Si andan metidos en el mundo de la seguridad con VMware vDefend (lo que muchos seguimos llamando con cariño NSX Security), sabrán que implementar un IDPS Distribuido (D-IDPS) no es solo hacer «Next, Next, Finish». Es una bestia potente que vive en el hipervisor, y si no se configura con cabeza, podemos degradar el rendimiento de nuestros hosts ESXi.
Recientemente me puse a analizar documentación sobre este tema y aquí les traigo el resumen «masticadito» con las Best Practices que necesitan saber para desplegar esto en producción sin morir en el intento.
Así que si tienes que asegurar el tráfico East-West, toma nota.
CONTENIDO
- Antes de comenzar
- Casos de Uso: ¿Para qué activamos esto?
- Arquitectura: ¿Qué pasa realmente con el paquete?
- Sizing: Las «Reglas de Oro» de Recursos por Host
- Estrategias de Despliegue
- Optimización del IDPS
- Day 2: Operaciones y Troubleshooting
- Day 2: Firmas y Ciclo de Vida
- Testear el funcionamiento del IDPS
- Conclusión
1. Antes de comenzar
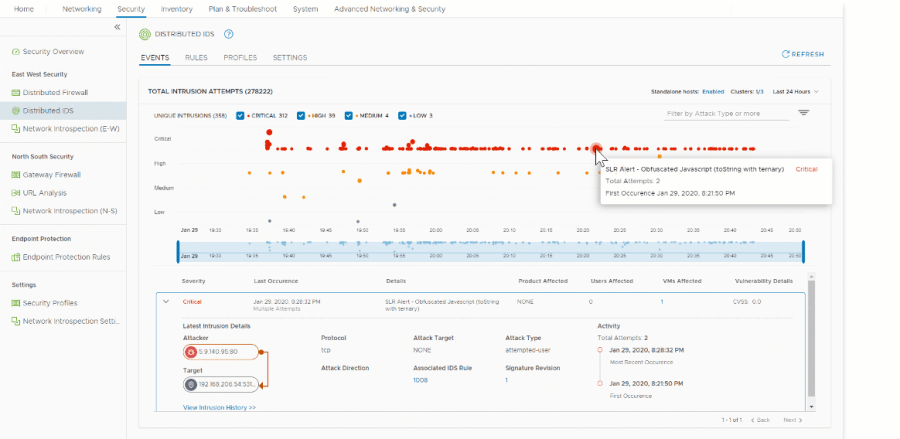
Antes de tocar cualquier configuración, necesitas visibilidad. No vueles a ciegas. Para obtener el máximo beneficio de la solución, se recomienda entender detalladamente las siguientes métricas para cada clúster antes de habilitar el IDPS.
Métricas de Infraestructura y Red:
- CPU Usage per host: Vital, recuerda que necesitas cores libres.
- Memory Usage per host: Crítico por la reserva de RAM.
- Packets per second (PPS): La métrica reina (el límite ronda los 150K).
- Total Connections & CPS: Volumen y tasa de conexiones .
- Throughput & Packet Sizes: Ancho de banda y tamaño de paquete.
- Logging Rates: Fundamental para no saturar tu SIEM si estas exportando hacia allá.
Datos Clave para el Despliegue: Adicionalmente, ten clara esta data antes de desplegar :
- ¿Qué VMs y Sistemas Operativos vamos a proteger?
- ¿Qué Grupos usaremos en el campo «Apply To»?
- ¿Qué protocolos/aplicaciones están en uso?
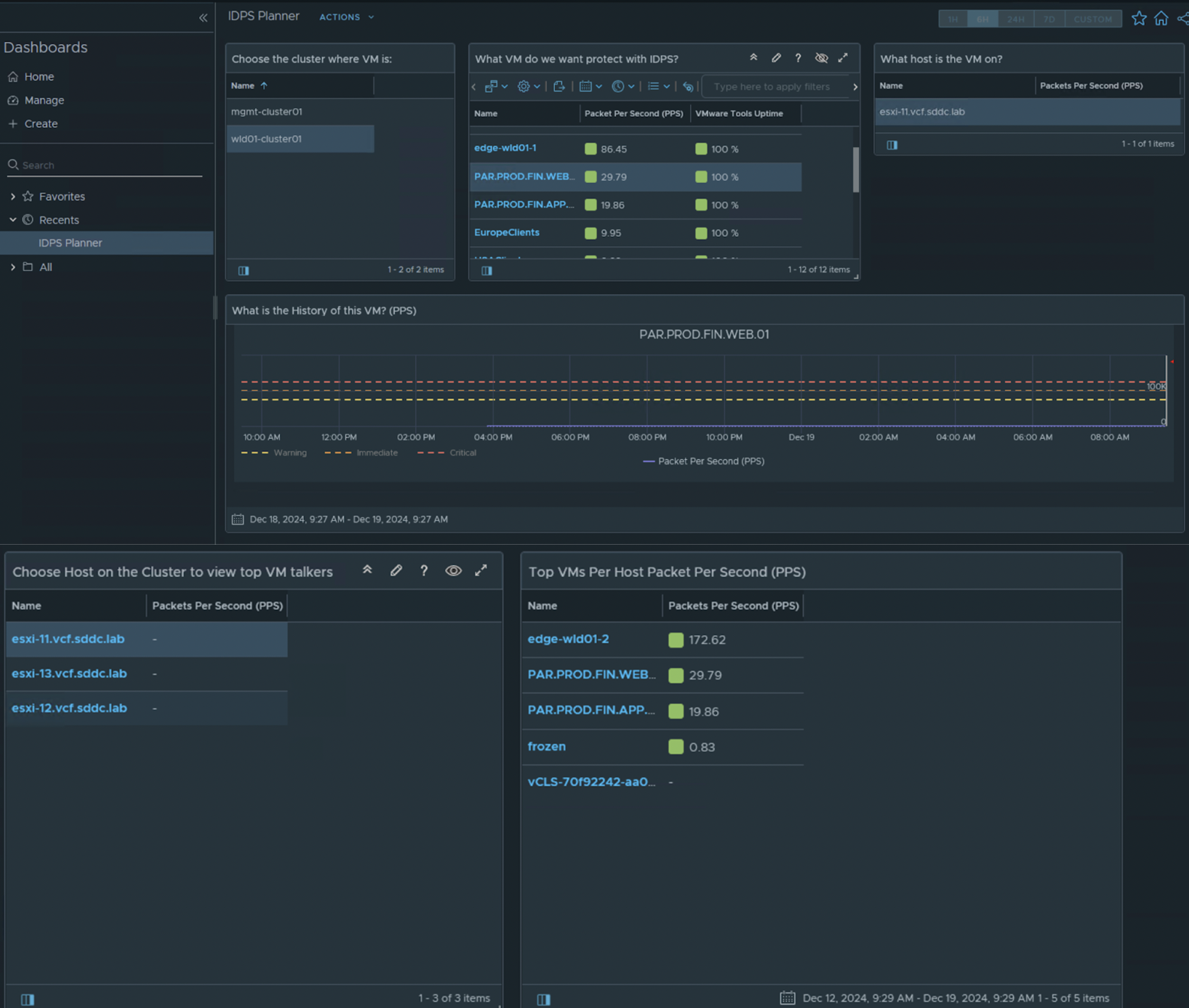
Recurso Gratuito: Utiliza el dashboard «IDPS Planner» para Aria Operations. Te da estos datos masticados.
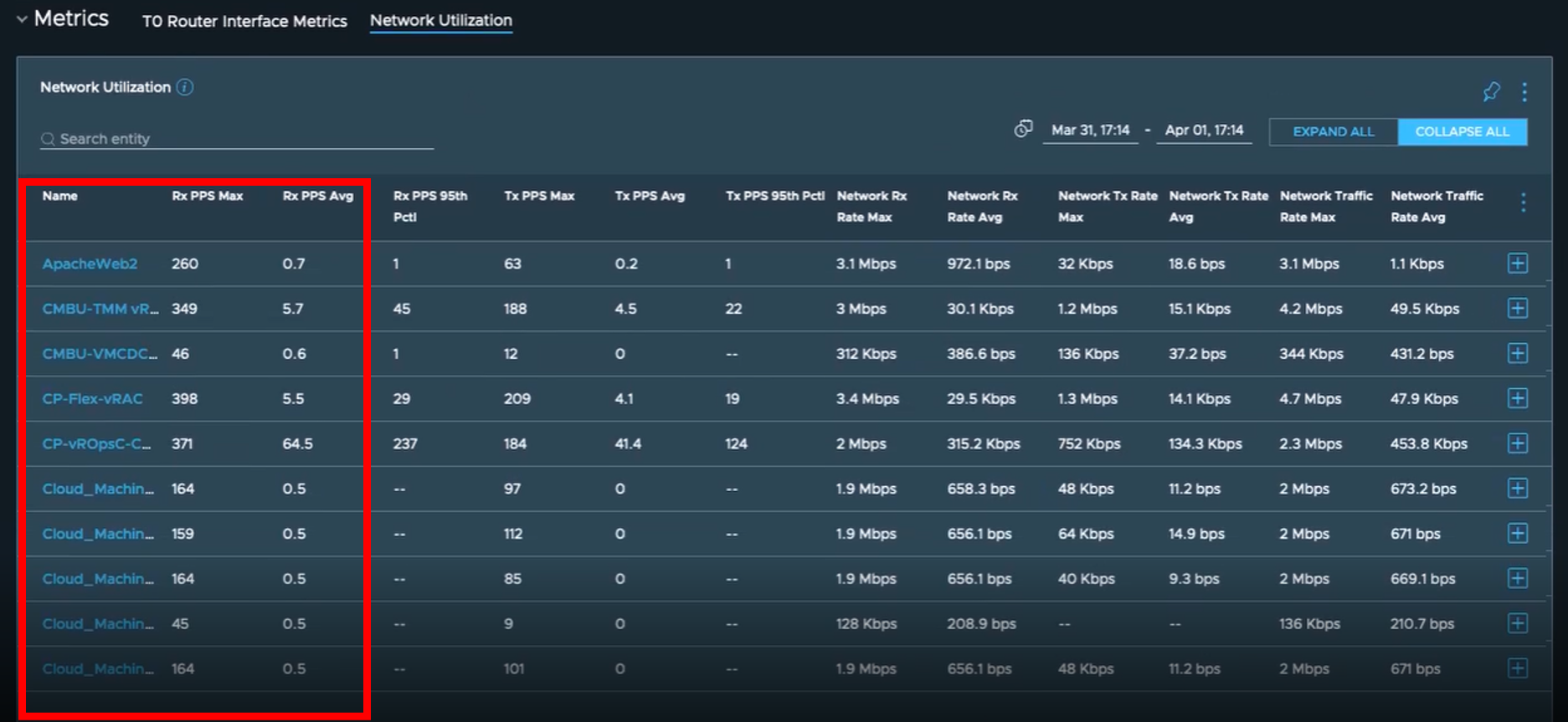
O utilizando las métricas de Aria Operations for Networks
2. Casos de Uso: ¿Para qué activamos esto?
Esta tecnología aporta valor real frente a un IDS perimetral. No lo actives «porque sí», actívalo para resolver esto:
- Visibilidad East-West (La Joya de la Corona): Los IDS tradicionales están en el borde. Una vez que el atacante entra, se mueve lateralmente ciego a tus controles . vDefend está pegado a la carga de trabajo, dándote visibilidad exacta de amenazas internas.
- Virtual Patching (El Salvador de Legacy): Todos tenemos ese servidor con Windows 2008 o una App legacy que no se puede parchear hoy. El IDPS actúa como un «parche virtual»: detecta y bloquea el exploit de la vulnerabilidad conocida antes de que toque el SO, dándote tiempo para planificar.
- Cumplimiento Normativo (Compliance): Normativas como PCI DSS o HIPAA exigen explícitamente controles de intrusión. vDefend te permite cumplir esto granularmente sin rediseñar la red física.
- Seguridad para VDI: Los escritorios virtuales son entornos «sucios» por definición. Aplicar IDPS aquí protege al resto del Data Center de lo que tus usuarios puedan traer.
3. Arquitectura: ¿Qué pasa realmente con el paquete?
Para entender el impacto, hay que entender el flujo. El problema de los IDS tradicionales y firewalls físicos es el «hair-pinning»: tienes que sacar el tráfico del host, llevarlo al appliance físico para inspeccionarlo y devolverlo. Eso es ineficiente y complejo de diseñar.
vDefend cambia el juego colocando el control de seguridad directamente en la vNIC de cada máquina virtual.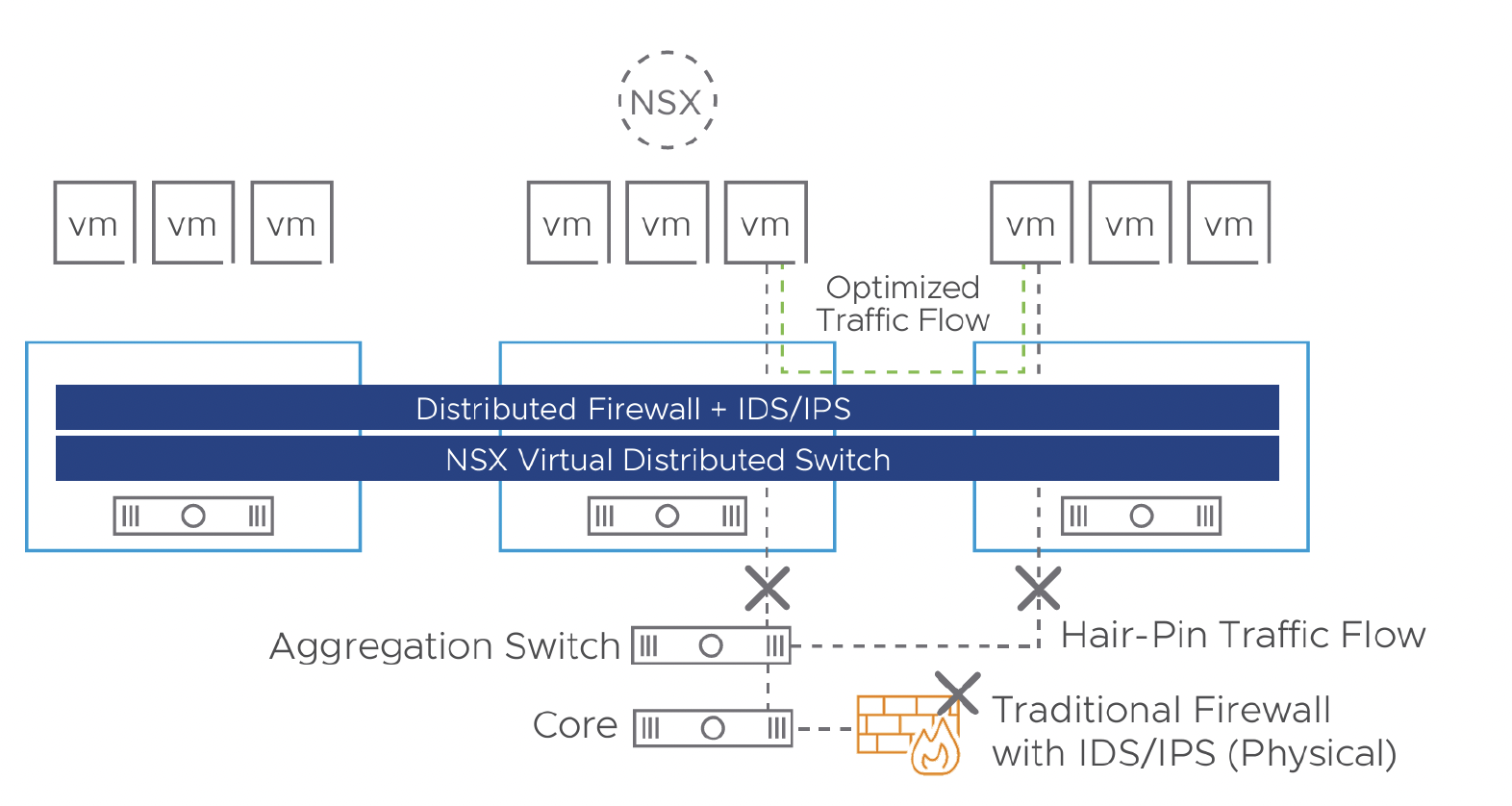
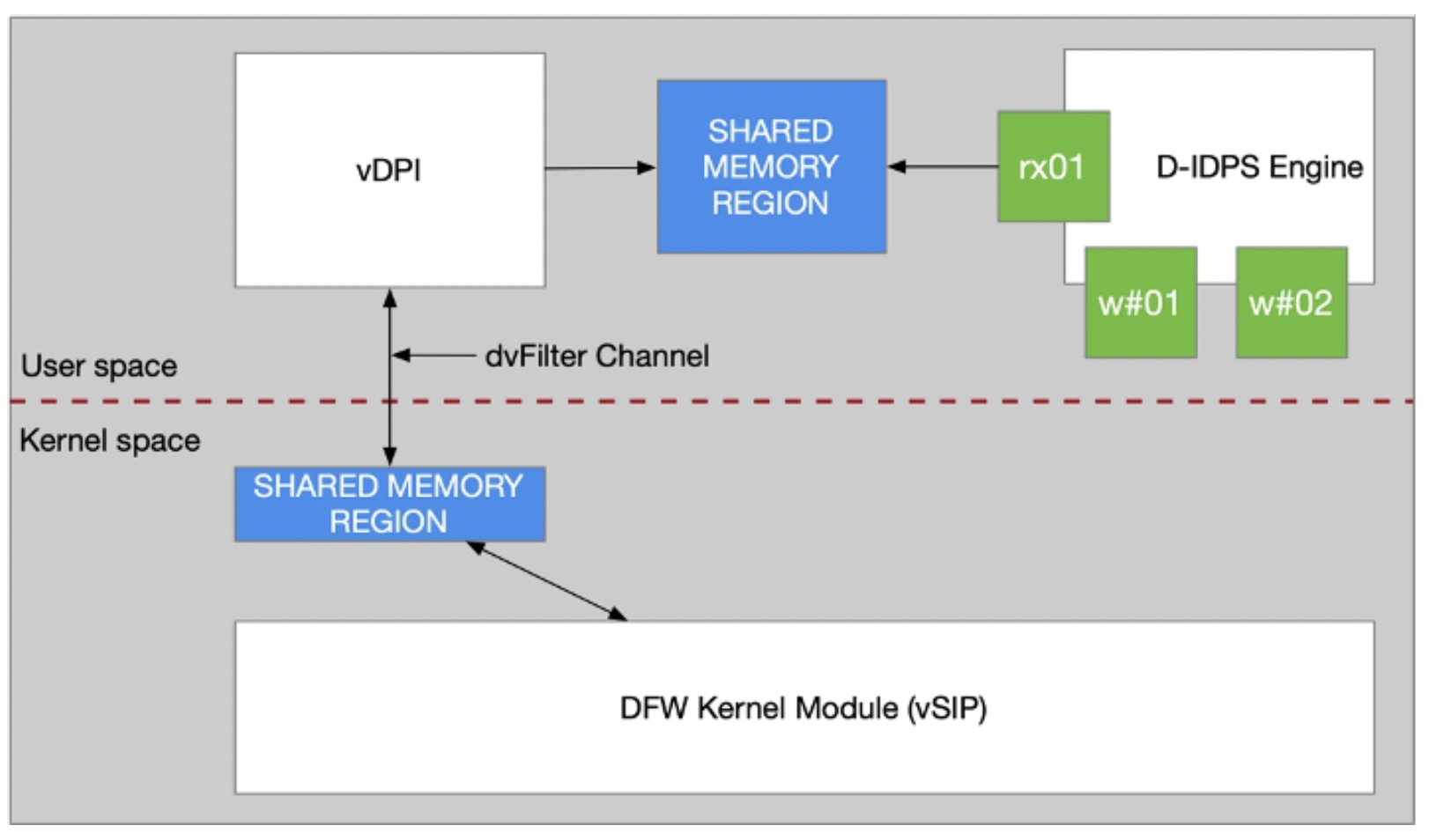
El flujo interno («Under the hood»): El tráfico no se procesa mágicamente. Sigue este camino dentro del host ESXi:
- DFW Primero: El paquete pasa primero por el filtro del Distributed Firewall (vmware-sfw) en el kernel.
- Punt al IDPS: Si el tráfico coincide con una política definida para inspección (una «Inspect Policy»), se marca para ser analizado.
- Memoria Compartida: El paquete se copia a una región de memoria compartida (Shared Memory Region) a través del canal dvFilter.
- User Space Engine: El motor de IDPS (que corre en espacio de usuario, no en kernel) recoge el paquete de ese anillo de memoria, lo analiza con sus worker threads y emite un veredicto.
Nota: Este intercambio entre Kernel y User Space es crítico. Si el motor no vacía el buffer lo suficientemente rápido, los paquetes se descartan silenciosamente.
4. Sizing: Las «Reglas de Oro» de Recursos por Host
Muchos ignoran hasta que tienen problemas. Para que ese motor en User Space funcione, necesitamos reservar recursos físicos del host ESXi. Según la documentación vDefend Distributed IDPS Performance Recommendations, estos son los límites y requisitos que debes respetar:
| Recurso | Requisito | Notas |
|---|---|---|
| CPU | Hasta 5 Cores | Se recomiendan hasta 5 cores adicionales libres por host para los worker y receiver threads. |
| Memoria | 2 GB de RAM | Dato crítico: A partir de la versión 4.1, se reservan 2 GB de memoria del host. Cuidado con el overcommitment en tus clústeres. |
| Red | ~150K PPS | El límite de throughput por host es de aproximadamente 150,000 Paquetes Por Segundo. |
¿Qué pasa si supero el limite? (Bypass vs. Drop)
Si saturas el host (CPU o Red), el sistema entra en modo «Oversubscription». Aquí es vital tener versiones modernas:
- vDefend 4.2.0 + ESXi 8.0u3: Soporta Bypass (dejar pasar tráfico) por CPU, Memoria y Red. Esto evita cortes de servicio ante picos de tráfico.
- Versiones anteriores (3.2.x): No tenían capacidad de bypass y podían causar drops.
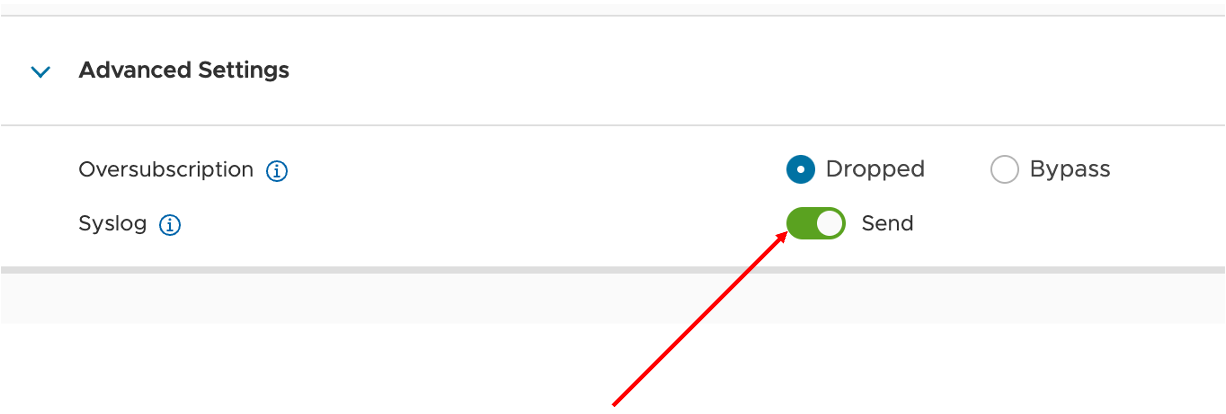
Nota: El sistema puede aplicar este Bypass de forma Global o puedes hacer un override Por Regla.
Nota: No hay granularidad en la causa. Si se satura cualquier recurso (CPU, RAM o Red), la acción seleccionada se ejecuta independientemente de qué recurso esté al límite . Configúralo con sabiduría según tu postura de seguridad.
5. Estrategias de Despliegue
Dependiendo de tus métricas analizadas en el primer paso, tienes dos caminos claros:
a). La Estrategia «No Recomendada pero Útil» (<150K PPS)
Si tus métricas muestran que todos tus hosts están cómodamente por debajo de 150K PPS y sobran CPU/RAM, podrías optar por una política general ANY ANY.

De esta manera tenemos un despliegue rápido para proteger toda la infraestructura (PROD, DEV, QA) organizada por Grupos o Unidades de Negocio, detectando ataques conocidos en tiempo récord. Sin embargo, probablemente vamos a levantar muchos falsos positivos y vamos a desperdiciar el recurso IDPS.
b). La Estrategia Quirúrgica (Hosts Saturados o Críticos)
Si tienes mucho tráfico, aplica ingeniería de precisión usando perfiles personalizados:
Perfiles por S.O.: No uses el mismo perfil para todo. Crea un perfil de firmas específico para Windows, otro para Linux o incluso para aplicaciones específicas (ej. Apache, SQL).
De esta manera reducimos la carga de inspección y eliminamos falsos positivos irrelevantes (ej. no buscar vulnerabilidades de Linux en un servidor Windows).
6. Optimización del IDPS
Para no quemar CPU a lo tonto, sigue estos principios al definir tu política:
- El Mandamiento Supremo: «Apply To»: Nunca dejes esto en «Distributed Firewall». Usa siempre Grupos. Limita el scope para que el motor solo se instancie en las vNICs de las VMs miembro del grupo.
- Direccionalidad Inteligente: El IDPS puede inspeccionar IN, OUT o ambos. A veces, inspeccionar ambos es un desperdicio si el tráfico ya pasó por el motor.
Define bien si inspeccionas la entrada o la salida para ahorrar recursos según el flujo de la aplicación. - Excluye Backups y Tráfico Pesado: El tráfico de alto volumen como SMB o Backups suele superar los límites de PPS y aporta poco valor de inspección.
- Tuning de Protocolo (IPv6): Si tus servidores solo hablan IPv4, configura la regla en el FW Distribuido o Gateway Firewall para que el protocolo sea explícitamente IPv4. Si dejas IPv6 habilitado (que muchos SO traen por defecto), estarás enviando tráfico basura al motor.
- Usa Tags y Grupos: Olvídate de las IPs estáticas. Usa Tags (
Scope: Zone,Tag: DMZ) para que las reglas se apliquen dinámicamente a las cargas de trabajo correctas.
7. Day 2: Operaciones y Troubleshooting
Una vez implementado, hay que operarlo. Aquí mis recomendaciones para el «Día 2».
Gestión de Perfiles (Profiles) No actives todas las firmas a lo loco.
- Empieza filtrando solo por severidad «Critical» y «High».
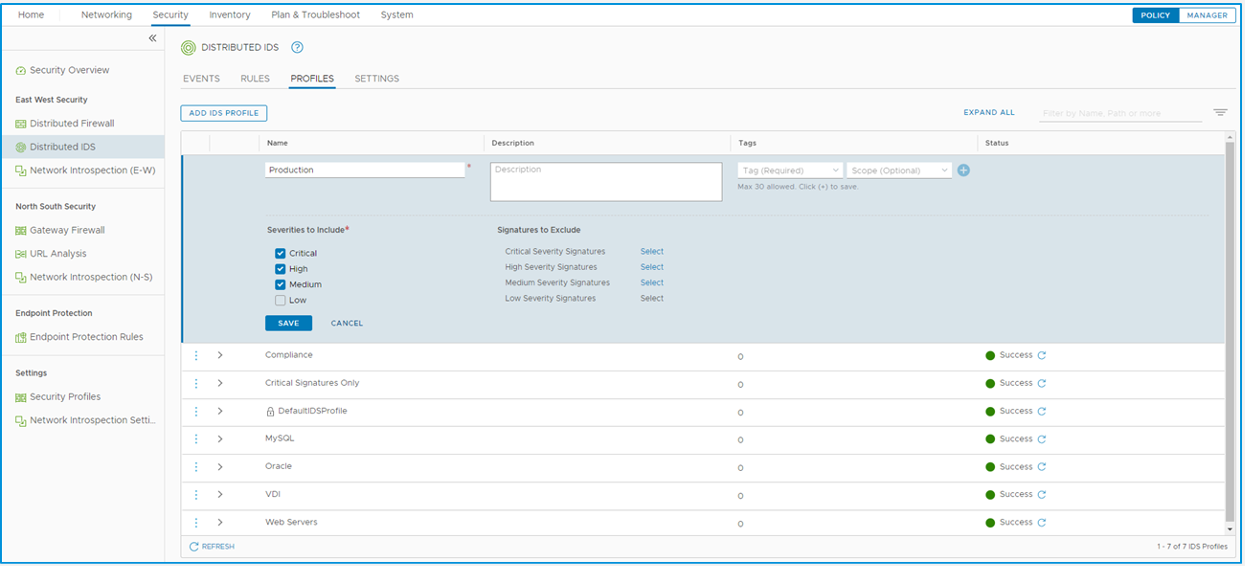
- Empieza siempre en modo Detect Only (solo alerta). Pasa a Detect & Prevent (bloqueo) solo después de validar que no hay falsos positivos.
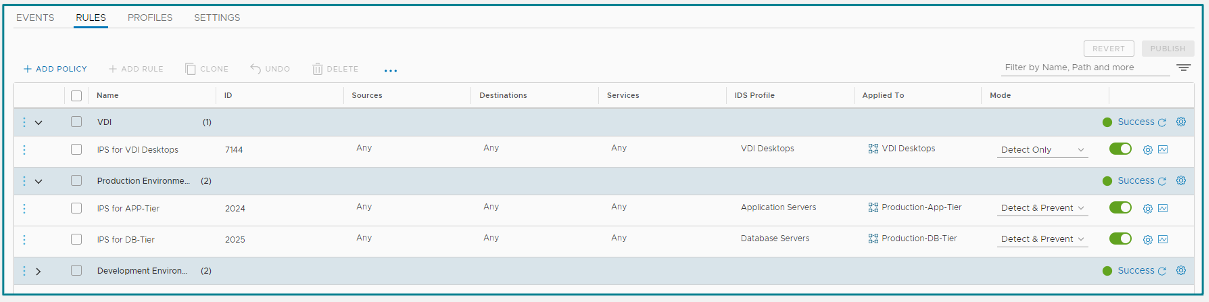
- TIP: Cuando pases a Detect & Prevent mode, debes asegurarte de cambiar ademas el comportamiento de la acción, de firmas involucradas en el evento, de
AlertaRejectoDrop. Algunas firmas vienen configuradas con su acción por default enAlert, de manera que aunque cambies a Detect & Prevent no bloquearás tráfico a menos que cambies el comportamiento de la acción.
- Comenzar con un perfil de cobertura amplia y una amplia aplicación.
• Por ejemplo, CVE: > 7.0.
• Por ejemplo, Attack-Target: Client-Endpoint, Server and Client for EUC. - Opcionalmente, con el tiempo, incluir solo las firmas relevantes en un perfil y aplicarlo a cargas de trabajo específicas.
• Attack target: servidor DNS, servidor AD, servidor web.
• Affected product - Recuerda que tienes un límite de perfiles disponibles dependiendo de las version de NSX. NSX 4.2.3 Configuration Limits
Log Forwarding: Si envías logs a un SIEM (como Splunk), asegúrate de configurar el Syslog sobre TCP.
Si usas UDP, el paquete se limita a 400 Bytes. Un log de IDPS suele ser más largo, así que se cortará y perderás la mitad de la información del ataque.
Comando de Pánico para Troubleshooting ¿Sospechas que estás tirando paquetes por falta de CPU o Memoria? Entra por SSH al host ESXi y lanza este comando:
vsipioctl getdpiinfo -sFíjate en el contador packets_freed_in_error. Si es mayor que 0 (ej. >500-1000), estás teniendo problemas de pérdida de paquetes por saturación del buffer o falta de CPU.
8. Day 2: Firmas y Ciclo de Vida
El IDPS no es «Dispara y olvida». Debes garantizar que la base de datos de firmas este actualizada.
Actualizaciones de firmas del vDefend Threat Intelligence Service (vTIS): Las firmas son el corazón del sistema. Las versiones recientes de NSX buscan actualizaciones automáticamente cada cuatro horas. Si la firma está en tu perfil, la actualización aplica inmediatamente.
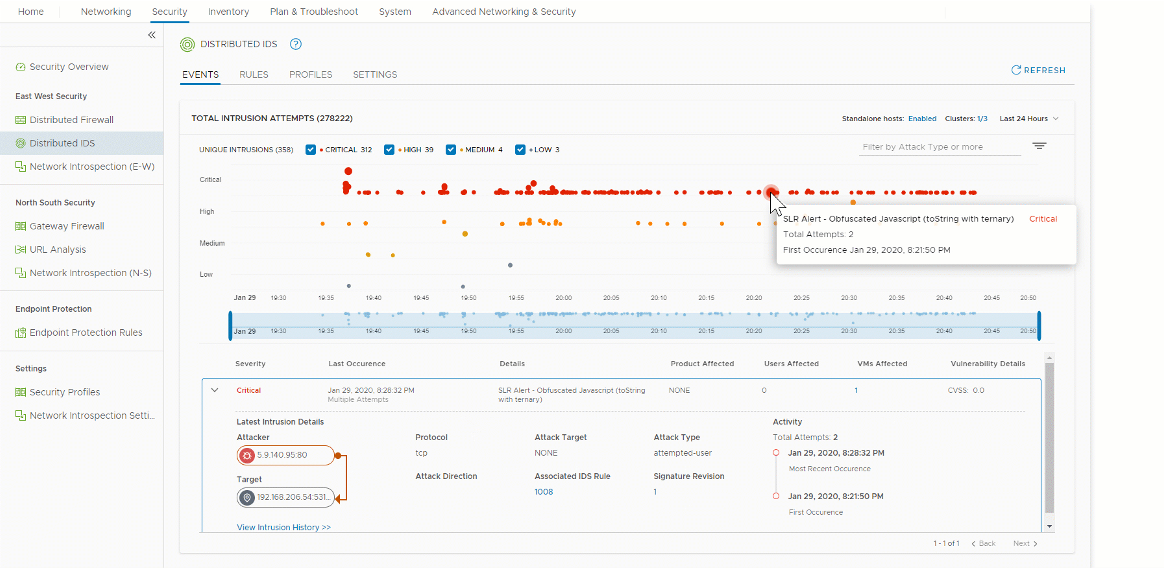
9. Testear el funcionamiento del IDPS
Una vez hemos creados los perfiles y aplicadas las reglas de IDPS, podemos esperar a la ocurrencia de eventos maliciosos o usar metodologias de Testeo similares a EICAR test para A/V.
Estos test generaran alertas. Sin embargo, ningún contenido malicioso es descargado al cliente que solicita el payload, pero si generan los eventos en el IDPS que nos permiten verificar el funcionamiento de la solución.
Conclusión
Operacionalizar vDefend IDPS no se trata solo de encender un switch; requiere planificación. Conocer sus aplicaciones y flujos de tráfico es el 90% del éxito. Si siguen estas prácticas, especialmente el cuidado con los límites de PPS y el diseño de políticas específicas, podrán asegurar sus cargas de trabajo críticas sin sacrificar el rendimiento.
¡IMPORTANTE! He migrado blog del dominio nachoaprendevirtualizacion.com a nachoaprendeit.com. Si te ha servido este artículo deja tu buen Like y compártelo con tus colegas, estas aciones me ayudarán a optimizar los motores de búsqueda para llegar a más personas, y a motivarme a seguir compartiendo este tipo de artículos.

TODOS LOS NOMBRES DE VMS USADOS EN ESTE BLOG SON INVENTADOS Y OBEDECEN A UN AMBIENTE DE LABORATORIO PROPIO, UTILIZADO PARA FINES DE ESTUDIO.
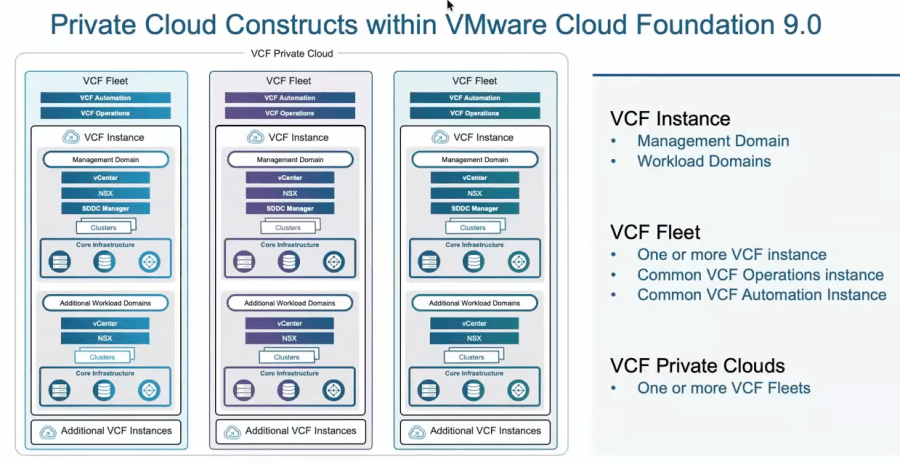
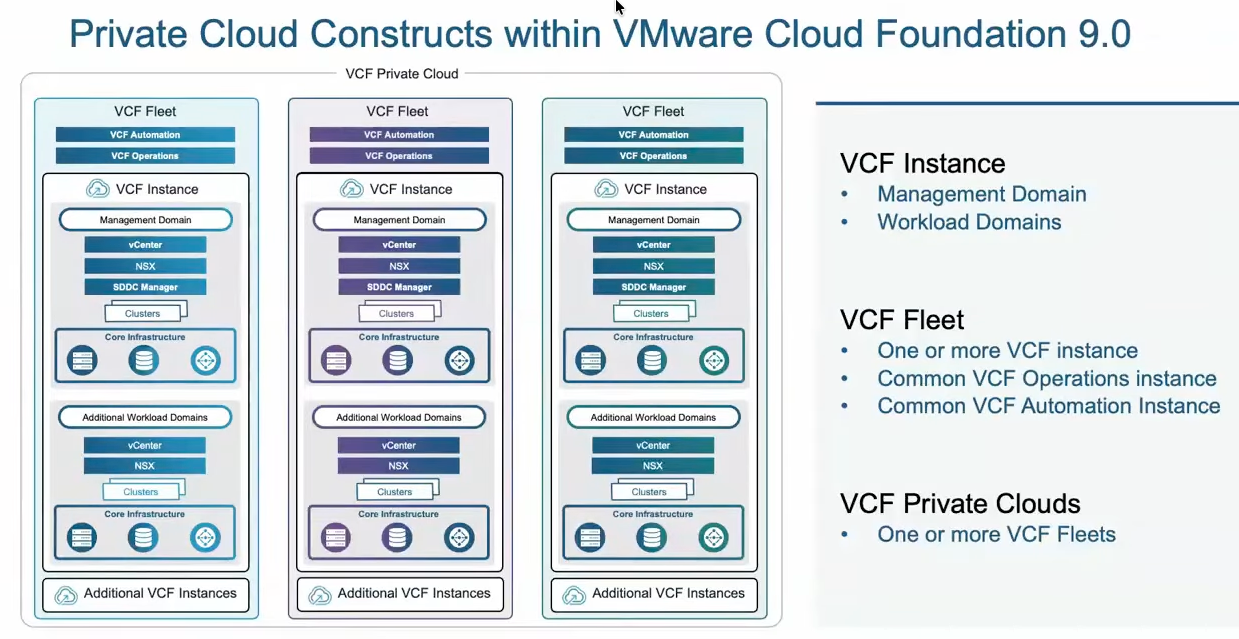



































































 Now we will choose the context that has our napp deployment, which should be
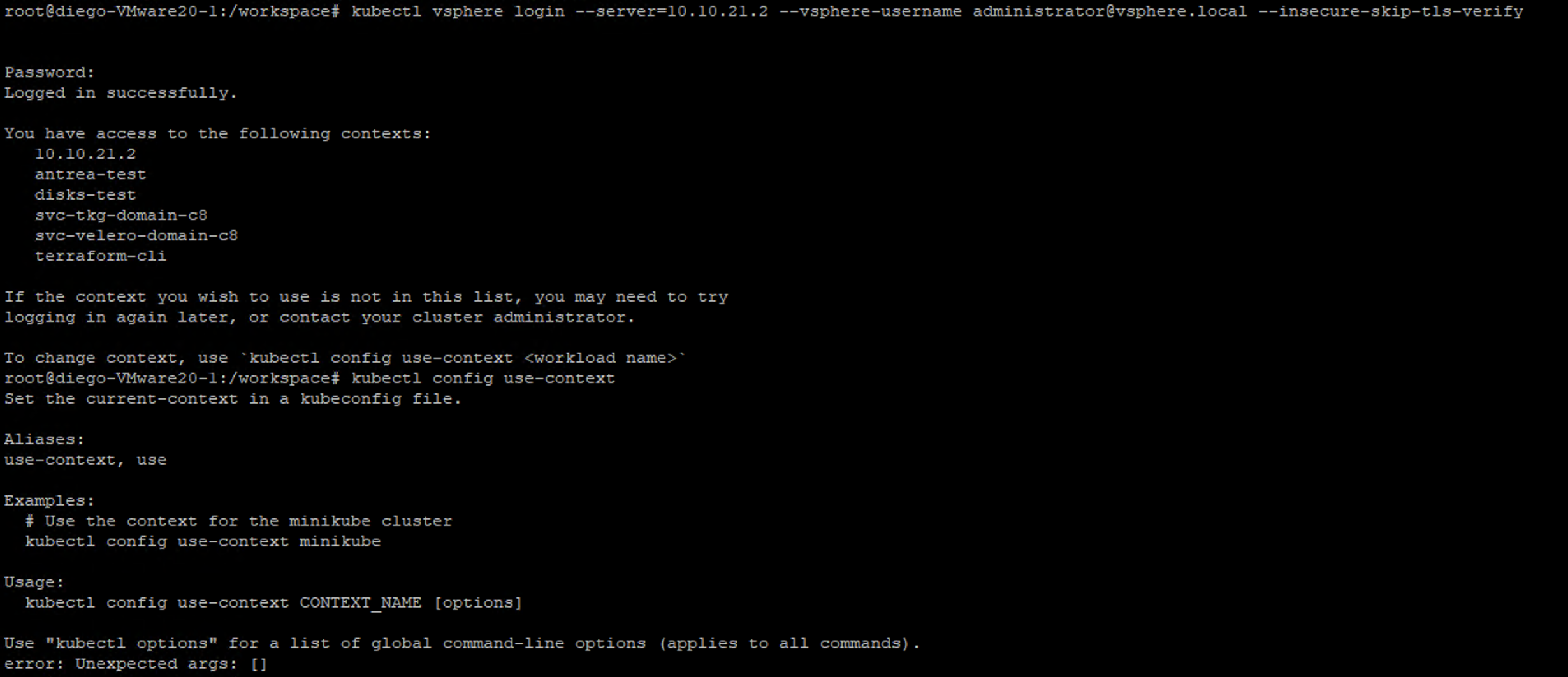
Now we will choose the context that has our napp deployment, which should be 



 Repeat the steps for the following images that will be the gradual jumps:
Repeat the steps for the following images that will be the gradual jumps: Now if we run the command
Now if we run the command