CONTENIDO
- Que es el NAPP
- Despliegue de NAPP
- El problema: Versión TKR fuera de soporte
- Análisis de Compatibilidad
- Solución
- Notas importantes
- Screenshots de referencia para los actualizaciones (saltos) adicionales.
- Actualizar Kubernetes Tools
Este post está dirigido para quienes tienen la necesidad de actualizar la versión del clúster de Kubernetes que soporta la solución NSX Application Platform (NAPP). La cual debe estar siempre alineada con la matriz de interoperabilidad de VMware. El proceso que vamos a describir a continuación también debe ser realizado cuando vayamos a realizar una actualización de NSX (que utilice NAPP), vCenter (con vSphere with Tanzu) o VCF (con Workload Management habilitado) para evitar romper la integración con los clústeres de Kubernetes (K8s).
Que es el NAPP
NSX Application Platform (NAPP) es una plataforma basa en microservicios que aloja varias funciones de NSX que recopilan, incorporan y correlacionan información de tráfico de red. A medida que se generan, capturan y analizan los datos en su entorno NSX, NSX Application Platform proporciona una plataforma que puede escalar dinámicamente en función de las necesidades de su entorno.
La plataforma puede alojar las siguientes funciones de NSX que recopilan y analizan los datos en su entorno NSX-T.
- VMware NSX® Intelligence™
- VMware NSX® Network Detection and Response™
- VMware NSX® Malware Prevention
- VMware NSX® Metrics
Para mayor información, podemos consultar la documentación oficial NSX Application Platform Overview.
Despliegue de NAPP
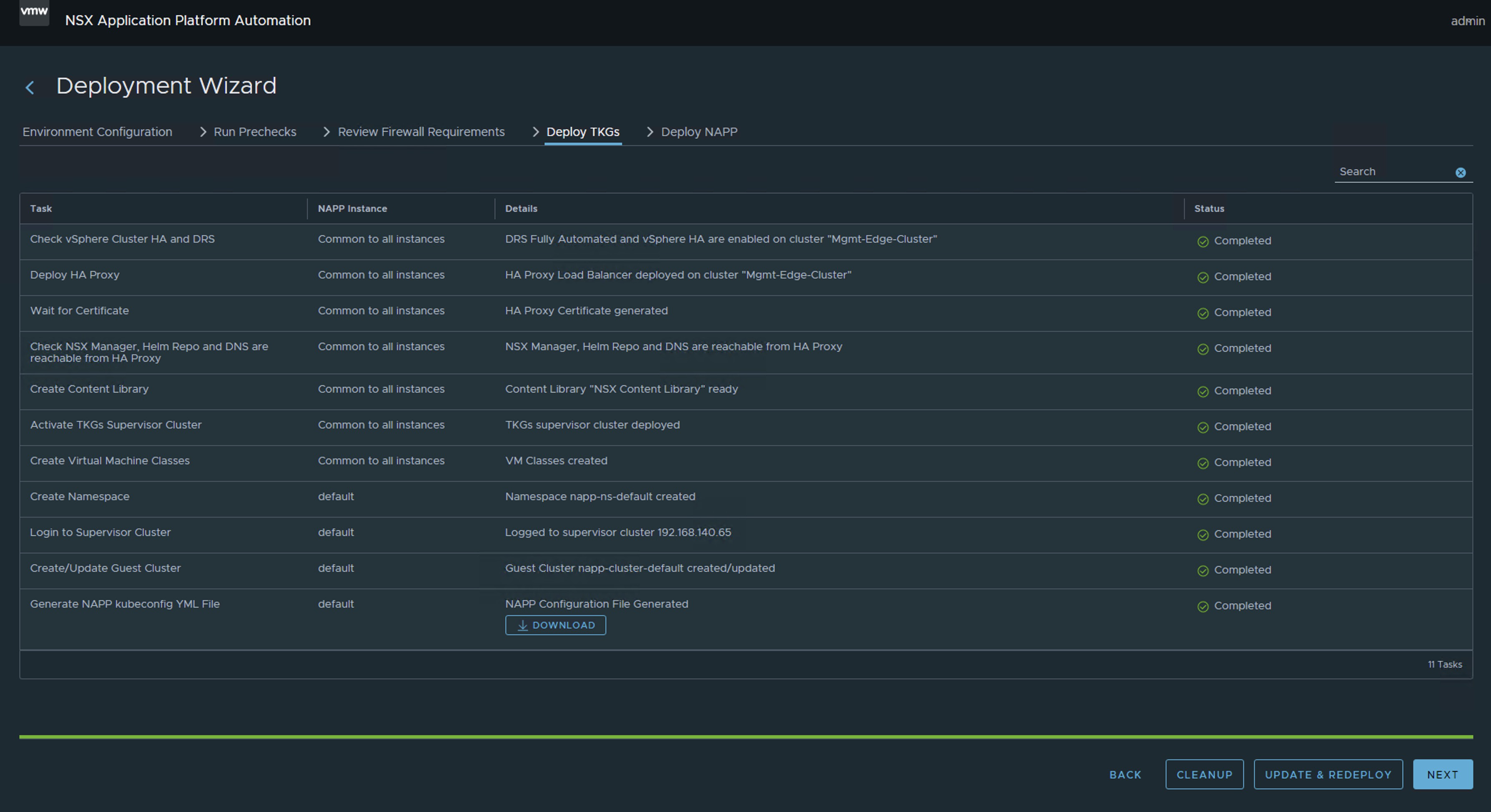
Para quienes no tienen claro qué conforma un despliegue de NAPP (NSX Application Platform), podemos dejar una imagen que resume los componentes del despliegue. Donde el componente principal para soportar la solución de NAPP, es la solución de vSphere with Tanzu.

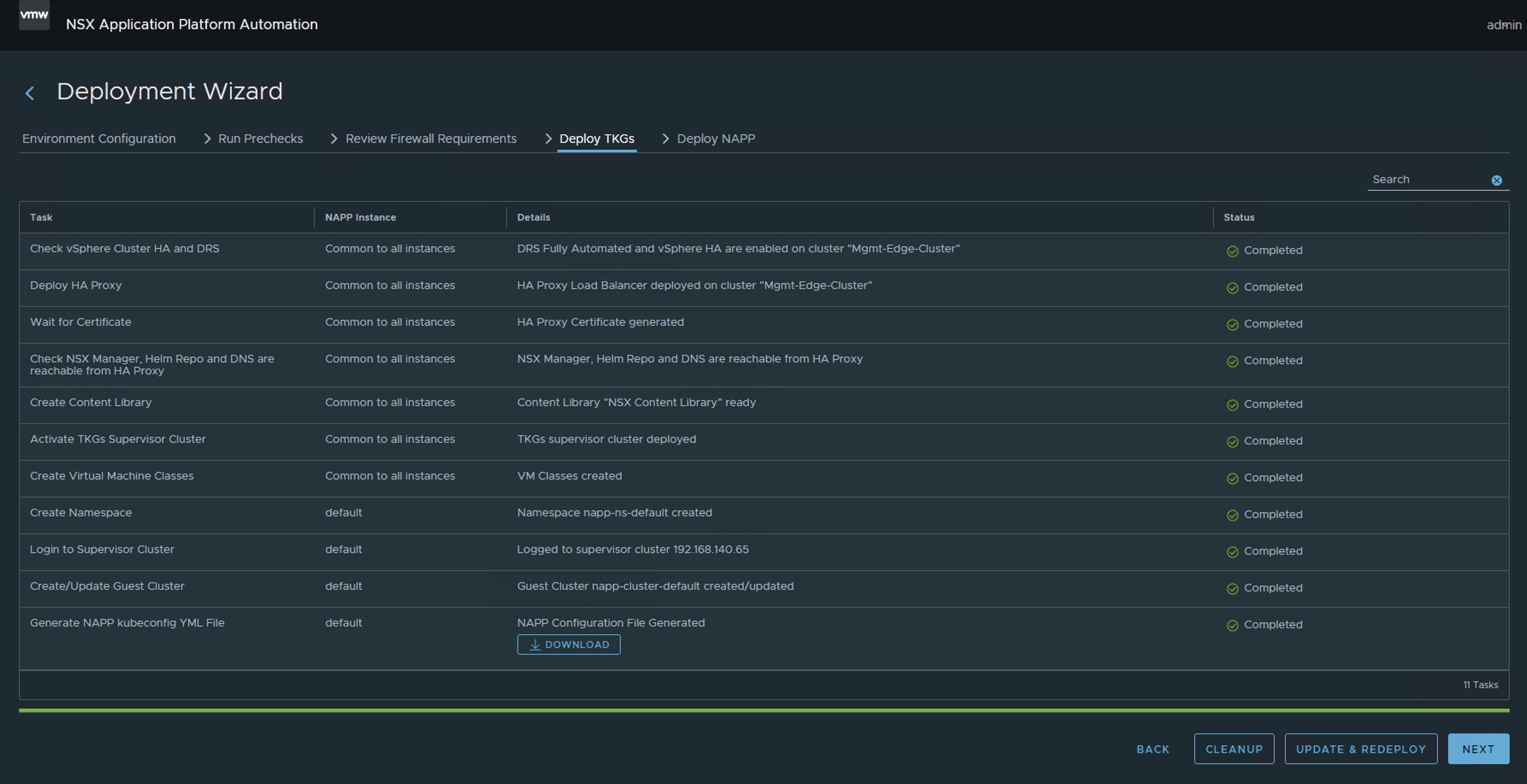
Sé que la imagen anterior puede causar terror. Sin embargo, el equipo de ingeniería de VMware By Broadcom ha desarrollado una herramienta llamada NAPPA (NSX Application Platform Automation Appliance) con el fin de facilitar la implementación de cada uno de los componentes que conforman toda la infraestructura de Kubernetes requerida para soportar la solución de NAPP (NSX Application Platform).
De esta manera NAPPA ejecuta flujos de manera automática para, configurar vSphere with Tanzu, que es una solución que nos permite la ejecución de clústeres de K8s directamente sobre el Hipervisor a través de la creación de vSphere Namespaces. De igual manera NAPPA, usando el Supervisor Clúster desplegado con vSphere with Tanzu, crea automáticamente un vSphere namespace, donde se crea un Tanzu Kubernetes Clúster, al cual llamaremos Guest Cluster de ahora en adelante, y es donde la solución de NSX Application Platform toma vida, así como también todos los pods asociados a los servicios de Metric, VMware NSX® Intelligence™, VMware NSX® Network Detection and Response™, VMware NSX® Malware Prevention y VMware NSX® Metrics.
Para no hacer más largo el cuento lo vamos a dejar hasta ahí.
El problema: Versión TKR fuera de soporte
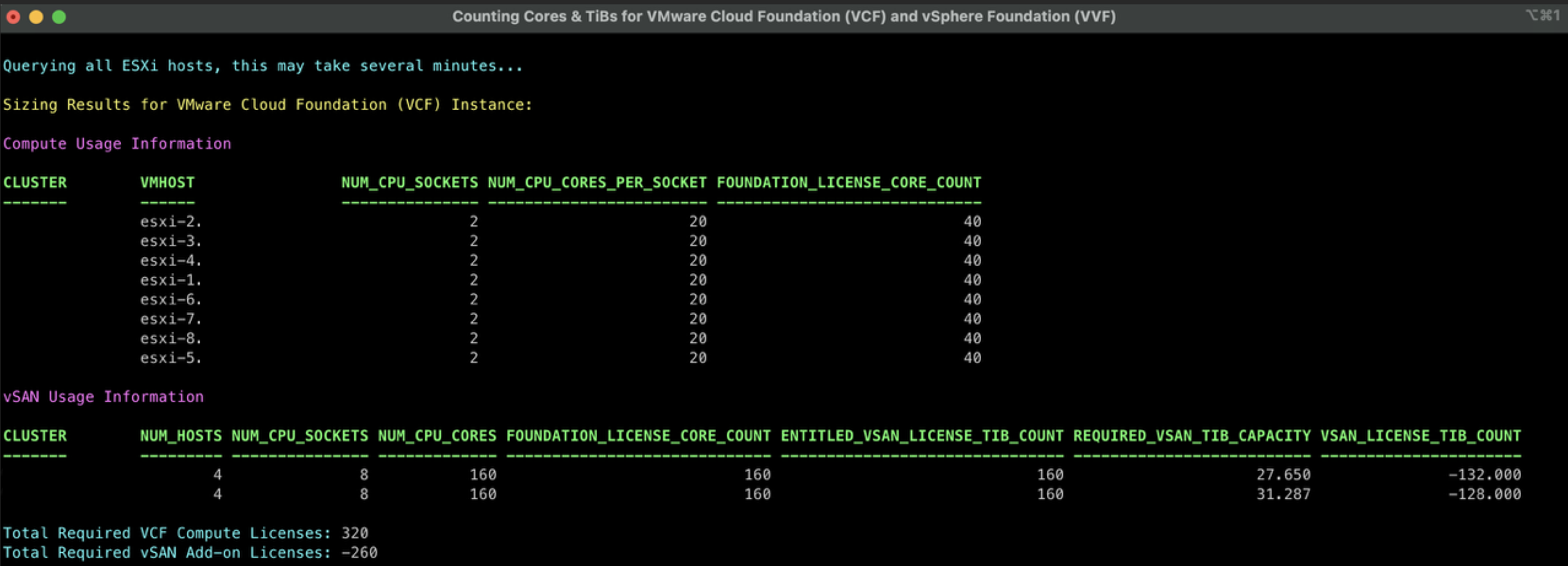
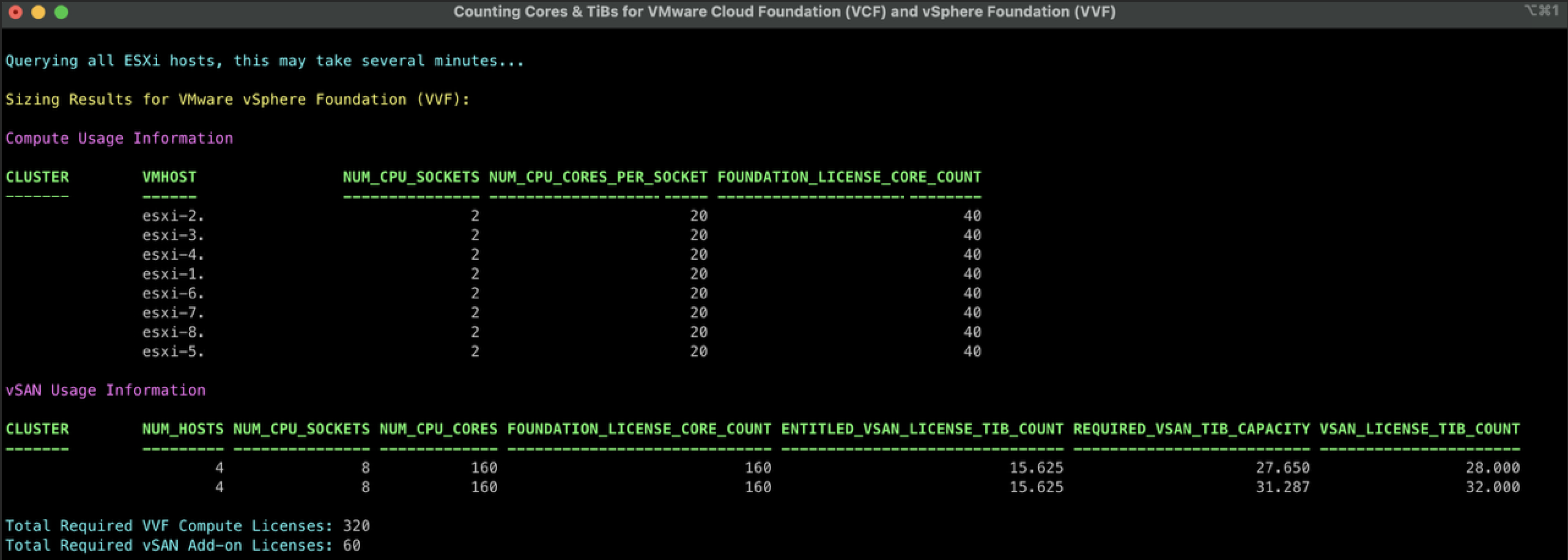
Ahora bien, el problema que vamos a solucionar acá es cómo mantener este Guest Cluster después de haberlo implementado con el NAPPA. Debido a que en muchas ocasiones, dependiendo de la versión del NSX que teníamos al momento de desplegar el NAPP (NSX Application Platform), la versión de dicho cluster puede quedarse en una versión fuera de soporte que puede generar problemas a medida que vamos actualizando nuestro ambiente de vSphere y de NSX.
Para efectos de laboratorio, hemos desplegado la versión más reciente de NAPP 4.2.0 y curiosamente el guest cluster se ha implementado usando la versión de TKR 1.23.8+vmware.3-tkg.1, que a la fecha está fuera de soporte. Este comportamiento es un issue conocido, para la herramienta de NAPPA y para evitar este comportamiento te invito a leer el siguiente post Desplegar NAPP con version de TKR soportado

Análisis de Compatibilidad
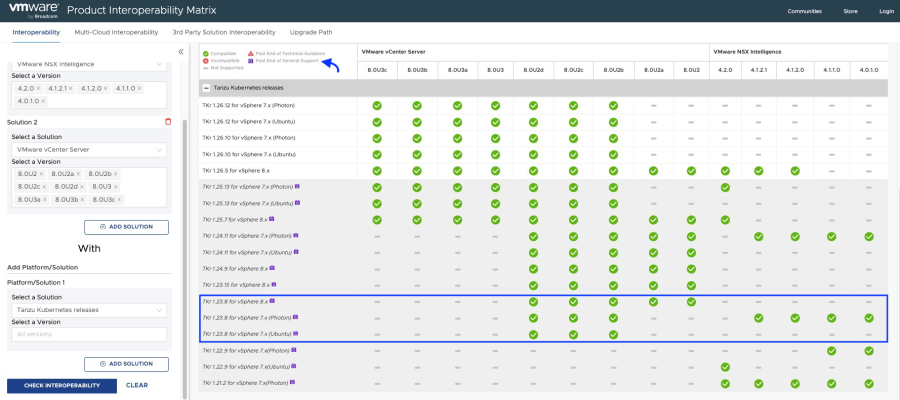
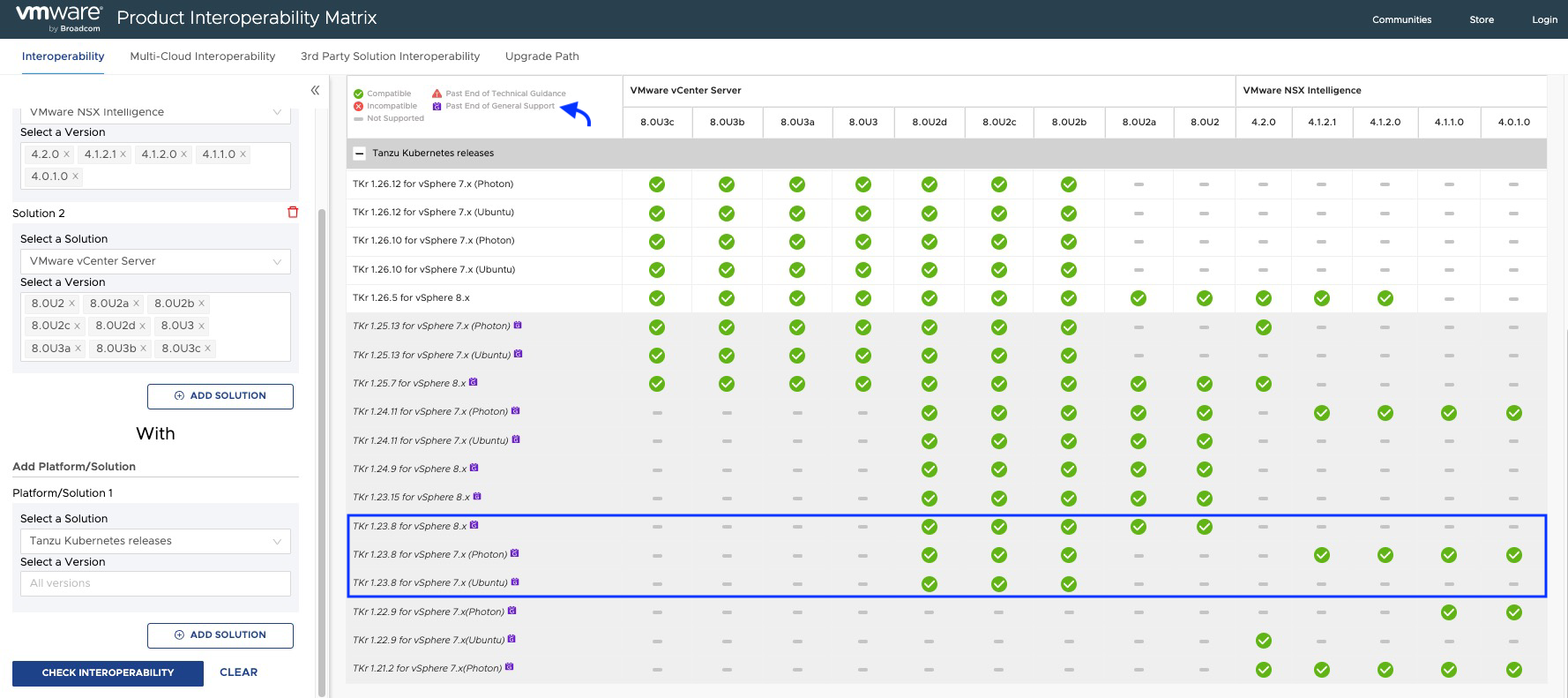
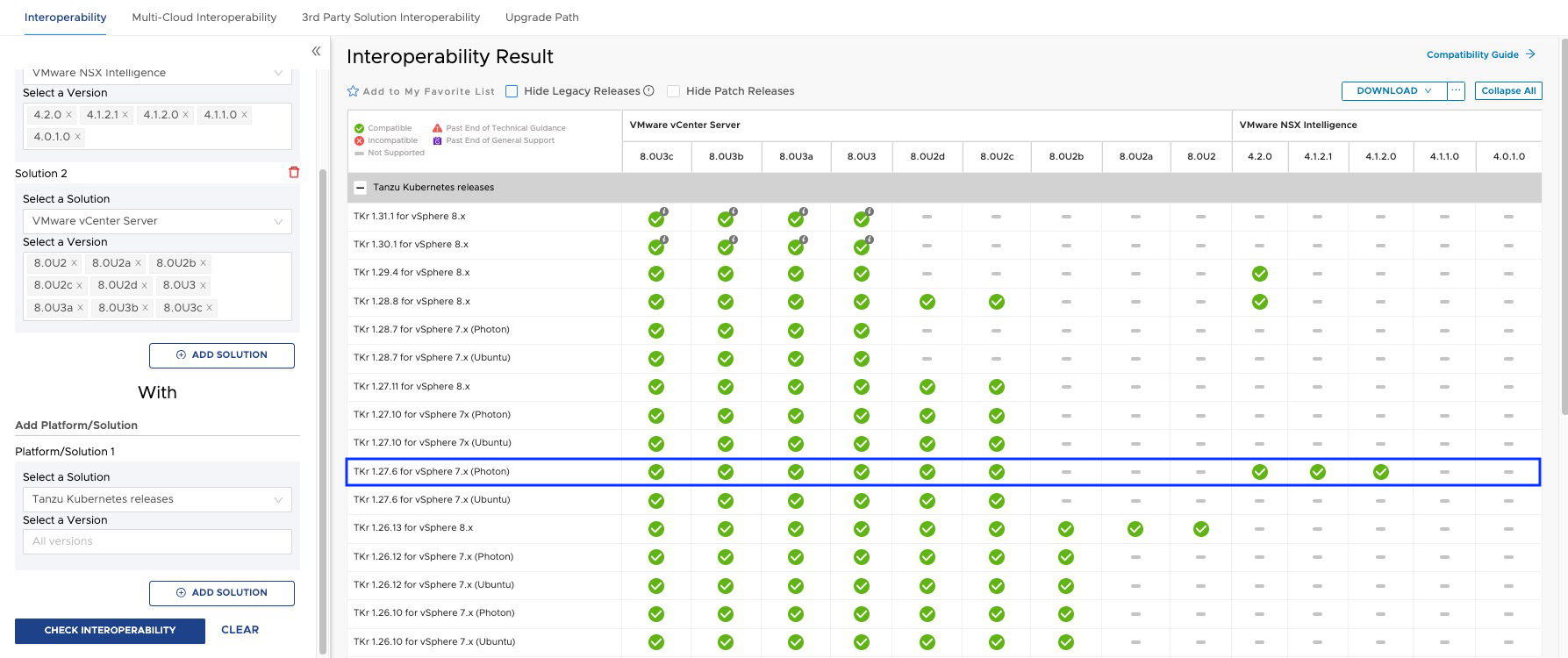
De acuerdo con la matriz de interoperabilidad deberíamos cumplir con las siguientes versiones mínimas de TKR.

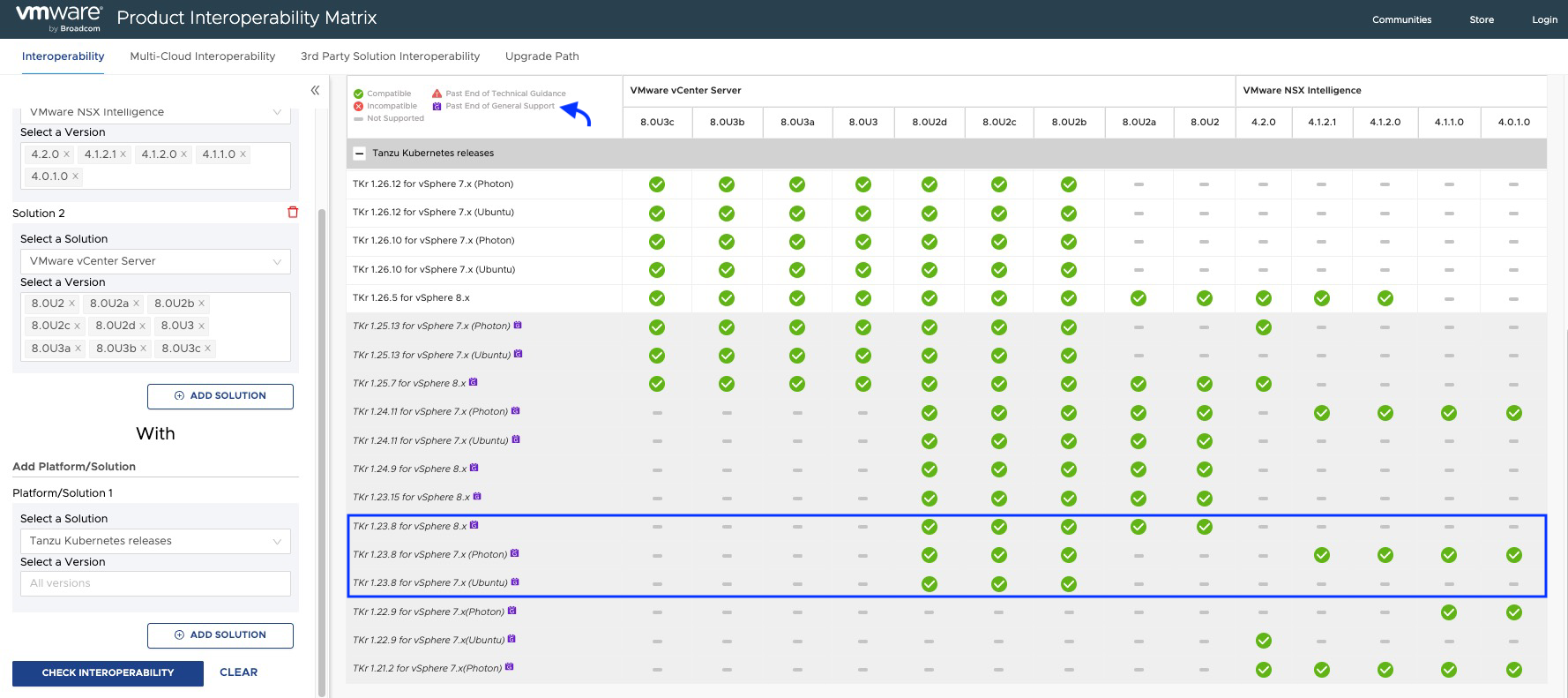
Como podemos apreciar en la matriz de interoperabilidad, las versiones de TKR por debajo de 1.26.5 usadas por el guest cluster de NAPP, están actualmente fuera de soporte e incluso algunas de ellas podrían no ser compatible con tu NSX Intelligence o con tu vCenter Server.
Nota: El procedimiento explicado a continuación debe realizarse cuando hagamos una actualización de NSX o vCenter Server ya sea como consecuencia de una actualización de VMware Cloud Foundation (VCF) o cuando actualizamos estas soluciones de manera independiente, con el fin de mantener el clúster de NAPP compatible y dentro del soporte de VMware by Broadcom.
¡Sin más preámbulo vamos al Lab!
Solución
Lo primero que vamos a hacer es seguir la documentación Update a TKG Cluster by Editing the TKR Version, pero no te preocupes acá vamos a explicarlo paso a paso.
Nota: Debemos tener presente que la versión de TKR solo se puede subir de manera gradual, n + 1, es decir que si tenemos la versión 1.23, el primer salto debe ser a la 1.24 y así sucesivamente hasta alcanzar la versión requerida.
Iniciar sesión en el NAPPA vía SSH, con el usuario
rootya que desde ahi podremos conectarnos al supervisor cluster sin necesidad de instalar ningún plugin en nuestra VM y vamos a ejecutar el siguiente comando.
Ejecutar el siguiente comando para iniciar conexión al Supervisor cluster. Sino sabes cuál es la IP del Supervisor Cluster solo ve al vCenter Server > Menu > Workload Management > Namespaces > Supervisor Cluster

kubectl vsphere login --insecure-skip-tls-verify --server [IP_SupervisorCluster] --vsphere-username administrator@vsphere.local)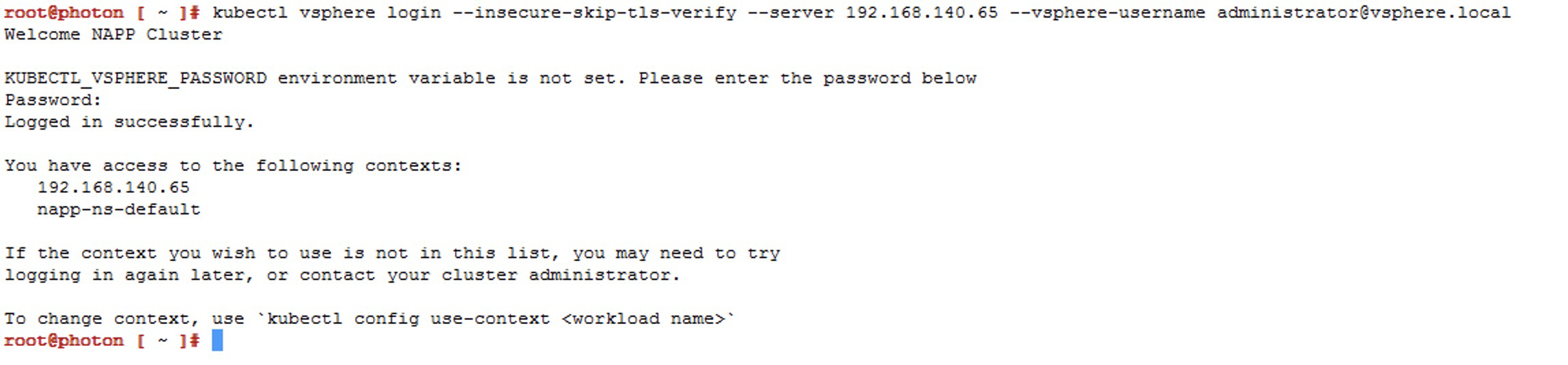 Ahora vamos a elegir el contexto que tiene nuestro despliegue de napp, que debería ser
Ahora vamos a elegir el contexto que tiene nuestro despliegue de napp, que debería ser napp-ns-defaulty para ello usamos el siguiente comandokubectl config use-context [context_name]
Vamos a validar las versiones compatibles de TKR disponibles en la Libreria de contenido unida a dicho namespace, con el siguiente comando
Nota: Durante el despliegue, NAPPA configura una librería de contenidos llamada NSX Content Library en el vCenter, con esas tres imágenes. Sin embargo, no podemos hacer el salto desde lakubectl get tkr
Acá podemos apreciar que el NAPPA ha publicado en la librería de contenido tres imágenes, entre ellas la imagen de1.27.6+vmware.1-fips.1-tkg.1que es superior y compatible. Pero en el momento del despliegue ha usado la1.23.8+vmware.3-tkg.1, lo cual es una pena porque ahora nos toca subir el Guest Cluster hasta llegar a esa version o una superior compatible de acuerdo con la matriz de interoperabilidad.v1.23.xhacia lav1.27.xcomo ya lo mencionamos antes, así que tendremos que cargar las imágenes a dicha librería.
Para descargar y subir a la librería de contenidos las imágenes que nos faltan debemos ir a la siguiente URL https://wp-content.vmware.com/v2/latest/lib.json o también podríamos crear una nueva Content Library Subsribed con la siguiente URL
https://wp-content.vmware.com/v2/latest/lib.jsony conectar el namespace con esa librería.
En este caso vamos a usar la primera opción y nuestro primer salto será hacia la versiónv1.24.x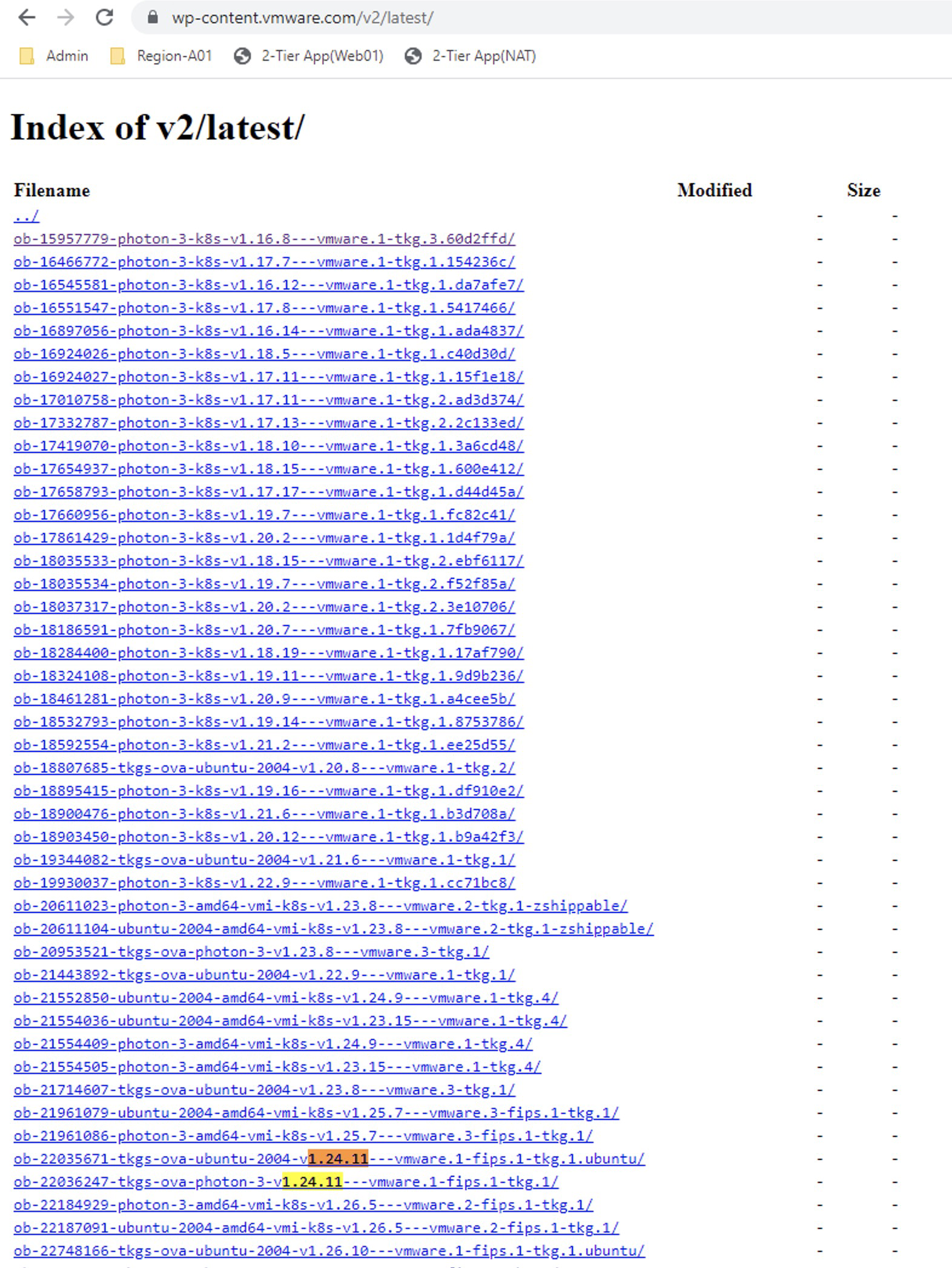
En el repositorio vemos dos imágenes pero vamos a seleccionar la que se llamaob-22036247-tkgs-ova-photon-3-v1.24.11---vmware.1-fips.1-tkg.1y que por supuesto sea compatible, de acuerdo con la matriz de interoperabilidad.Así que hacemos clic en ella y luego sobrephoton-ova.ovfclic derecho para copiar el link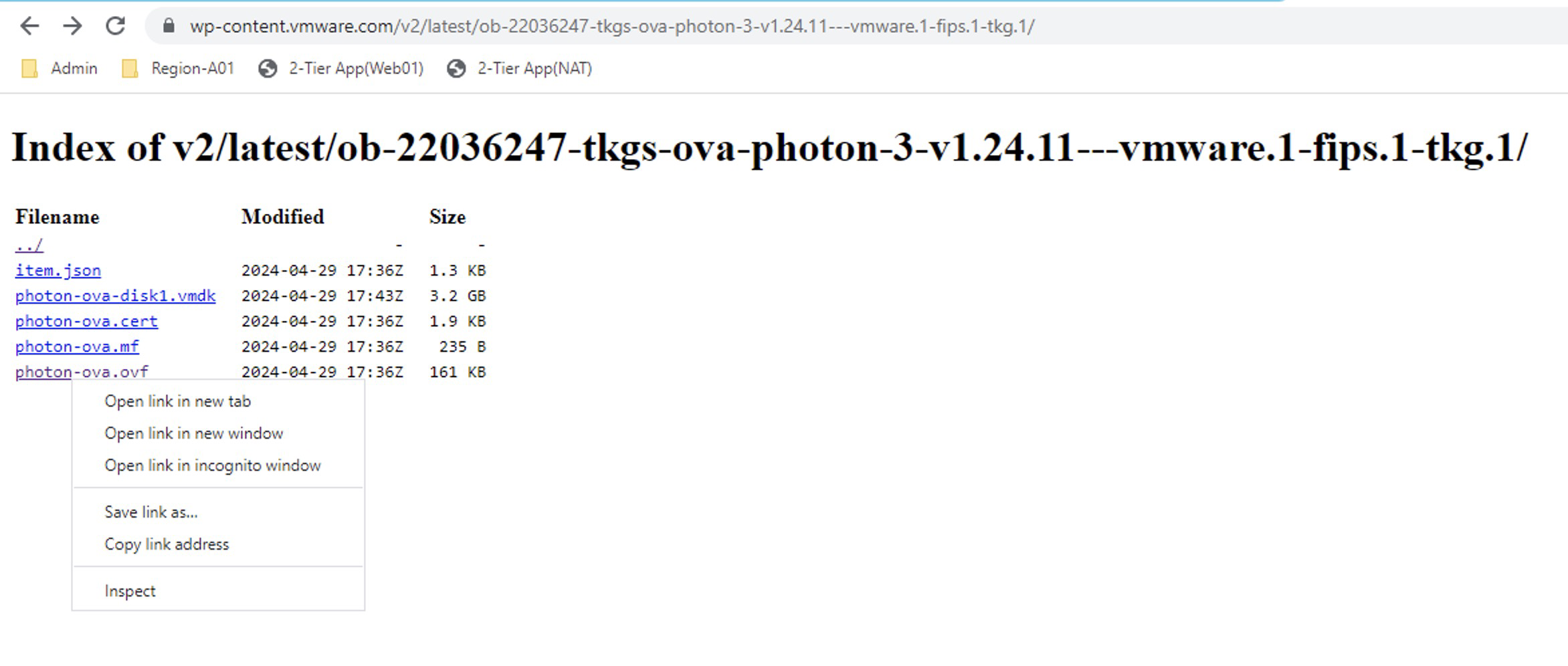
Vamos ahora a la librería de contenidos NSX Content Library > Actions > Import Library Item y seleccionamos la opción URL, donde vamos a pegar el link copiado anteriormente.

Nota: En el item name, recomiendo colocarle el mismo nombre que tiene en el portal de descarga para que sea fácil identificarla.
Clic en IMPORTAR y esperamos que se descargue Repetir los pasos para las siguientes imágenes que seran los saltos graduales:
Repetir los pasos para las siguientes imágenes que seran los saltos graduales:ob-22757567-tkgs-ova-photon-3-v1.25.13---vmware.1-fips.1-tkg.1
ob-23319040-tkgs-ova-photon-3-v1.26.12---vmware.2-fips.1-tkg.2
ob-23049612-tkgs-ova-photon-3-v1.27.6---vmware.1-fips.1-tkg.1
ob-24026550-tkgs-ova-photon-5-v1.28.7---vmware.1-fips.1-tkg.1La Content Library debería verse de la siguiente forma. Recordemos que las imágenes que hemos seleccionado han sido selecionadas teniendo en cuenta la matriz de interoperabilidad entre NSX intelligence y Tanzu Kubernetes Releases.
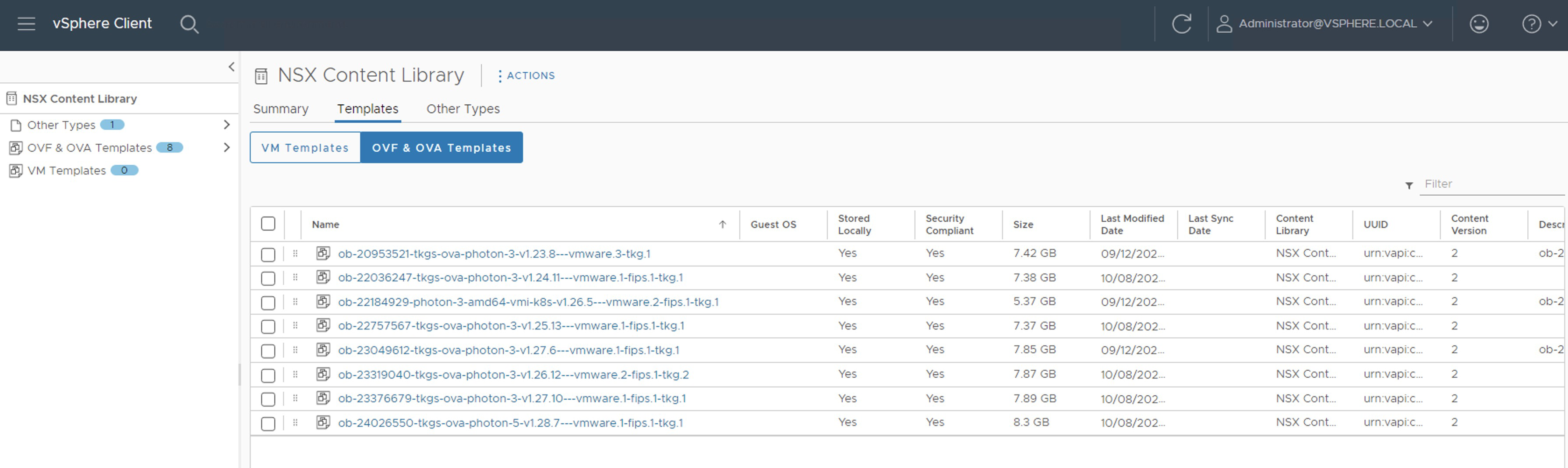 Ahora si lanzamos nuevamente el comando
Ahora si lanzamos nuevamente el comando kubectl get tkr, las imágenes que hemos cargado deberían mostrarse contrueen la columnaREADYyCOMPATIBLE. OJO! No deberíamos aplicar ninguna imagen que no cumpla con estas condiciones.
Ahora lanzamos el siguiente comando para ver la siguiende versión disponible del cluster de kubernetes y el nombre del Guest Cluster que vamos a intervenir.
kubectl get tanzukubernetescluster
Listamos los Tanzu Kubernetes releases
kubectl get tanzukubernetesreleases
Ejecutamos el siguiente comando para editar el manifest de Guest Cluster
kubectl edit tanzukubernetescluster/CLUSTER-NAME
Aqui vamos a editar unicamente las lineas de las referencias para elcontrolplaneynodePoolsque aparecen dentro del objetotopology
Verifique en la salida del comando
kubectlindique que la edición del manifiesto se realizó correctamente
Verifique con el siguiente comando que el Guest Cluster se este actualizando
kubectl get tanzukubernetescluster
Nota: En la salida del comando vemos que la columnaREADYdiceFalsedebemos esperar a que aparezcaTrue. La paciencia es la clave, esto puede tomar hasta 30 min.Una vez actualizada debería verse de la siguiente forma

Repetimos los pasos 8 a 11 hasta llegar a la versión de destino. Por ejemplo nuestro siguiente salto sera ala version
v1.25.13---vmware.1-fips.1-tkg.1y asi susesicamente. Sin embargo, antes de hacerlo lee las siguientes notas importantes.Al finalizar deberíamos ver la versión de distribución de la siguiente manera

Notas importantes
Nota 1: Podemos monitorear el proceso desde napp-ns-default > Monitor
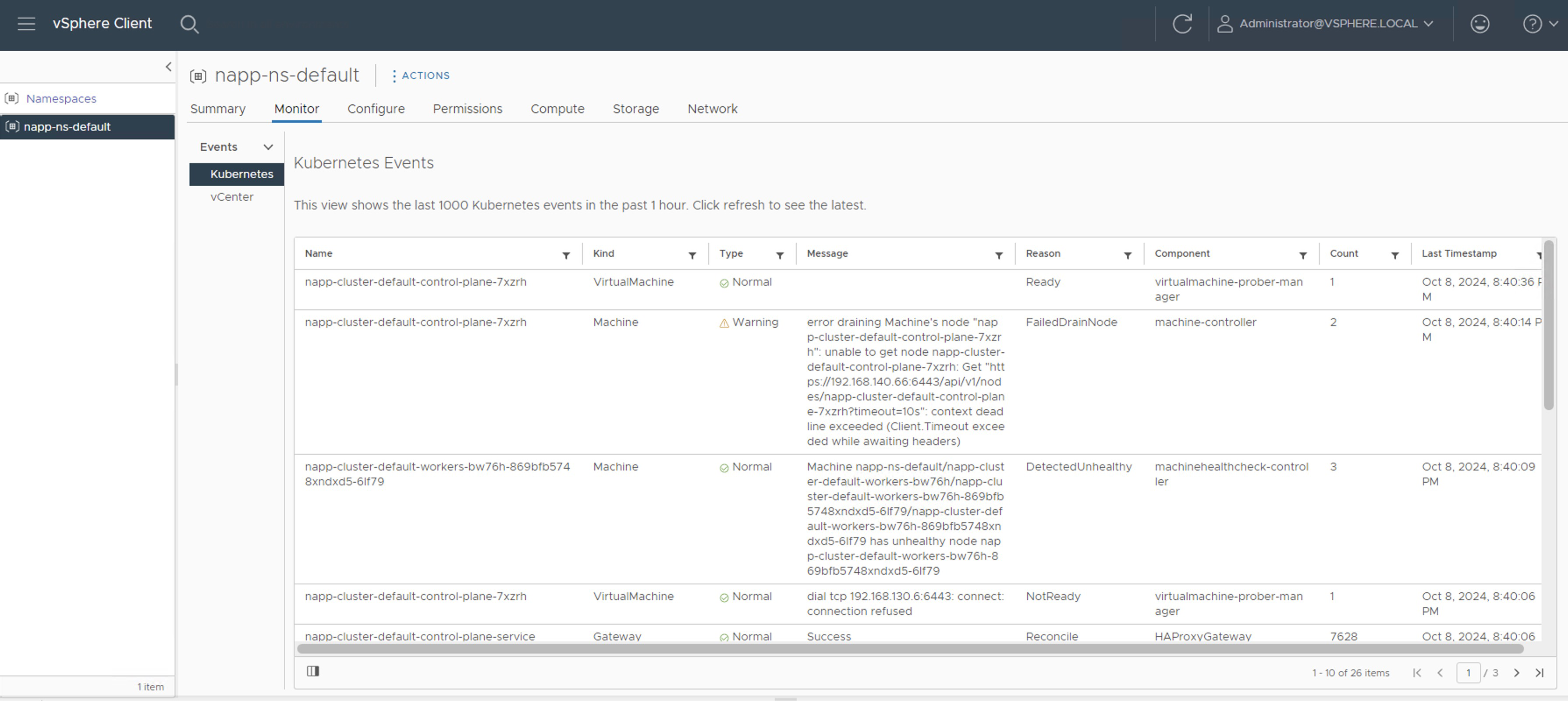
O en napp-ns-default > Compute debemos esperar hasta que la columna Phase pase de Updating a Running. Sin embargo, cuando aparece Running no indica que ya ha terminado. Aún podemos ver eventos y tareas corriendo en el inventario.

Nota 2: Durante cada salto de actualización veremos como se crean nodos adicional mientras ocurre el proceso. La actualización comienza por los nodos del Control Plane y despues en los nodos Worker. Es importante que antes de iniciar con el siguiente salto, verifiquemos no se encuentren tareas en ejecución, que la cantidad de nodos en el inventarios sea la correcta, en mi caso del LAB debería tener únicamente un Control Plane node y un Worker Node. En el siguiente pantallazo vemos un nodo de más, es decir que aún no ha terminado.

Una vez terminan todas las actividades, vamos a ver que el numero de nodos para el Guest Cluster en el inventario es el correcto. Sin embargo, aún debemos esperar que la solucion del NAPP se estabilice.

Nota 3: Debemos esperar que la solución de NSX Application Platform se muestre estable desde la consola de NSX. Esto puede tardar algunos minutos.


Nota 4: Si utilizamos la opción de Troubleshooting del NAPPA (NSX Application Platform Automation Appliance), podemos ver el momento en el que todos los Pods estén arriba.

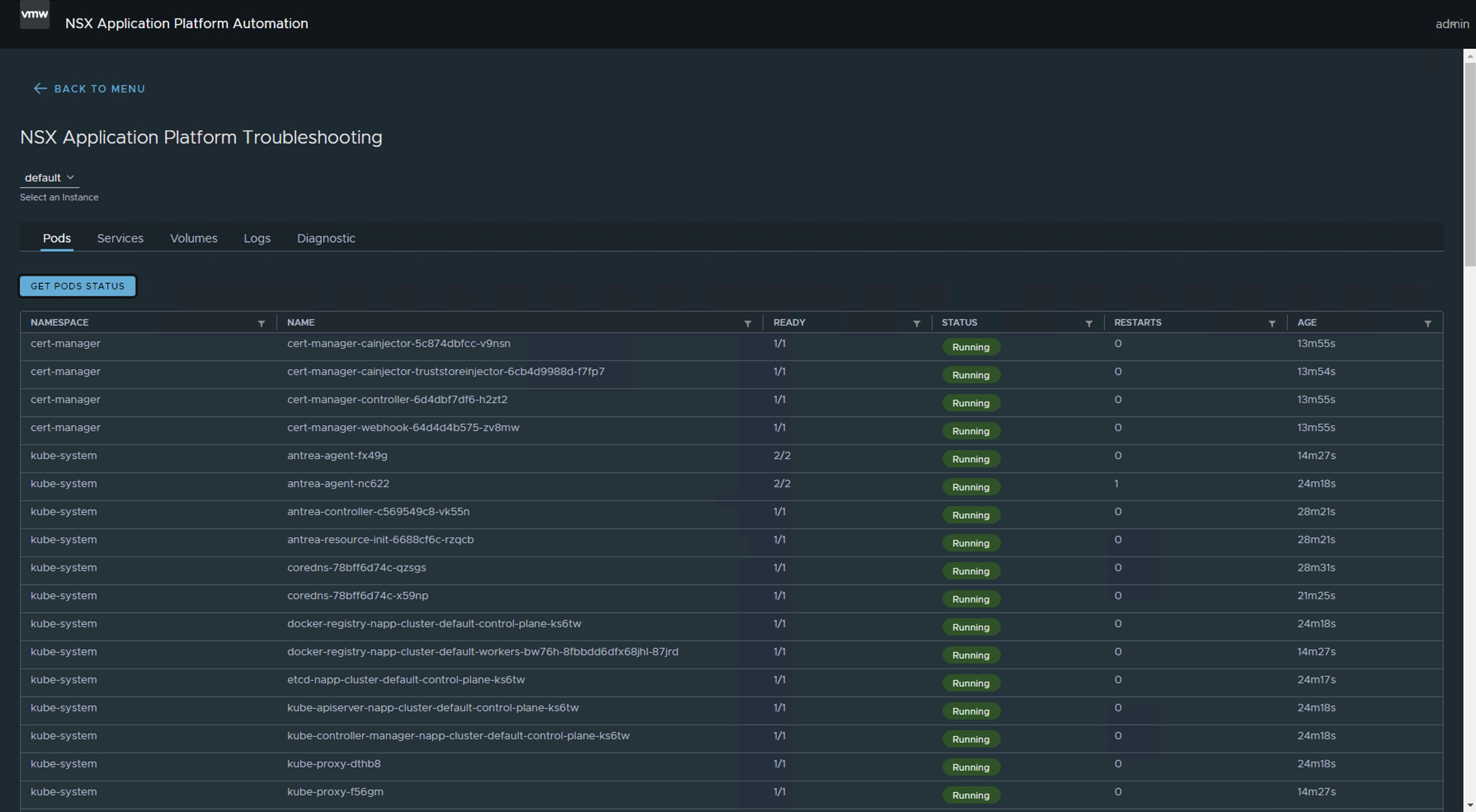
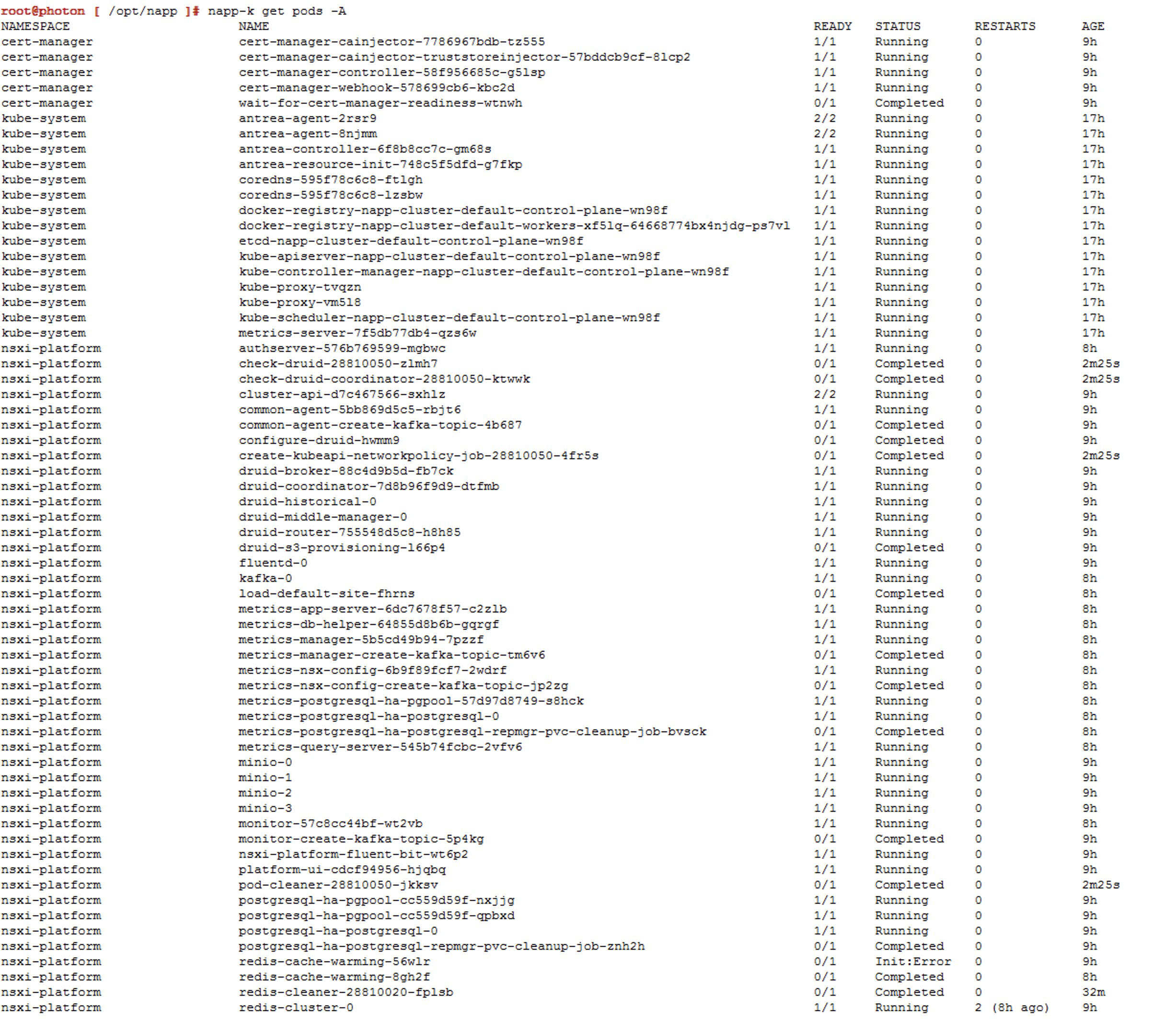
o podemos usar el comando napp-k get pods -A
Screenshots de referencia para los actualizaciones (saltos) adicionales.
Salto a v1.25.13---vmware.1-fips.1-tkg.1



Salto a v1.26.12---vmware.2-fips.1-tkg.2
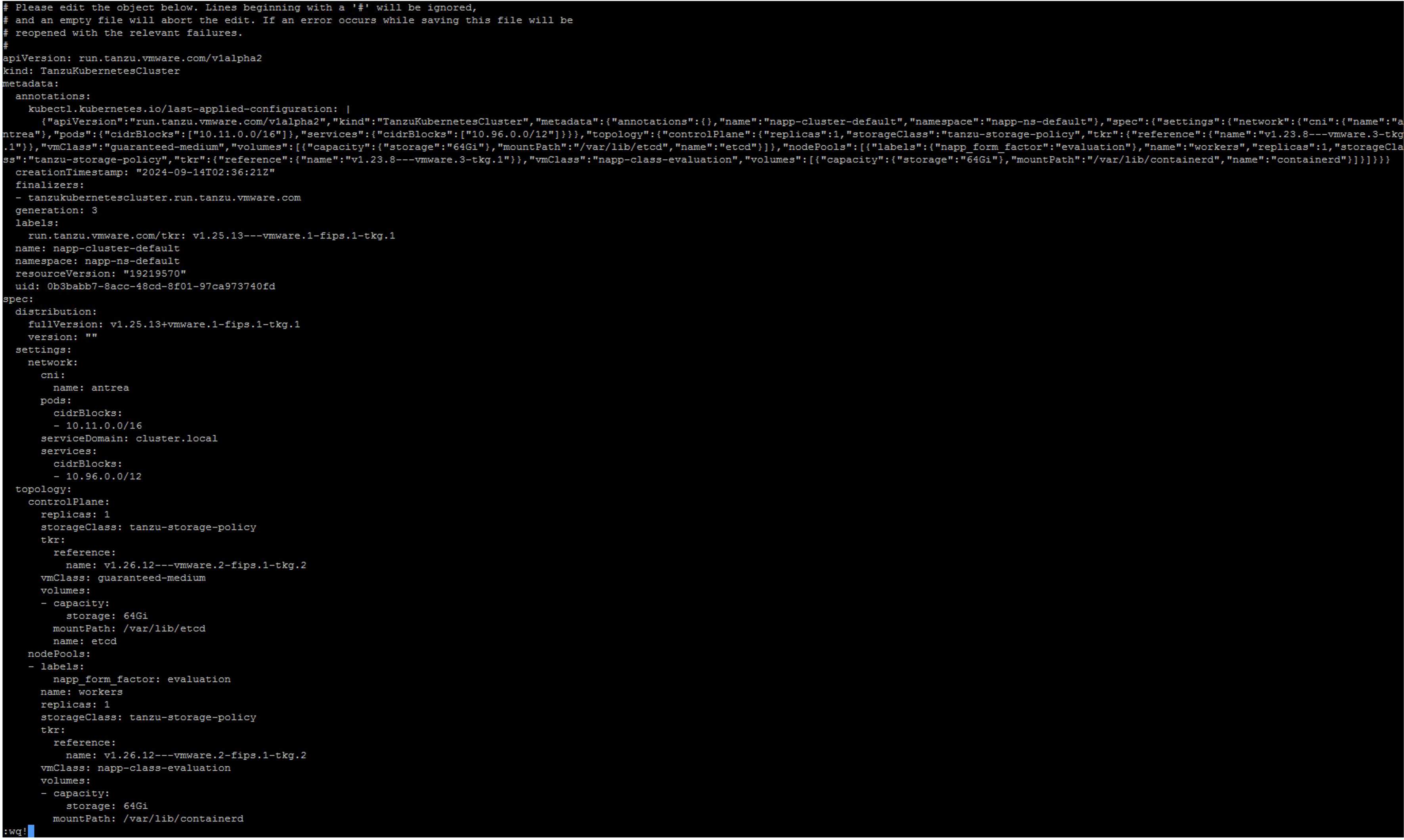


Salto a v1.27.10---vmware.1-fips.1-tkg.1

Actualizar Kubernetes Tools
Una vez hemos terminado con las actualizaciones y nos encontremos ahora en una versión compatible de acuerdo con la matriz de interoperabilidad de NSX Intelligence. Es probable que vea la siguiente alerta en la interface. Si estas en una version superior a NSX 4.1.2.2 seguramente no te va a salir esta alerta.
Server version v1.27.10+vmware.1-fips.1 and client version v1.23.3 are incompatible. Please upload Kubernetes Tools to resolve.
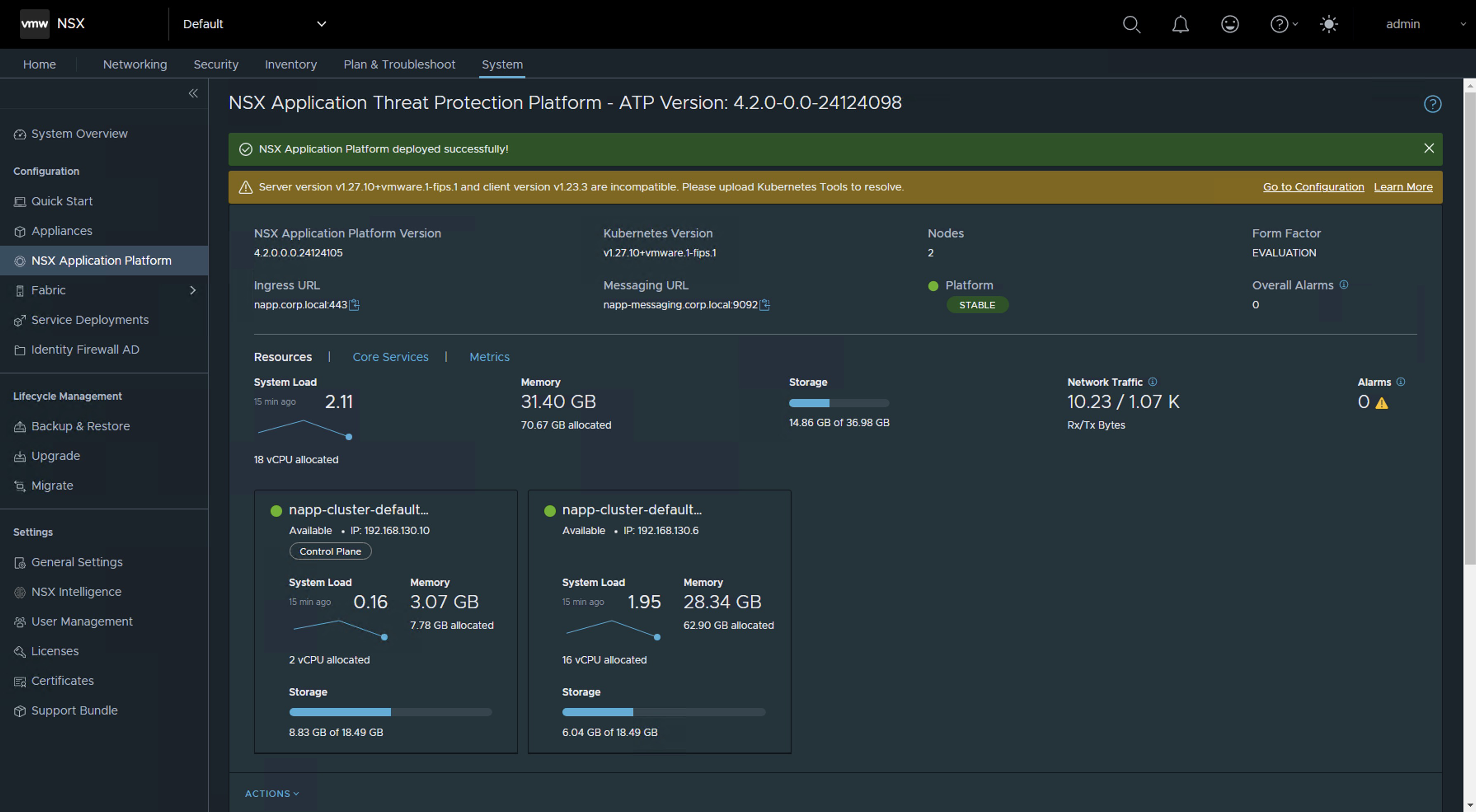
Para solucionar dicha alerta solo sigue el siguiente KB NAPP pane in NSX UI shows message "Server version <version> and client version <version> are incompatible. Please upload Kubernetes Tools to resolve.
¡Y eso es todo amigos! Con este procedimiento vas a poder darle mantenimiento al cluster de Kubernetes (K8s) desplegado como parte de la solución NSX Application Platform (NAPP).
¡IMPORTANTE! He migrado blog del dominio nachoaprendevirtualizacion.com a nachoaprendeit.com. Si te ha servido este artículo deja tu buen Like y compártelo con tus colegas, estas aciones me ayudarán a optimizar los motores de búsqueda para llegar a más personas.

TODOS LOS NOMBRES DE VMS USADOS EN ESTE BLOG SON INVENTADOS Y OBEDECEN A UN AMBIENTE DE LABORATORIO PROPIO, UTILIZADO PARA FINES DE ESTUDIO.