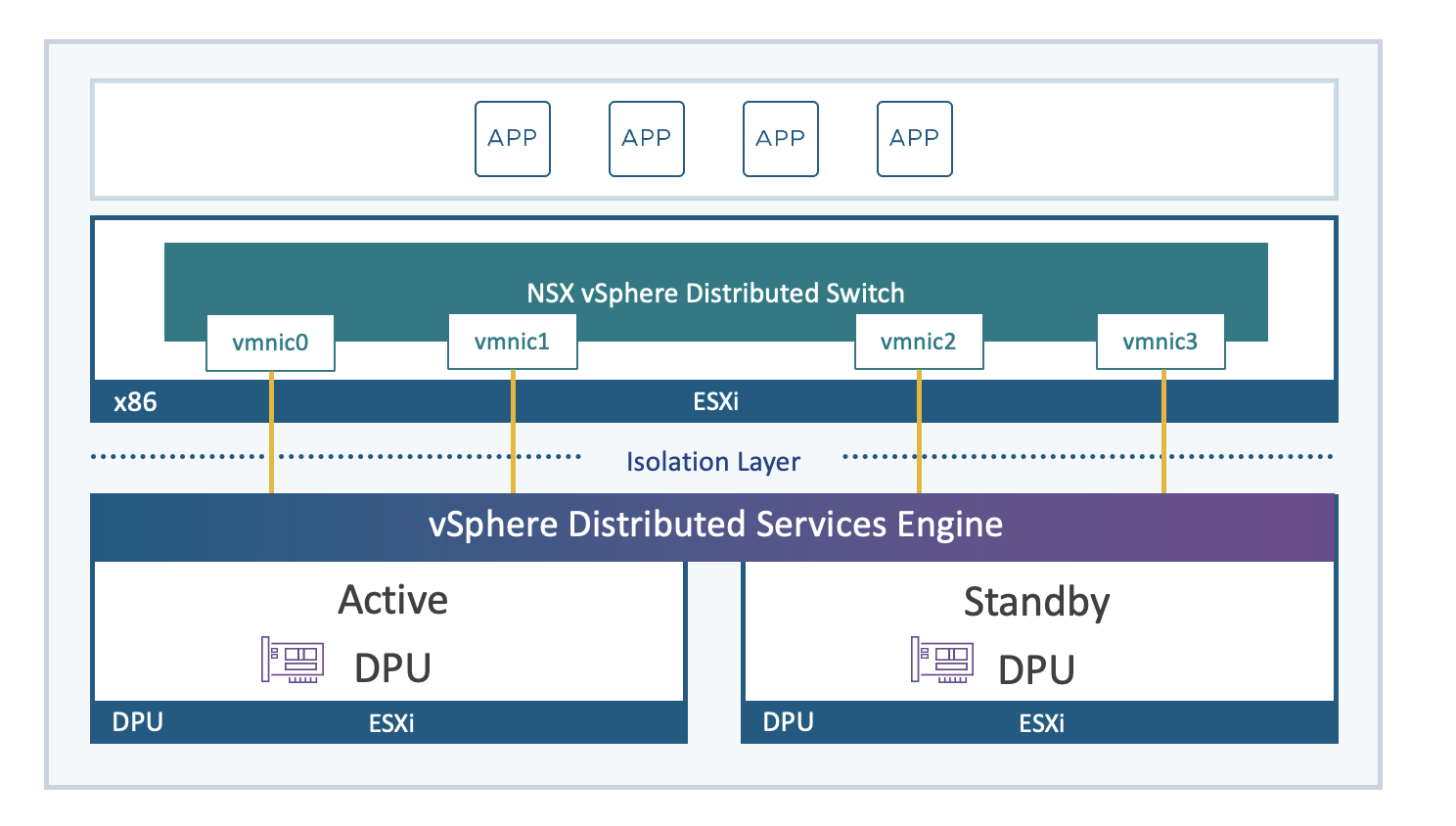
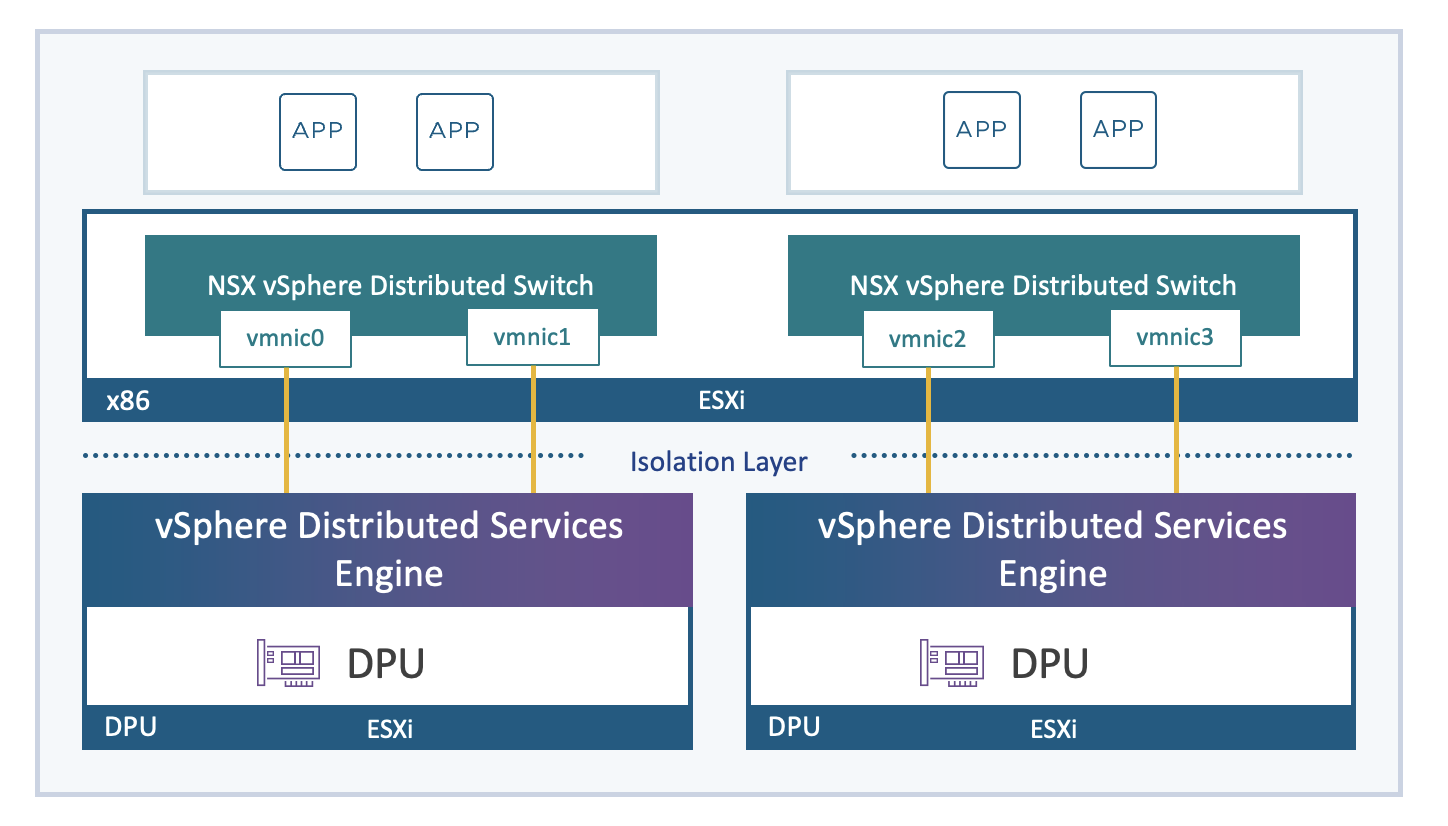
vSphere Distributed Service Engine
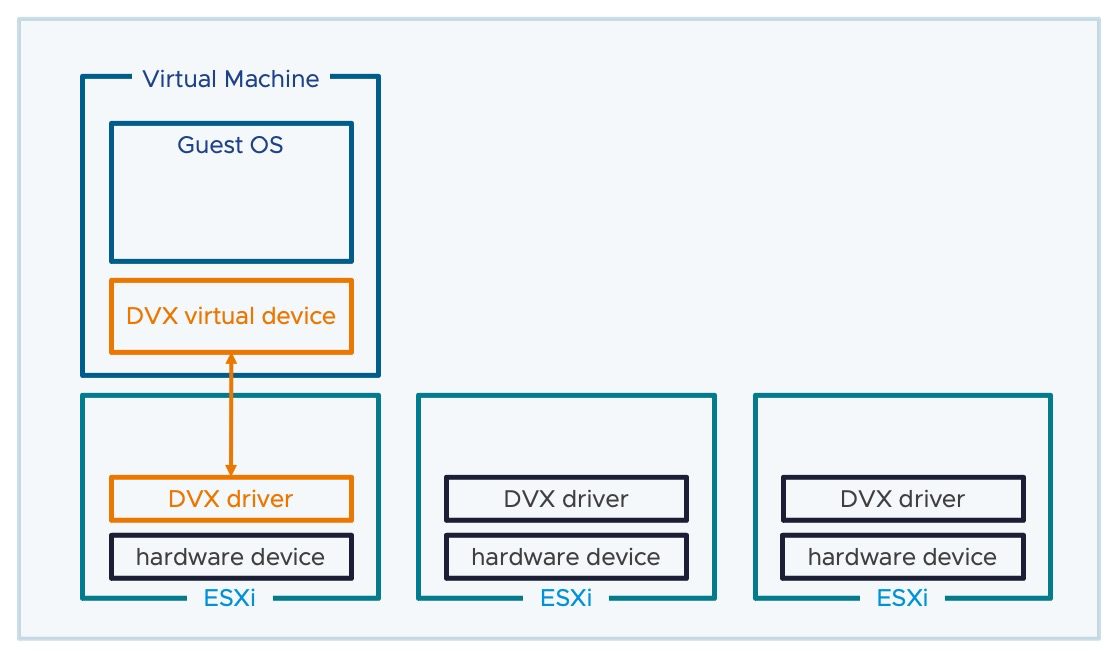
Comencemos hablando sobre el vSphere Distributed Services Engine, que nació como Proyecto Monterey. Este motor ha evolucionado y se lanzó con vSphere 8.0 GA, permitiendo mover funcionalidades desde el host hacia una Data Processing Unit (DPU) o unidad de procesamiento de Datos. Su principal objetivo es desbloquear el poder de las Data Processing Unit (DPU) para el procesamiento de datos acelerado por hardware, lo que ofrece una mejora en el rendimiento de la infraestructura. Ahora, usar estas DPU en tus cargas de trabajo es más sencillo que nunca.
Pero, ¿qué es una DPU? Es un dispositivo similar a un dispositivo PCIe como una NIC o una GPU, que reside en la capa de hardware. Contiene cierta capacidad de cómputo, almacenamiento, memoria y tiene interfaces de red, por lo que se le conoce también como SmartNIC porque Incluye un procesador ARM, 16-32GB RAM, high speed ethernet de 10GB a 100 GB, interfaz de Management de 1GB, y Sensores. Lo interesante aquí es que hasta el lanzamiento de vSphere 8.0 GA, nuestros servicios de red, almacenamiento y gestión de hosts funcionaban únicamente en una instancia de ESXi x86, virtualizando la capa de cómputo. Con vSphere 8.0 GA, se agregó una instancia adicional de ESXi directamente en la DPU, lo que permite descargar servicios de ESXi hacia este dispositivo, comenzando con algunos servicios de red y seguridad de NSX, aumentando así el rendimiento de la plataforma. Se espera que en futuros releases, se amplíe el soporte para la descarga de más funcionalidad hacia el dispositivo DPU. Clic en el siguiente enlace obtener más información acerca de ESXi Installation on DPU
Nota: Hasta esta versión vSphere 8.0 GA, solo estaban soportados de tipos de DPU, NVIDIA y Pensando. Pero como veremos en los siguientes post asociados a los Updates de vSphere 8.0, nuevos modelos y partners se han unido a la fiesta!
Esto libera parte del poder de cómputo x86 y lo devuelve a nuestras aplicaciones y cargas de trabajo. Para aprovechar el vSphere Distributed Services Engine, necesitas utilizar un Switch Distribuido de vSphere versión 8 y NSX. Esto te permitirá seleccionar la compatibilidad de descarga de red y elegir la DPU adecuada en tu entorno.
Mejoras en vSphere con Tanzu
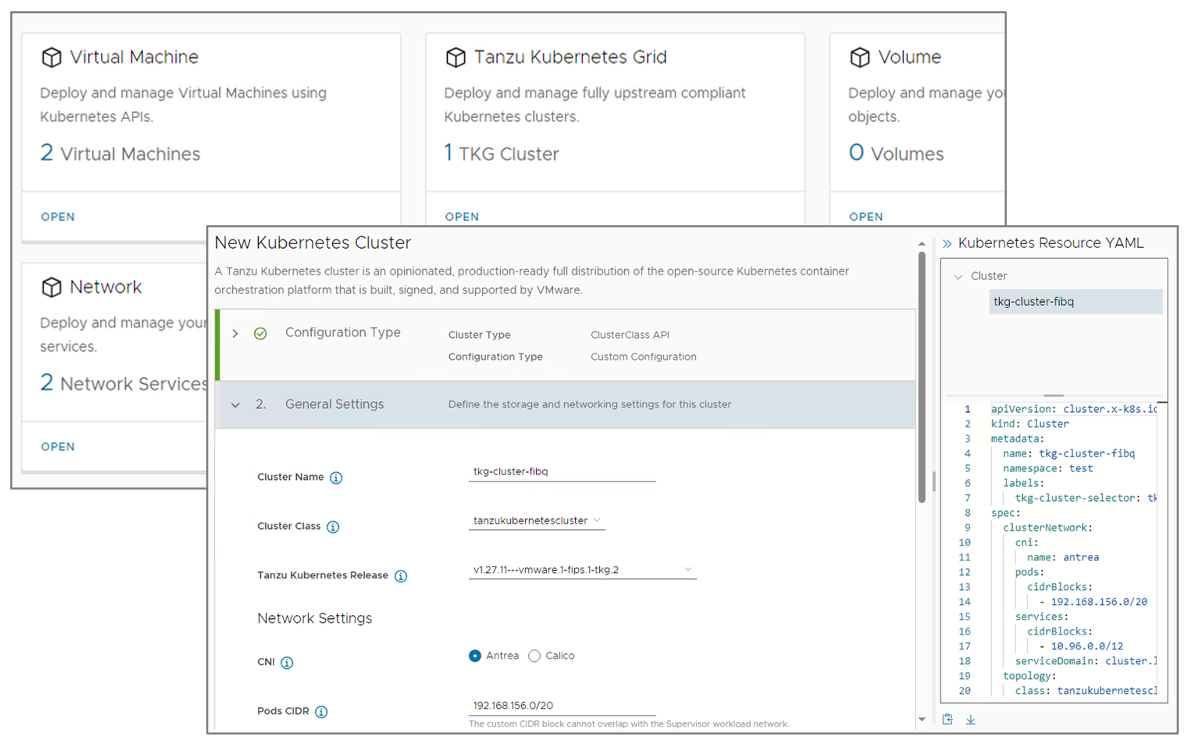
Pasemos ahora a las mejoras en vSphere con Tanzu. Introducido en vSphere 7, vSphere con Tanzu trajo consigo Tanzu Kubernetes Grid (TKG) y varias versiones. Con vSphere 8, se consolidaron estas diferentes versiones en un único runtime de Kubernetes unificado, que se utiliza para desplegar Kubernetes en clústeres de vSphere, nubes públicas y privadas.
Una nueva característica en vSphere 8.0 GA es el concepto de vSphere Zones. Esto se utiliza para aislar cargas de trabajo a través de clústeres de vSphere y permite que se extiendan o abarquen múltiples clústeres para maximizar la disponibilidad y el consumo de recursos, evitando a su vez que tengamos un único punto de falla a nivel del vSphere Cluster que soporta la solución de vSphere with Tazu.
Por otro lado, incorporamos el concepto de ClusterClass en VMware vSphere with Tanzu, que no es más que una forma declarativa de, especificar la configuración y gestionar el ciclo de vida de clústeres de Kubernetes a través de un cluster de gestión de Kubernetes que, para vSphere with Tanzu, es conocido como Supervisor Cluster. Utilizando esta nueva funcionalidad podemos incluso decidir los paquetes de infraestructura que se deben instalar al crear el clúster. El ClusterClass puede incluir especificaciones asociadas a proveedores de red, almacenamiento y nube, así como el mecanismo de autenticación y la recopilación de métricas. De esta manera podemos definirlo una vez y aplicarlo múltiples veces.
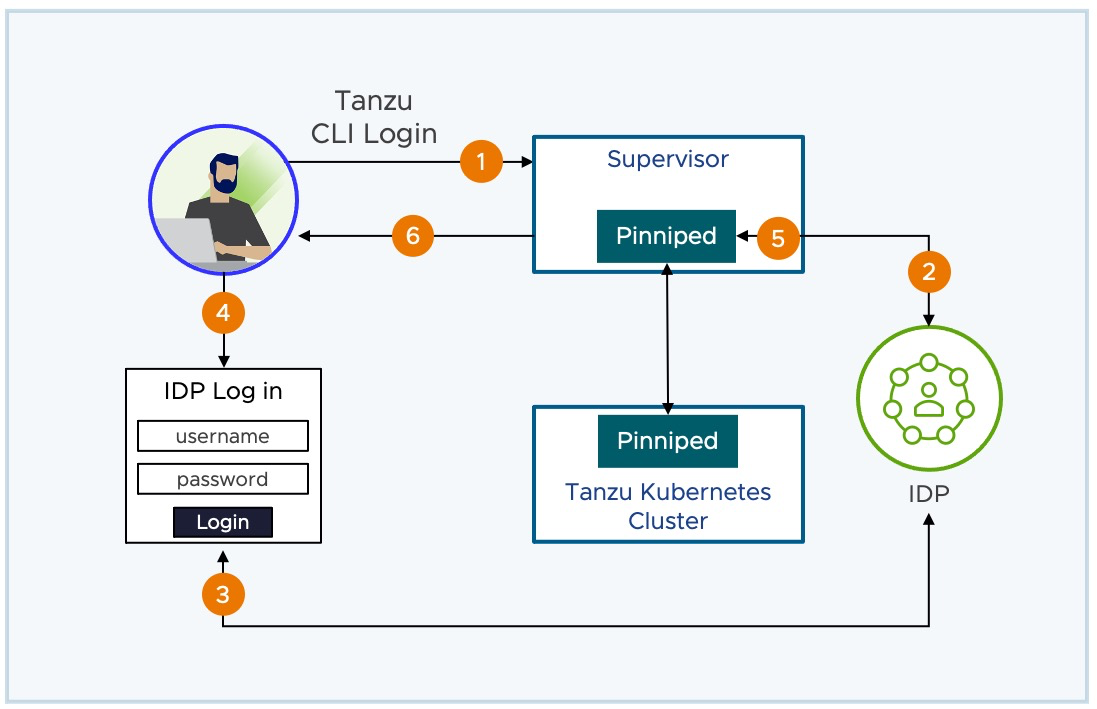
Nota: Las imágenes de Photon OS y Ubuntu ahora se pueden personalizar y guardar de nuevo en la Content Library para su uso en clústeres de Kubernetes de Tanzu. También se integró la autenticación de Pinniped tanto en el Supervisor Cluster como en los clústeres TKG para la gestión de identidades federadas.
Autenticación Federada con Pinniped
En vSphere 7, toda la autenticación se realizaba a través de la integración con vCenter SSO. En vSphere 8.0 GA, tienes una alternativa: la integración con Pinniped. Esta integración permite que el Supervisor Cluster y los clústeres de Kubernetes de Tanzu accedan directamente a un proveedor de identidad OIDC(OpenID Connect), sin depender de vCenter SSO. Los pods de Pinniped se despliegan automáticamente en el Supervisor Cluster y en los clústeres de Tanzu para admitir esta funcionalidad.
Gestión del Ciclo de Vida
Ahora veamos la gestión del ciclo de vida. vSphere Lifecycle Manager (vLCM) ha mejorado, permitiendo la remediación paralela de hosts, lo que reduce el tiempo total de operación. Recordemos que al remediar un host ESXi que contiene una DPU, también hay un evento de remediación la instancia de ESXi que existe en el dispositivo DPU. La buena noticia es que vSphere Lifecycle Manager Images es consciente de eso, por lo que no tienes nada de que preocuparte a nivel de la gestion del ciclo de vida de dicha instancia de ESXi.
Tambien se introdujo el soporte de staging en vSphere Lifecycle manager Images y la remediación paralela, lo que mejora el tiempo total de remediación al realizar operaciones de ciclo de vida en tus clústeres de vSphere.
Nota: Es importante mencionar que la gestión de actualizaciones de baselines está obsoleta en vSphere 8.0, lo que significa que debes comenzar a migrar a un enfoque declarativo basado en Images (vSphere Lifecycle Manager Images).
Por otro lado, a nivel del vCenter Server, redujimos los problemas que habían durante el proceso de recuperación. En esta versión el vCenter concilia el estado del clúster, después de una restauración a partir de una copia de seguridad, contra un nuevo componente llamado Distributed Key-Value Store que se aloja en los hosts ESXi de un clúster, y almacena el estado y la configuración del clúster, y ahora es considerado por el vCenter como la fuente de información veraz para el estado y la configuración de los clústers de vSphere. De esta manera los cambios realizados después de la ejecución del backup del vCenter, no seperderán ni generarán errores en caso de una restauraciónn sino queserán conciliados con el Distributed Key-Value Store para que el vCenter pueda actualizar su base de datos utilizando dicha información.
Ademas, en esta version se introdujo una nueva vista previa técnica de los vSphere Configuration Profiles, que será nuestra próxima generación de gestión de configuración de clústeres, podriamos decir que es la evolución de los Host Profiles.
Nota: En la version vSphere 8.0 GA, la gestión de Images desde vSphere Lifecycle Manager para un host standalone se podia realizar a través de las API unicamente. Sin embargo, es importante mencionar vSphere Lifecycle Manager Baselines, también conocida como Update Manager, está en proceso de obsolecencia en vSphere 8.x.
Inteligencia Artificial y Aprendizaje Automático
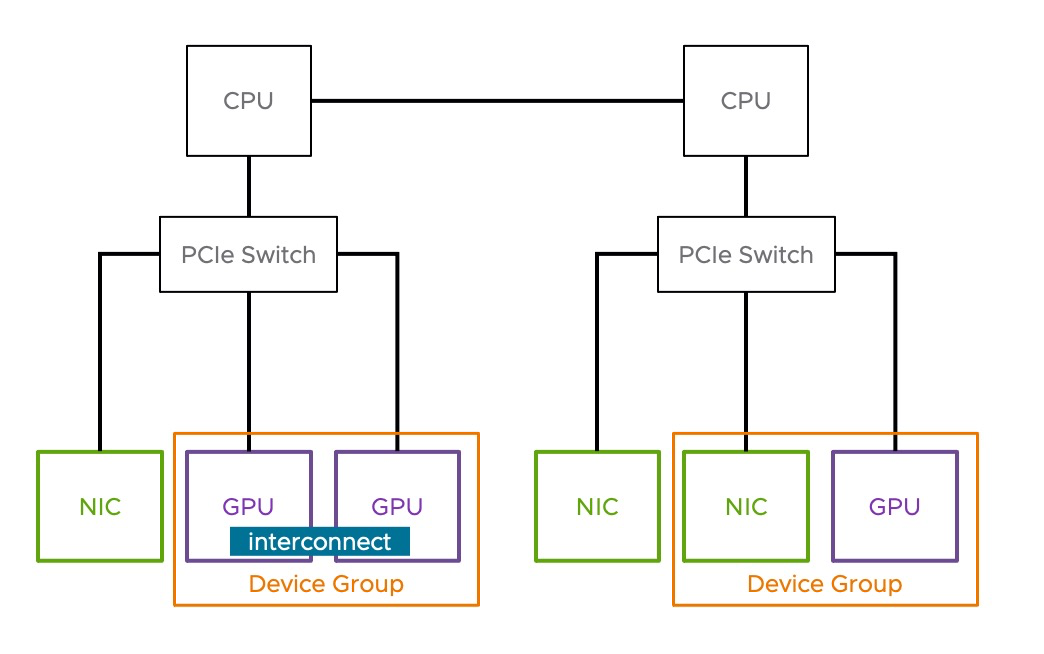
En cuanto a la inteligencia artificial y el aprendizaje automático, estas áreas están creciendo rápidamente y requieren hardware acelerado, típicamente en forma de GPUs. vSphere ofrece ahora la posibilidad de soportar Device Groups, que es una configuración realizada en la capa del hardware, que permite definir dispositivos PCI comunes GPUs y NICs que hacen parte de un mismo PCIe Switch. Esto simplifica la asignación de dispositivos a máquinas virtuales, ya que los dispositivos se presentan como una unidad única a nivel de la capa de virtualización.
Nota: Uno de nuestros primeros partners en apoyar los Device Groups es NVIDIA, que lanzó un controlador compatible para esta funcionalidad. Esto permite a DRS y vSphere HA trabajar con Device Groups para la colocación de máquinas virtuales y la recuperación ante fallos.
En versiones anteriores, las máquinas virtuales que consumían dispositivos de hardware físico mediante DirectPath IO o Dynamic DirectPath IO tenían una movilidad limitada. En vSphere 8.0 GA, se ha resuelto este problema con Enhanced DirectPath I/O (Device Virtualization Extension) el cual se basa en Dynamic DirectPath IO e introduce un nuevo marco y API para que los proveedores creen dispositivos virtuales respaldados por hardware para permitir una mayor compatibilidad con funciones de virtualización, como la migración mediante vSphere vMotion, la suspensión y reanudación de una máquina virtual y la compatibilidad con instantáneas de disco y memoria. Ahora la mobilidad esta parmitida gracias a un drive instalado tanto en el Guest OS como en el hipervisor.
Mejoras en el Sistema Operativo Invitado y Cargas de Trabajo
En esta sección, exploraremos algunas mejoras en el sistema operativo invitado y las cargas de trabajo. Cada nueva versión de vSphere introduce una nueva versión de hardware virtual, y en esta ocasión, hemos llegado a la versión 20. Esto permite aumentos en los máximos de cómputo y desbloquea muchas características nuevas.
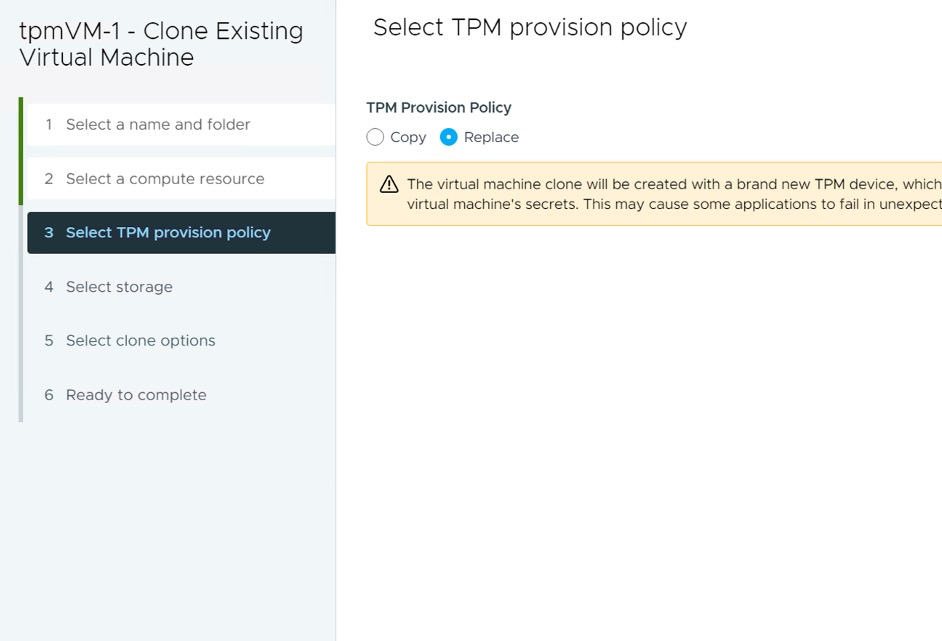
Una de las nuevas políticas es la provisión de TPM virtual, diseñada para ayudar a implementar cargas de trabajo de Windows 11 a gran escala. En vSphere 8.0 GA, los dispositivos vTPM se pueden reemplazar automáticamente durante las operaciones de clonación o implementación. Esto permite seguir las prácticas recomendadas de que cada máquina virtual contenga un dispositivo TPM único.
Además, estamos simplificando la configuración de vNUMA y aumentando los máximos de cómputo, permitiendo hasta ocho dispositivos vGPU por máquina virtual.
Notificaciones de vMotion
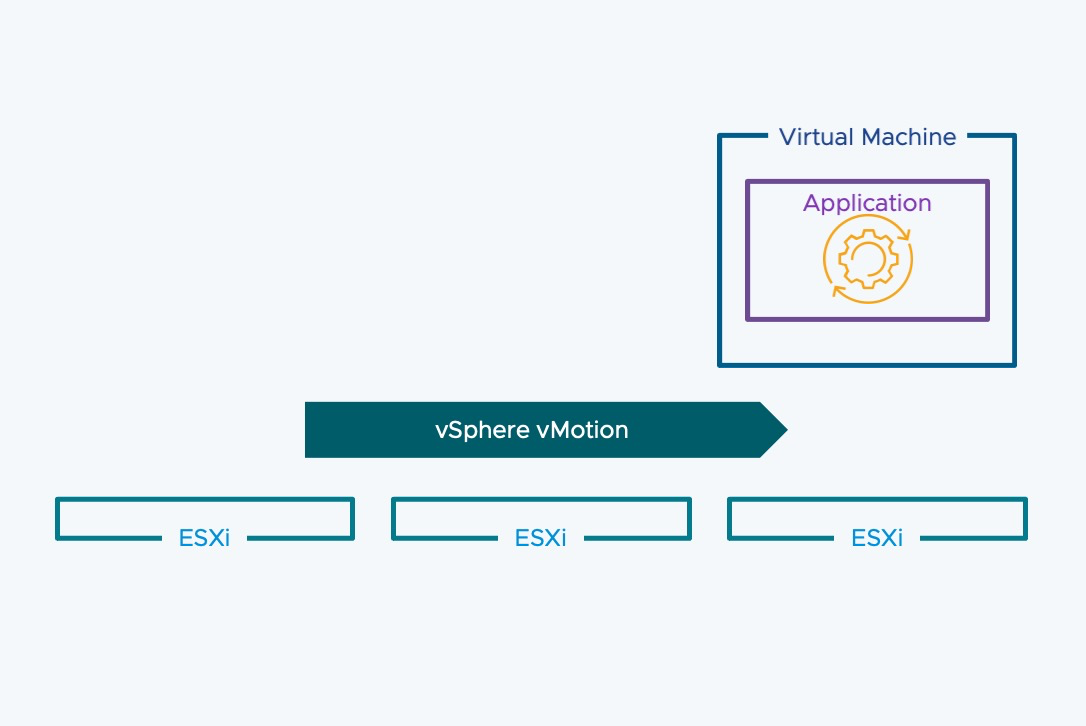
También estamos introduciendo las notificaciones de vMotion, que permiten que las máquinas virtuales sean conscientes de los eventos de vMotion, lo que es crucial para aplicaciones sensibles a la latencia. Esto permite que las aplicaciones realicen trabajos previos de preparación a la migración, como detener servicios o hacer failover de manera controlada.
Nota: Las aplicaciones se debe ser reescritas para que admitan las notificaciones de vMotion. O se puede escribir una aplicación asociada como intermediaria entre las notificaciones de vMotion y la aplicación principal.
Gestión de Recursos y Sostenibilidad
En el ámbito de la gestión de recursos, se mejora el rendimiento de DRS mediante un mejor aprovechamiento de las estadísticas de memoria que fueron introducidas en vSphere 7U3. vSphere Memory Monitoring and Remediation (vMMR) ayuda a cubrir la necesidad de monitoreo al proporcionar estadísticas de ejecución tanto a nivel de VM (ancho de banda) como de Host (ancho de banda, tasas de errores). vMMR también proporciona alertas predeterminadas y la capacidad de configurar alertas personalizadas basadas en las cargas de trabajo que se ejecutan en las VM.
En vSphere 8, el rendimiento de DRS se mejora significativamente aprovechando las estadísticas de memoria, lo que da como resultado decisiones de ubicación óptimas para las máquinas virtuales sin afectar el rendimiento ni el consumo de recursos.
También se introdujo métricas verdes para monitorear las emisiones de energía y carbono de la infraestructura de vSphere y las cargas de trabajo, ayudando a las organizaciones a visualizar su huella de carbono.
Nota: Usage es una metrica de potencia real medida en función del uso activo de la CPU y la memoria de las máquinas virtuales. Se deriva de los medidores de potencia conectados a los hosts (IPMI, interfaz de administración de plataforma inteligente).
Nota: Static Power es una metrica potencia inactiva modelada de la máquina virtual, como si la máquina virtual fuera un host físico hipotético configurado con la misma cantidad de CPU y memoria que la máquina virtual.
Seguridad y Cumplimiento
Finalmente, en términos de seguridad, vSphere 8.0 GA es más seguro por defecto. Se eliminó la opción de usar TLS 1.0 y 1.1, dejando solo TLS 1.2 como opción. También se implementó restricciones para evitar que binarios no confiables se ejecuten en ESXi, lo que significa que solo se pueden ejecutar paquetes firmados.
Además, se introduce un tiempo de espera automático para SSH, que se deshabilitará automáticamente si no se utiliza, ayudando a mitigar posibles vectores de ataque.
Conclusión
Esto ha sido un resumen técnico de las novedades en vSphere 8.0 GA. Hay mucho más que explorar y descubrir así que te invito a seguir nuestro blog, y participar en este bonito camino de adopción de nuestras tecnologías VMware By Broadcom.
Recuerda que estamos haciendo un repaso de las funcionalidades que han sido liberadas en cada uno de los updates de vSphere. Posteriormente haremos lo mismo con vSAN, NSX, VCF, y los productos que componen la Aria Suite.
¡Gracias por tu atención y espero que encuentres útiles estas nuevas características que fueron lanzadas hace un tiempo pero que probablemente no sabías, no recordabas o nunca habías escuchado hablar de ellas!
Recursos
¡IMPORTANTE! He migrado blog del dominio nachoaprendevirtualizacion.com a nachoaprendeit.com. Si te ha servido este artículo deja tu buen Like y compártelo con tus colegas, estas aciones me ayudarán a optimizar los motores de búsqueda para llegar a más personas, y a motivarme a seguir compartiendo este tipo de artículos.
TODOS LOS NOMBRES DE VMS USADOS EN ESTE BLOG SON INVENTADOS Y OBEDECEN A UN AMBIENTE DE LABORATORIO PROPIO, UTILIZADO PARA FINES DE ESTUDIO.
En esta oportunidad explicaremos como abordar una situación en la cual al intentar crear el cluster vSAN de forma manual a través del asistente de configuración, no tenemos disponibles algunos discos que deberían aparecer para la creación de los Disk Groups. En ese momento nos preguntaremos ¿Por qué no aparecen todos los discos disponibles?, pues bien lo más probable es que el o los discos que no aparecen listados para ser Claimed por vSAN no están vacíos y deban ser formateados para poderlos liberar.
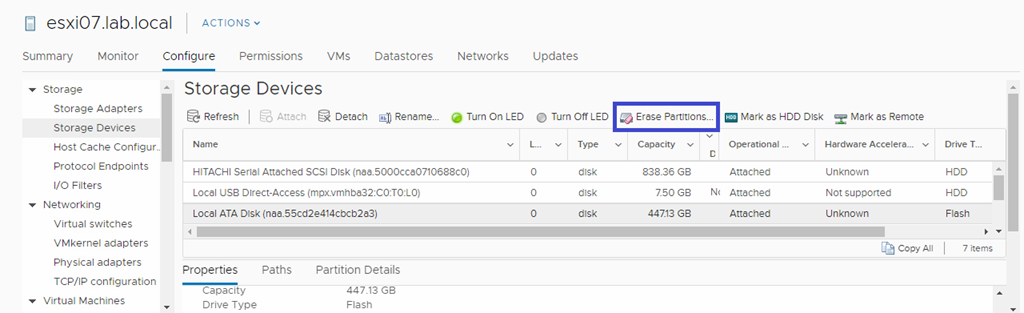
Es aquí donde nos podríamos encontrar con un error común que puede convertirse en un dolor de cabeza sino conocemos su causa raíz. El error básicamente se produce al intentar ejecutar la acción Erase Partitions en la configuración del host en el apartado Configure->Storage->Storage Devices, como se muestra en la siguiente imagen.
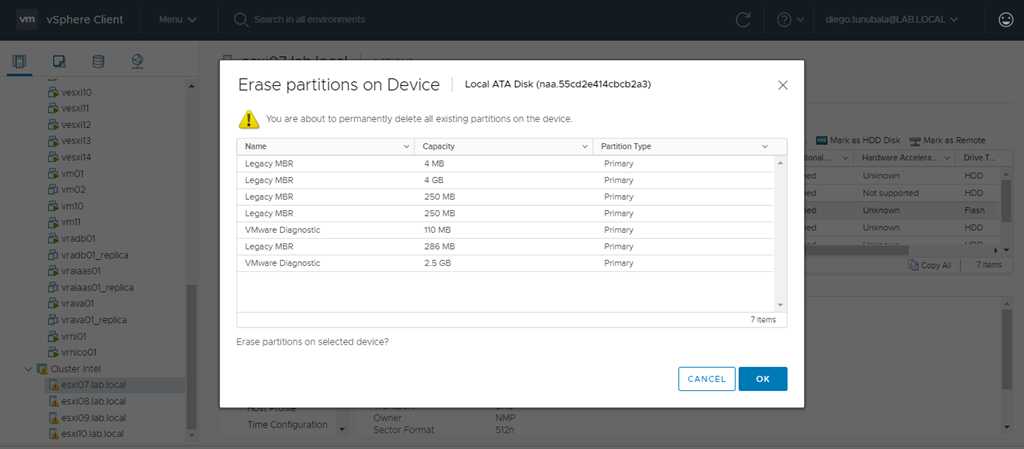
Al hacer clic sobre la opción anterior nos mostrará un resumen de las particiones con las que cuenta este disco y razón por la cual no esta disponible para el asistente de configuración de VSAN.
Al hacer click sobre el botón OK, en la mayoría de los casos, las particiones serán eliminadas y el disco quedará disponible para vSAN. Una forma rápida de verificarlo es que al hacer nuevamente clic sobre Erase Partition, no debería listar ninguna partición y el asistente de configuración de vSAN debería ahora listar el o los discos.
¿Y SI FALLA?…
Es ahora cuando aparece el problema ¿Que hacemos si esta tarea falla y nos muestra el siguiente error: “Cannot change the host configuration”? Primero que todo ¡calma, calma!, no tenemos que ir a ninguna línea de comandos a intentar limpiar estas particiones, la solución es mucho más sencilla que eso.
Nota 1: Para las versiones de ESXi anteriores a 7,0, scratch partition es un espacio temporal que se configura automáticamente durante la instalación o el primer arranque de un host ESXi. El instalador de ESXi crea una partición FAT16 de 4GB en el dispositivo de destino durante la instalación si hay suficiente espacio y si el dispositivo se considera local. Esta partición no es creada cuando el hipervisor se instala en tarjetas SD o unidades flash USB.
Nota 2: Si no existe espacio temporal persistente disponible en el disco local o la partición no es creada (en el caso de SD, Flash USB), ESXi almacenará estos datos temporales en la memoria RAM. Esto puede ser problemático en situaciones con poca memoria, pero no es fundamental para el funcionamiento de ESXi.
Explicado lo anterior, el problema pudo haberse producido si ese disco o discos, en algún momento fueron formateados como Datastore (VMFS), y esto hace que el hipervisor configure ese datastore como su mejor candidato para ubicar el Scratch Partition (Partición creada para almacenar la salida de vm-support necesaria para el soporte de VMware).
Por esta razón, la solución a este problema se basa en cambiar la configuración asociada a la opción avanzada del hipervisor ScratchConfig.ConfiguredScratchLocation, que probablemente estará apuntando al datastore local que en algún momento se configuró en dicho disco.
SOLUCIÓN
1. Si ya tiene vCenter instalado navegue en el inventario hasta el Host –> Configure –> Advanced System Settings. Clic en Edit… y en el filtro escriba ScratchConfig.ConfiguredScratchLocation.
2. Sino tiene instalado un vCenter aún, inicie sesión en el Host Client del host en cuestión (en cualquier navegador web https://IP_FQDN_Host ) y navegue hasta Manage->System-> Advanced Settings y en el buscador escriba ScratchConfig.ConfiguredScratchLocation o simplemente Scratch.
3. Independientemente de si se realizó el paso anterior desde el vCenter o desde el Host Client, podrá ver que en el campo value aparecerá la ruta hacia un datastore, lo único que debemos hacer es editar este valor y colocar /tmp, para redireccionarlo a la memoria RAM (no recomendado) o especificar la ruta de un almacenamiento persistente diferente.
Nota 3: Al editar el valor de ScratchConfig.ConfiguredScratchLocation será /tmp, mientras el valor de ScratchConfig.CurrentScratchLocation permanecerá sin cambios. Esto se debe a que es necesario realizar un reinicio del host para que los mismo sean aplicados.
4. Una vez realizado el reinicio, inicie sesión nuevamente en el Host Client y navegue hasta Manage->System-> Advanced Settings. En el buscador escriba ScratchConfig.ConfiguredScratchLocation o simplemente Scratch.
En la columna value podrá observar que el valor tanto para ScratchConfig.ConfiguredScratchLocation como para ScratchConfig.CurrentScratchLocation es /tmp.
5. Por ultimo, intente nuevamente la acción Erase Partition.
Desde el vCenter
o desde el Host Client (Clear partition table)
Y notará que la tarea finaliza con éxito.
En este momento ya habrá liberado el o los discos y ahora estarán disponibles para ser reclamados por VSAN desde el asistente de configuración.
ATENCIÓN!!!
TODOS LOS NOMBRES DE VMS USADOS EN ESTE BLOG SON INVENTADOS Y OBEDECEN A UN AMBIENTE DE LABORATORIO PROPIO, UTILIZADO PARA FINES DE ESTUDIO.
En esta ocasión se presenta un procedimiento fácil y rápido para silenciar las alarmas generadas por el health check de vSAN, que puede ser utilizado en ambientes Nested (ESXi virtualizados) o en ambientes de laboratorio propiamente dichos. Esta puede ser una opción para omitir algunas de la verificaciones debido a que no siempre contamos con las condiciones de hardware, firmware y drivers apropiados para implementar la solución; ni mucho menos contamos con vSAN ReadyNodes disponibles para una POC (Proof of Concept).
¡CUIDADO! En ningún momento se recomienda este procedimiento en ambientes vSAN productivos ya que todos los componentes de hardware, drivers y firmware deben coincidir con la Guía de Compatibilidad de VSAN indicada para los nodos que conforman la solución.
Antes de iniciar el procedimiento comentemos un poco acerca de RVC (Ruby vSphere Console). Es una consola de línea de comando para VMware vSphere y Virtual Center. Ruby vSphere Console es basada en la popular interface RbVmomi Ruby para vSphere API. RbVmomi fue creada para reducir drásticamente la cantidad de codificación requerida para realizar tareas rutinarias, así como aumentar la eficacia de la ejecución de tareas, al tiempo que permite la máxima potencia de la API cuando es necesario. RVC se encuentra incluida en el vCenter Server Appliance (VCSA) y la versión de Windows de vCenter Server, y se ha convirtiendo en una de las principales herramientas para administrar y solucionar problemas de entornos Virtual SAN (vSAN).
RVC tiene muchas de las capacidades que se esperan de una interfaz de línea de comandos.
Finalización de tabulación
Comodines
Marcas
Modo Ruby
Modo Python
Introspección VMODL
Conexiones múltiples
Extensibilidad
Guiones de Ruby de una sola línea
Casos de uso y ventajas de RVC
Funcionalidad Virtual SAN cubierta
Configuración de VSAN y políticas de almacenamiento
Comandos de monitorización / resolución de problemas
Monitoreo del desempeño a través de VSAN Observer
Ventajas
Más información detallada sobre Virtual SAN vSphere Web Client
Vista de grupo de VSAN mientras que esxcli solo puede ofrecer una perspectiva de servidor
Operaciones masivas a través de comodines
Funciona directamente contra ESX host, incluso si VC no funciona
1. Tenga presente que existe una lista de checks o validaciones que están disponibles para ser configurados y se encuentran consignados en la siguiente tabla. De manera que primero debemos verificar si la alarma que muestra el monitor de salud de vSAN se encuentra en éste listado.
Descripción
Check ID
Cloud Health
Controller utility is installed on host
vendortoolpresence
Controller with pass-through and RAID disks
mixedmode
Customer experience improvement program (CEIP)
vsancloudhealthceipexception
Disks usage on storage controller
diskusage
Online health connectivity
vsancloudhealthconnectionexception
vSAN and VMFS datastores on a Dell H730 controller with the lsi_mr3 driver
mixedmodeh730
vSAN configuration for LSI-3108 based controller
h730
vSAN max component size
smalldiskstest
Cluster
Advanced vSAN configuration in sync
advcfgsync
Deduplication and compression configuration consistency
physdiskdedupconfig
Deduplication and compression usage health
physdiskdedupusage
Disk format version
upgradelowerhosts
ESXi vSAN Health service installation
healtheaminstall
Resync operations throttling
resynclimit
Software version compatibility
upgradesoftware
Time is synchronized across hosts and VC
timedrift
vSAN CLOMD liveness
clomdliveness
vSAN Disk Balance
diskbalance
vSAN Health Service up-to-date
healthversion
vSAN cluster configuration consistency
consistentconfig
vSphere cluster members match vSAN cluster members
clustermembership
Data
vSAN VM health
vmhealth
vSAN object health
objecthealth
Encryption
CPU AES-NI is enabled on hosts
hostcpuaesni
vCenter and all hosts are connected to Key Management Servers
kmsconnection
Hardware compatibility
Controller disk group mode is VMware certified
controllerdiskmode
Controller driver is VMware certified
controllerdriver
Controller firmware is VMware certified
controllerfirmware
Controller is VMware certified for ESXi release
controllerreleasesupport
Host issues retrieving hardware info
hclhostbadstate
SCSI controller is VMware certified
controlleronhcl
vSAN HCL DB Auto Update
autohclupdate
vSAN HCL DB up-to-date
hcldbuptodate
Limits
After 1 additional host failure
limit1hf
Current cluster situation
limit0hf
Host component limit
nodecomponentlimit
Network
Active multicast connectivity check
multicastdeepdive
All hosts have a vSAN vmknic configured
vsanvmknic
All hosts have matching multicast settings
multicastsettings
All hosts have matching subnets
matchingsubnet
Hosts disconnected from VC
hostdisconnected
Hosts with connectivity issues
hostconnectivity
Multicast assessment based on other checks
multicastsuspected
Network latency check
hostlatencycheck
vMotion: Basic (unicast) connectivity check
vmotionpingsmall
vMotion: MTU check (ping with large packet size)
vmotionpinglarge
vSAN cluster partition
clusterpartition
vSAN: Basic (unicast) connectivity check
smallping
vSAN: MTU check (ping with large packet size)
largeping
Performance service
All hosts contributing stats
hostsmissing
Performance data collection
collection
Performance service status
perfsvcstatus
Stats DB object
statsdb
Stats DB object conflicts
renameddirs
Stats master election
masterexist
Verbose mode
verbosemode
Physical disk
Component limit health
physdiskcomplimithealth
Component metadata health
componentmetadata
Congestion
physdiskcongestion
Disk capacity
physdiskcapacity
Memory pools (heaps)
lsomheap
Memory pools (slabs)
lsomslab
Metadata health
physdiskmetadata
Overall disks health
physdiskoverall
Physical disk health retrieval issues
physdiskhostissues
Software state health
physdisksoftware
Stretched cluster
Invalid preferred fault domain on witness host
witnesspreferredfaultdomaininvalid
Invalid unicast agent
hostwithinvalidunicastagent
No disk claimed on witness host
witnesswithnodiskmapping
Preferred fault domain unset
witnesspreferredfaultdomainnotexist
Site latency health
siteconnectivity
Unexpected number of fault domains
clusterwithouttwodatafaultdomains
Unicast agent configuration inconsistent
clusterwithmultipleunicastagents
Unicast agent not configured
hostunicastagentunset
Unsupported host version
hostwithnostretchedclustersupport
Witness host fault domain misconfigured
witnessfaultdomaininvalid
Witness host not found
clusterwithoutonewitnesshost
Witness host within vCenter cluster
witnessinsidevccluster
vSAN Build Recommendation
vSAN Build Recommendation Engine Health
vumconfig
vSAN build recommendation
vumrecommendation
vSAN iSCSI target service
Home object
iscsihomeobjectstatustest
Network configuration
iscsiservicenetworktest
Service runtime status
iscsiservicerunningtest
2. Inicie sesión SSH en el vCenter Server Appliance y conéctese al Ruby vSphere Console (RVC) ejecutando el siguiente comando (sin habilitar el Shell)
3. Ingrese el password del usuario administrator@vsphere.local
Se utilizarán los siguientes comandos RVC para verificar y silenciar las alarmas
vsan.health.silent_health_check_status
vsan.health.silent_health_check_configure
4. Verifique el estado de las alertas con el primer comando, para el cual se debe conocer la ruta de cluster a analizar. Puede apoyarse de los comando cd y ls para navegar hasta encontrar la ruta correcta del cluster vSAN.
5. Desde el vSphere Web Client navegue hasta el NombredelCluster|vSAN|Health para identificar el nombre de la alerta que se desea silenciar, teniendo en cuenta por supuesto que la misma no sea de impacto para la operación normal de la solución, de lo contrario deberá realizarse una adecuada investigación y solución del problema.
Para este caso al ser un ambiente de laboratorio virtualizado, se tiene la alerta SCSI controller is VMware certified que nos indica acerca de la incompatibilidad de la controladora de discos para el uso de vSAN, que no podemos solucionar debido a que la controladora es virtual; por lo tanto puede ser ignorada o silenciada. (¡Recuerde! Esto acción no debe ser realizada en ambientes productivos).
6. En la salida del comando anterior se muestra el mismo listado de Health Checks disponibles para configurar y su estado actual. De manera que para silenciar la verificación SCSI controller is VMware certified, se debe utilizar su correspondiente identificador o Check ID controlleronhcl
7. Ahora solo queda ejecutar el comando de configuración vsan.health.silent_health_check_configure de la siguiente manera para silenciar la alarma
Utilice los parámetros de configuración disponibles, de acuerdo a su necesidad.
-a
–add-checks=
Agregar verificación a la lista silenciosa, uso: -a [Health Check Id].
-r
–remove-cheques=
Eliminar verificación de la lista silenciosa, uso: -r [Health Check Id]. Para restaurar la lista de verificación silenciosa, utilizando ‘-r all’
-i
–interactive-add
Usa el modo interactivo para agregar verificación a la lista silenciosa
-n
–interactive-remove
Usa el modo interactivo para eliminar las verificaciones de la lista silenciosa
-h
–help
Muestra este mensaje
8. Regrese al vSphere Web Client y haga click en Retest en el Health monitor de vSAN para validar el cambio y podrá observar que la alerta aparece ahora como Skipped y no como Warning.
Muchas veces nos encontramos con el dilema de no poder rastrear la ubicación de un disco de la vSAN hasta la ubicación real (slot) en el servidor. Esto por lo general ocurre cuando necesitamos reemplazar un disco perteneciente a un Disk Group que se encuentra alarmado o un Storage Device que se muestra como degradado en la configuración de vSphere, pero a nivel físico no se visualiza ninguna alerta. ¿Como hacemos entonces para saber cuál disco es el que debemos cambiar? Pues bien he aquí un procedimiento sencillo que nos puede ayudar a salir de la incertidumbre.
1. Desde el vSphere Web Client seleccionar el host al que se desea realizar la inspección del discos en el mundo físico, sea éste que se encuentre alarmado o no. Vaya a la pestaña Configure | Storage Devices, y tomar nota de nombre canónico (naa.*) del dispositivo en cuestión.
2. Inicie sesión SSH en el host ESXi que se encuentra el disco local que hace parte de la vSAN, con el usuario root y la contraseña configurada, para ejecutar el siguiente comando que mostrará la ruta reclamada por el plugin de multipathing nativo para VMware (NMP: VMware Native Multipath Plugin) perteneciente al Pluggable Storage Architecture.
[root@esxi:~]esxcli storage nmp path list
En la imagen mostrada arriba aparecen varios identificadores sas.*, que de izquierda a derecha el primero corresponde a la dirección SAS de la controladora de discos, la segunda a la dirección SAS del disco y el ultimo el nombre canónico (naa.*) definido por vSphere para cada Storage Device.
De esta manera, si se quiere buscar cuál es la posición física correspondiente a un determinado disco local se debe buscar de manera inversa, esto es; identificar primero el nombre canónico naa.* del disco en vSphere (Paso 1) y posteriormente buscar dicho naa.* en la salida del comando anterior (Paso 2). Una vez encontrado, se debe tomar nota de su correspondiente SAS Address (segunda dirección de izquierda a derecha).
Ejemplo:
Para buscar la ubicación física del Storage Device seleccionado en la siguiente figura
Al ejecutar el comando esxcli storage nmp path list y buscar el nombre canónico en la salida de comando (naa.5002538c40896228) se obtiene lo siguiente
3. Ahora se debe buscar en cada uno de los discos locales del servidor, la dirección sas.* encerrada en color rojo o el target del dispositivo TXX encerrado en color azul, desde la interface de administración del mismo (iLO, CIMC, iDRAC, etc.). A continuación, una muestra de la coincidencia para el caso de un servidor CISCO.
En la imagen anterior se puede observar que el disco corresponde al slot 4 (PD-4), ya que al realizar la búsqueda en cada uno de los discos éste coincide tanto para la Dirección SAS como para el Target (id. del dispositivo para el caso de CISCO).
Nota: Puede haber casos en que debido al firmware sugerido por la matriz de compatibilidad de vSAN para la controladora de discos, la dirección sas.* en salida del comando del Paso 2 aparezca como desconocido (unknown) para la dirección sas de la controladora y de los discos, por lo que nos queda solo rastrear el disco en el mundo físico por su target encerrado en color azul.













































![clip_image001[11]](https://nachoaprendeit.com/wp-content/uploads/2018/07/clip_image00111.png "clip_image001[11]")





![clip_image001[5]](https://nachoaprendeit.com/wp-content/uploads/2018/07/clip_image0015.png "clip_image001[5]")




